







 本文探讨了机器学习(ML)系统所特有的技术债务问题,包括边界侵蚀、纠缠、隐藏反馈循环等。这些系统往往需要复杂的周边基础设施,且随着外部世界变化产生持续维护成本。提出重构代码、改进数据依赖管理、应对反馈循环和配置债务等偿还策略。同时,强调了测试、可再生性、流程管理和文化债务的重要性,以促进ML系统的长期稳定和效率。
本文探讨了机器学习(ML)系统所特有的技术债务问题,包括边界侵蚀、纠缠、隐藏反馈循环等。这些系统往往需要复杂的周边基础设施,且随着外部世界变化产生持续维护成本。提出重构代码、改进数据依赖管理、应对反馈循环和配置债务等偿还策略。同时,强调了测试、可再生性、流程管理和文化债务的重要性,以促进ML系统的长期稳定和效率。
主要思想:机器学习有传统代码需要维护的问题和机器学习特定的问题,这些特定的问题是系统层面的:
边界侵蚀(boundary erosion)、纠缠(entanglement)、隐藏反馈循环(hidden feedback loops)、未申明的访问者(undeclared consumers)、数据依赖(data dependencies)、配置问题(configuration issues)、外部世界变化(changes in the external world)、系统层面的反面模式(anti-patterns)
1.引言
在本文中,我们认为ML系统具有承担技术债务的特殊能力,因为它们具有传统代码的所有维护问题以及一组额外的ML特定问题。
主要通过以下方式进行逐渐偿还:
重构代码(refactoring code)、改进单元测试(improving unit tests)、删除无用代码(deleting dead code)、降低依赖(reducing dependencies)、精简应用程序接口(tightening APIs)、改进说明(improving documentation)
本文不提供新的ML算法,而是试图提高大家对长期实践中必须考虑权衡的认识。
2.复杂模型侵蚀边界
传统的软件工程实践表明,使用封装和模块化设计的强大抽象边界有助于创建可维护的代码,在这些代码中很容易进行单独的更改和改进。
不幸的是,通过规定特定的预期行为,很难对机器学习系统实施严格的抽象边界。
详细介绍了相关的问题并总结相应的改善措施,例如。
/1 纠缠
例如输入信号的特征相关纠缠,动一个则其他的都动
不能像传统软件设计一样进行封装和模块设计
/2 嵌套修正
适应新情况,但会依赖旧系统
需要扩充旧系统的情况,或者单独创造一个新的模型,但成本高
/3 未声明的访问者
可见性债务
进行限制访问或者服务级别协议
3.数据依赖
/1 不必要的数据依赖
例如遗留下来的特性,但是添加后续的特性进去,该特性还没有被移除
捆绑的特性,作为一组添加进去,但其实其中一个作用很小
/2 未充分利用的数据依赖关系
精度:提高模型精度
相关特性:两个特性强关联,甚至选择关键特性的时候选择了关联性小的那个
所以应该及时进行评估和删除
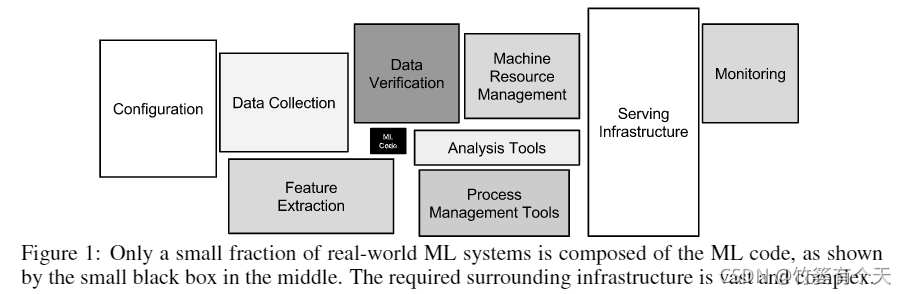
只有一小部分真实世界ML系统由ML代码组成,如中间的小黑箱所示。所需的周边基础设施庞大而复杂。
4.反馈循环
live ML系统的一个关键特性是,如果它们随着时间的推移而更新,它们通常会影响自己的行为。
直接的反馈循环:通过使用一定数量的随机化,或通过将数据的某些部分从给定模型的影响中分离出来,可以减轻这些影响。成本高
隐藏的反馈循环:两个系统间接相互影响
5.反面模式
胶水代码:也就是拿别人的代码粘合在一起
因为一个成熟的系统最终可能(最多)是5%的机器学习代码和(至少)95%的粘合代码,所以创建一个干净的本机解决方案而不是重复使用通用软件包的成本可能更低。对抗粘合代码的一个重要策略是将黑盒包封装到通用API中。这使得支持基础架构更易于重用,并降低了更改包的成本。
管道丛林:清除管道丛林和从头开始重新设计的全新方法确实是工程努力的一项重大投资,但可以显著降低持续成本并加快进一步创新。胶水代码和管道丛林是集成问题的症状,这些问题可能是“研究”和“工程”角色过度分离的根本原因。
无用的实验代码路径(定期检查删除)
抽象债务:上述问题突出了一个事实,即明显缺乏支持ML系统的强大抽象。
常见气味:组件或系统中的潜在问题,例如普通旧数据类型、多种语言、经常依赖原型环境
6.配置债务
使用哪些功能、如何选择数据、各种算法特定的学习设置、潜在的预处理或后处理、验证方法等
7.应对外部世界的变化
外部世界很少是稳定的。这种背景变化率会产生持续的维护成本
/1 动态系统中的固定阈值
/2 监控和测试
8.ML相关债务的其他领域
数据测试债务:对输入数据进行一定量的测试对于一个运行良好的系统来说是至关重要的
可再生性债务:我们可以重新运行实验并获得类似的结果,这一点很重要,但由于随机算法、并行学习固有的非确定性、对初始条件的依赖以及与外部世界的交互作用,设计真实世界系统以允许严格的再现性是一项困难的任务
流程管理债务:这引发了一系列重要问题,包括安全自动地更新许多类似模型的许多配置的问题,如何在具有不同业务优先级的模型之间管理和分配资源的问题,以及如何可视化和检测生产管道中数据流中的阻塞。开发工具以帮助从生产事故中恢复也是至关重要的。
文化债务:ML研究和工程之间有时会有一条强硬的路线,但这可能会对长期的系统健康产生反作用。重要的是要创建团队文化,以奖励特征的删除、复杂性的降低、再现性的改善、稳定性的提高以及与准确性改善同等程度的监控。根据我们的经验,这最有可能发生在具有ML研究和工程能力的异构团队中。
9.结论:衡量债务并偿还债务
一种全新的算法方法能在多大程度上进行全面测试?
什么是所有数据依赖项的可传递闭包?
如何准确衡量新变化对系统的影响?
改进一个模型或信号是否会降低其他模型或信号的质量?
团队的新成员能以多快的速度跟上进度?

















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









