






1.简介
DALL-E 2的效果想必大家都已经很清楚了,效果是非常惊人的,该篇文章就是讲一下DALL-E 2的原理是什么。
2.方法
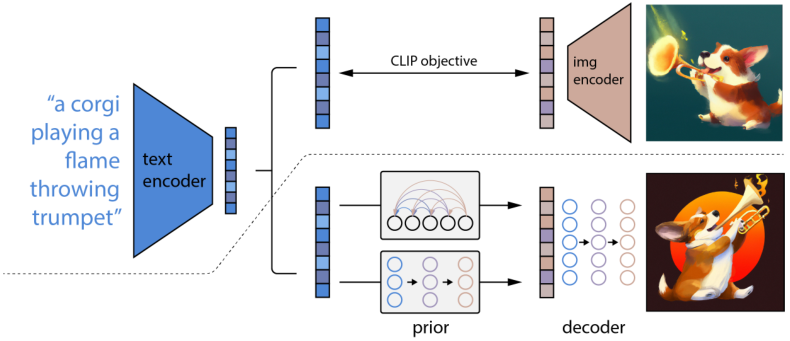
DALL-E 2的原理不难理解,前提是你知道CLIP。简单来说,CLIP是一个由文本和图片多模态训练的一个zero-shot模型。上图中的text encoder和img encoder是CLIP中的原模型没变,参数都没变,一个用来提取文本的特征,一个用来提取图像的特征,他们之间具有一定的映射关系的。
DALL-E 2的训练主要有两步,一个是训练prior先验模型,一个是训练decoder模型。prior先验模型的训练也比较粗暴,首先输入文本,通过编码器提取文本特征,然后通过先验网络预测对应的图像特征,用CLIP中image encoder输出的图像特征作为ground truth进行训练。decoder就是一个扩散模型。
2.1图像生成研究现状
- 第一个就是大名鼎鼎的GAN了。GAN是由一个生成器和一个判别器构成的,生成器通过输入一个高斯分布的随机采样,输出一个生成的图像。将生成的图像和真实的图像输入到判别器当中,输出一个二分类的结果来判断生成的图片是否能够以假乱真。由于GAN的目标函数是以假乱真的,所以生成的图像更加真实,但是GAN因为要同时训练两个网络,所以平衡不好控制,导致训练不稳定,一不小心就训练失败。第二是GAN的优化目标是尽可能真实,所以GAN的多样性不够好。最后,GAN不是一个概率模型,图片的生成都是隐式的,通过网络去完成的,可解释性不强,所以在数学上不好解释。
-
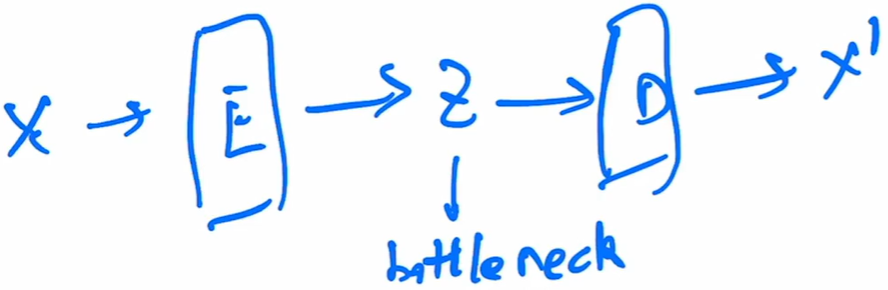
第二是AE了,自编码器能够将输入变换到隐藏向量𝒛,并通过解码器重建(Reconstruct,或恢复)出𝒙。解码器的输出能够完美地或者近似恢复出原来的输入,即𝒙 ≈ 𝒙, 自编码器的优化目标:
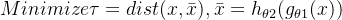 , dist(𝒙, 𝒙)表示 𝒙和的距离度量,称为重建误差函数。 常见的度量方法有欧氏距离的平方,计算方法如下:ℒ = ∑(𝑥𝑖 - 𝑥̅𝑖)2
, dist(𝒙, 𝒙)表示 𝒙和的距离度量,称为重建误差函数。 常见的度量方法有欧氏距离的平方,计算方法如下:ℒ = ∑(𝑥𝑖 - 𝑥̅𝑖)2它和均方误差原理上是等价的。 自编码器网络和普通的神经网络并没有本质的区别, 只是训练的监督信号由标签𝒚变成了自身𝒙。 借助于深层神经网络的非线性特征提取能力, 自编码器可以获得良好的数据表示,相对于 PCA 等线性方法,自编码器性能更加优秀, 甚至可以更加完美的恢复出输入𝒙。
-
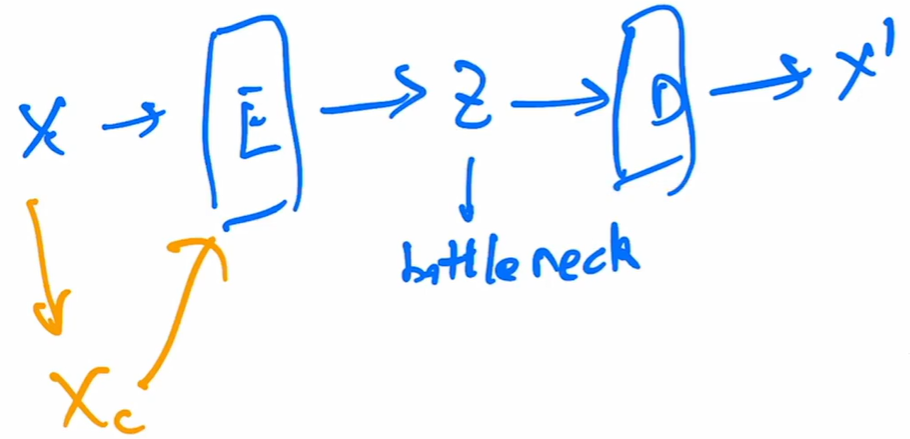
第三是DAE,Denoising Auto-Encoder。由于原始图像冗余性太高,为了使网络学习到图片的本质,防止神经网络记忆住输入数据的底层特征, Denoising Auto-Encoders 给输入数据添加随机的噪声扰动,如给输入𝒙添加采样自高斯分布的噪声𝜀:
,添加噪声后,网络需要从
学习到数据的真实隐藏变量 z,并还原出原始的输入𝒙。
-
不论是AE还是DAE,都是从原始图像中学习提取出特征z的,把特征拿去做分类、检测等任务,并不是一个生成任务,因为网络学习到的只是特征,并不是一个概率分布,我们没法进行采样。z是一个专门用来重建图像的特征,并不是一个随机噪声。这时候就出现了VAE。
-
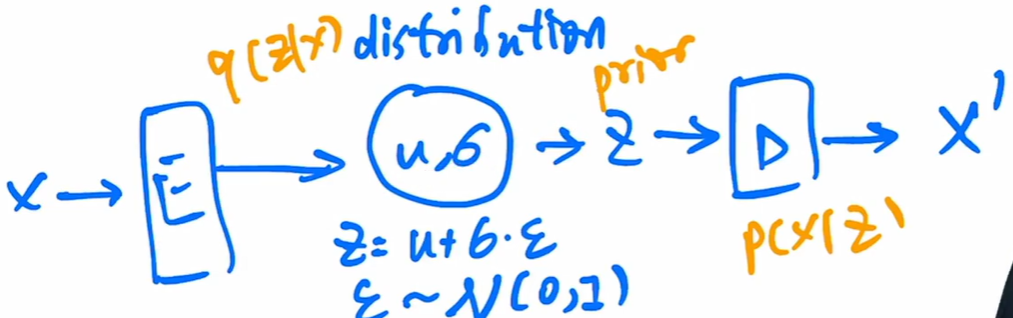
变分自编码器VAE和之前的编码器是截然不同的,虽然都是输入图像重建图像,但是VAE学习的是一个分布而不是特征。VAE假设这个分布是高斯分布,可以用均值和方差来描述。输入图像通过编码器提取特征,然后接FC层,预测出均值和方差,然后通过 z = μ + σ⊙ε 公式得到z,最后通过解码器生成图像。预测时只需要从高斯分布里采样一个噪声通过解码器就能够生成出图像了,因为学习的是一个分布,所以生成图片的多样性非常好。
-
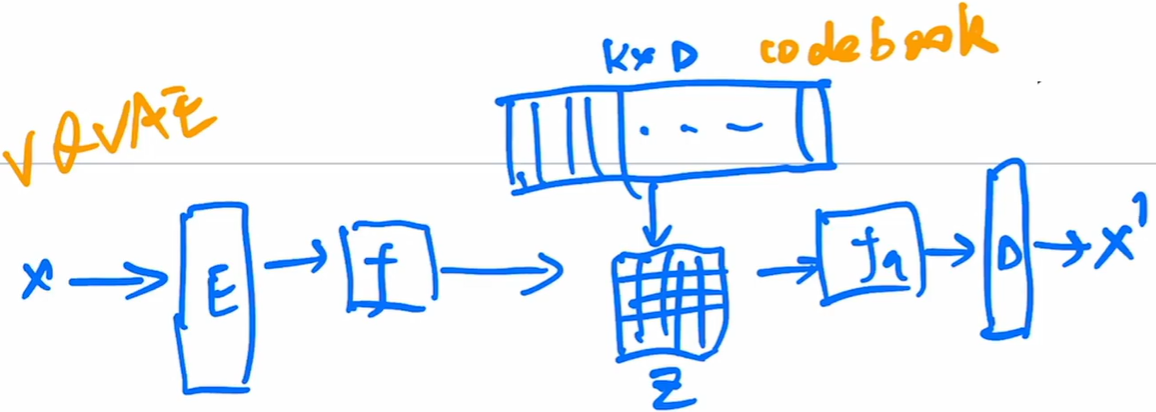
接下来是VQ-VAE和VQ-VAE2了,他们虽然听起来和VAE密切相关,但实际上和AE更加相似。它是通过形成上千的codebook聚类中心,而不是概率分布,所以多样性稍差。
-
最后是近几年火爆的扩散模型了。扩散模型的原理简单来说就是前向加噪和反向去噪的过程。先使用原图一步步的加入高斯噪声,当步数足够大时图片就近似于一个高斯分布了。然后再用共享参数的神经网络,比如U-Net来一步步去噪生成图片。扩散模型的发展史也是非常精彩的,原始的扩散模型是通过Xt预测出Xt-1,但是因为预测的是一个图像,所以非常的难,而且因为要在神经网络上forward上百次,所以速度也是非常慢的。
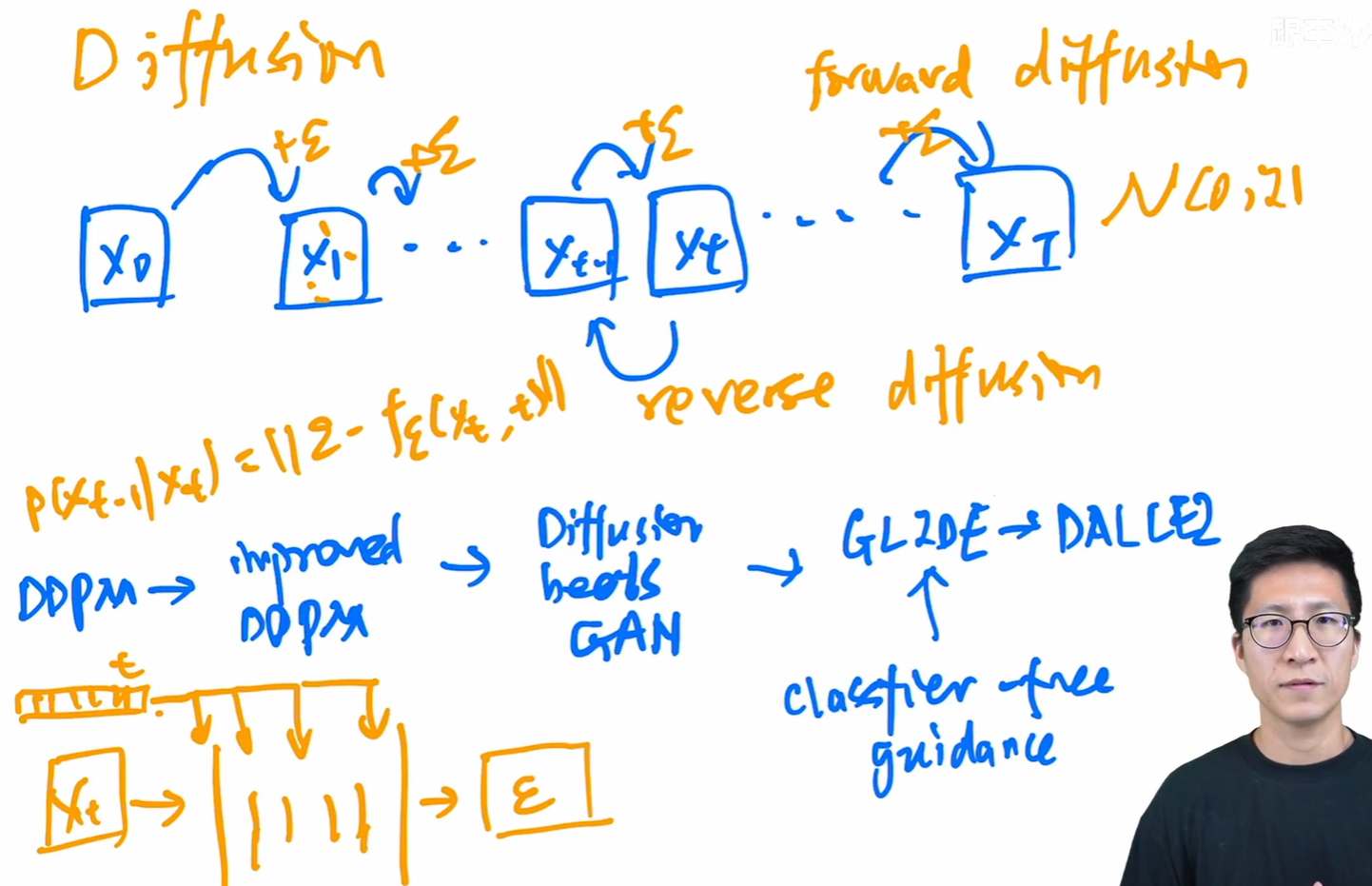
-
这时DDPM论文发表一定程度上解决了一些难题。第一个贡献是将Xt预测出Xt-1改为预测Xt到Xt-1所去掉的噪声了,这样大大减小了预测难度。并且DDPM还在U-Net的输入中加入了一个time embedding,这样可以网络知道目前到了反向扩散的第几步了,这样避免了因为U-Net的共享参数导致生成的图像质量不好的问题,让网络在反向扩散前期注重整体,后期注重细节。网络的目标函数就是p(Xt-1|Xt)=||ε-f(Xt,t)||。其中ε是在正向扩散过程中加入的噪声(已知的),f是U-Net网络,Xt是该时刻图像,t是该时刻的time embedding。DDPM第二个贡献是想要预测高斯分布,只需要预测均值和方差就可以,并且方差也不需要,常数就可以,这样大大减少了训练难度。
-
随后在DDPM的基础上又提出了improved DDPM。主要改进是不止预测均值,也会预测方差。第二个改进是在添加的噪声上的改进,从原来线性的schedule改为了余弦的schedule。
-
随后Diffusion beats GAN发表了。用了更大的模型,加入了注意力机制等等。主要贡献是用了classifier guidance的方法引导模型采样和生成。classifier guidance就是在训练模型的同时再训练一个图像分类器,输入Xt的有噪声的图像,算交叉熵目标函数,对该图像进行分类,得到对应的梯度,最后用梯度指导网络从Xt预测Xt-1。p(Xt-1|Xt)=||ε-f(Xt,t,y)||,其中y是指导信息。不过这一系列方法都需要单独再去训练一个分类器,比较麻烦,于是又有人提出了classifier free guidane模型,不需要再去训练一个分类器,不过需要模型输出两个值,一个是加y的,一个是不加y的,来找两个之间的映射关系。随后的GLIDE和DALL-E2也用了这种方法。

2.2Decoder模型
DALL-E2的decoder模块其实就是CLIP guidance的GLIDE扩散模型,也用了classifier-free guidance方法。然后加入了一个级联式的形式,先生成64x64的图像,然后训练一个网络上采样成256x256的图像,再训练一个网络上采样成1024x1024的图像。
2.3prior模型
作者主要用了两种方法训练prior模型,两个方法都用了classifier-free guidance方法。一种是自回归模型,也就是和CLIP相似,通过文本特征自回归直接预测图像特征,但是这样效率会比较低。第二种是diffusion prior方法,主要用了Transformer decoder的结构。输入文本、CLIP提取的文本特征、time step的embedding、加入噪声后的CLIP的图像特征、cls token,这些embedding被拿去预测没有加噪声的CLIP图像特征,整体流程和扩散模型相似,不过这里不是去预测噪声,而是预测图像特征z。
3.局限性
DALL-E2还是有很多局限性的,比如在生成图像时不能很好的将物品和他的属性结合起来。作者认为是由于其中应用了CLIP模型的原因,CLIP在训练时只考虑文本和图像的相似性,只要相似性高就能匹配,这样其实对于文本和图像的本质理解是有偏差的。还有就是当你想生成一个复杂场景时,很多细节DALL-E2是生成不出来的。

在twitter上还有人发现DALL-E2其实是有自己的一套语言的。比如你输出文本“两个鲸鱼讨论食物,并且图中有字幕”,这时DALL-E2真的会生成带有字幕的图像,但是他的字幕是完全看不懂的字符。但是当我们将这些字符复制下来输入给DALL-E2时,真的会生成食物的图像,说明DALL-E2在训练过程中对文本的理解产生了一定的偏差。


















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









