









AIGC系列博文:
【AIGC系列】1:自编码器(AutoEncoder, AE)
【AIGC系列】2:DALL·E 2模型介绍(内含扩散模型介绍)
【AIGC系列】3:Stable Diffusion模型原理介绍
【AIGC系列】4:Stable Diffusion应用实践和代码分析
【AIGC系列】5:视频生成模型数据处理和预训练流程介绍(Sora、MovieGen、HunyuanVideo)
【AIGC系列】6:HunyuanVideo视频生成模型部署和代码分析
这里写目录标题
1 引言
OpenAI在2021年1月推出了DALL·E,并于该年底推出GLIDE,时隔一年又在2022年4月推出DALL·E2。相比 DALL·E ,DALL·E2 可以生成更真实和更准确的画像:综合文本描述中给出的概念、属性与风格等三个元素,生成现实主义图像与艺术作品,分辨率更是提高了4倍。
DALL·E2有以下几个功能:
- 根据文本直接生成图片:可以根据文本描述生成原创性的真实图片(因为模型将文本和图片的特征都学的非常好),它可以任意的去组合这些概念、属性或者风格。
- 扩展图像:可以将图像扩展到原始画布之外,创造出新的扩展构图。
- 根据文本编辑图片:可以对已有的图片进行编辑和修改,添加和删除元素,同时考虑阴影、反射和纹理。
- 生成不同变体:给定一张图片,可以生成不同的变体,并保持原风格(不需要文本)。
- 高分辨率:相比DALL·E ,给定同样的文本,DALL·E2可以生成4倍分辨率的图片。
DALL·E2没有开源,也没有release模型,但是GitHub上有一个相关的开源项目,Boris Dayma等人根据论文创建了一个迷你但是开源的模型Dall·E Mini,只是训练集和模型都比较小,生成的质量会差一些。可以直接上打开github主页上提供的colab跑一跑,或者是huggingface的spaces dalle-mini里面使用。
GitHub:dalle-mini
dalle-mini官网:https://www.craiyon.com/
colab代码:client.ipynb
模型总览图如下,上面一部分是CLIP,下面一部分是DALL·E2。
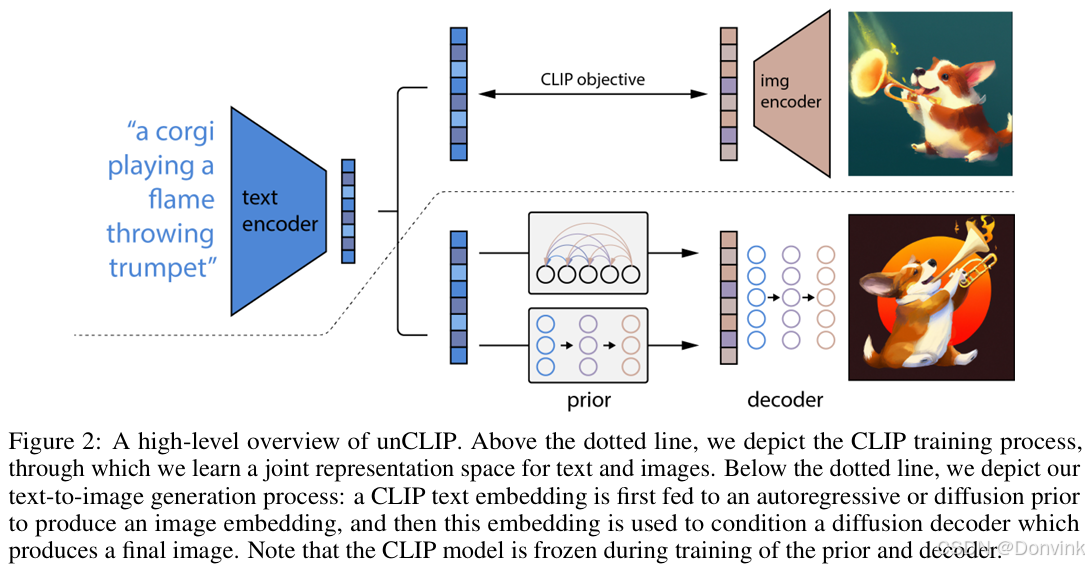
CLIP的详细介绍请参考博文:【CLIP系列】1:CLIP【多模态领域开山之作】
上部分的CLIP训练好之后,将其冻住,不再参与任何训练和微调。DALL·E2训练时,输入也是文本-图像对,主要是两阶段训练:
- prior:根据文本特征生成图像特征
- 文本和图片分别通过锁住的CLIP text encoder和CLIP image encoder得到编码后的文本特征和图片特征。
- prior模型的输入就是上面CLIP编码的文本特征,其ground truth就是CLIP编码的图片特征,利用文本特征预测图片特征,就完成了 prior的训练。
- 推理时,文本还是通过CLIP text encoder得到文本特征,然后根据训练好的prior得到类似CLIP生成的图片特征(此时没有图片,所以没有CLIP image encoder这部分过程)。此时图片特征应该训练的非常好,不仅可以用来生成图像,而且和文本联系的非常紧(包含丰富的语义信息)。
- decoder:常规的扩散模型解码器,解码生成图像。
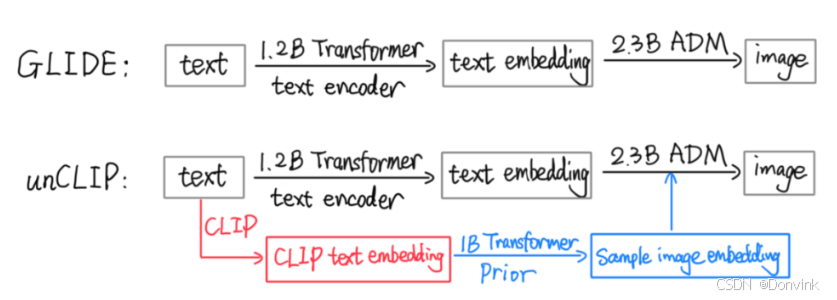
- 这里的decoder就是升级版的GLIDE,所以说DALL·E2 = CLIP + GLIDE,如下图所示:
2 扩散模型
简单来说,扩散模型包含两个过程:前向扩散过程(forword)和反向生成过程(reverse):
- 前向扩散过程:对数据逐渐增加高斯噪音直至数据变成随机噪音的过程(噪音化)。
- 反向生成过程:从随机噪音开始逐步去噪音直至生成一张图像(去噪)。
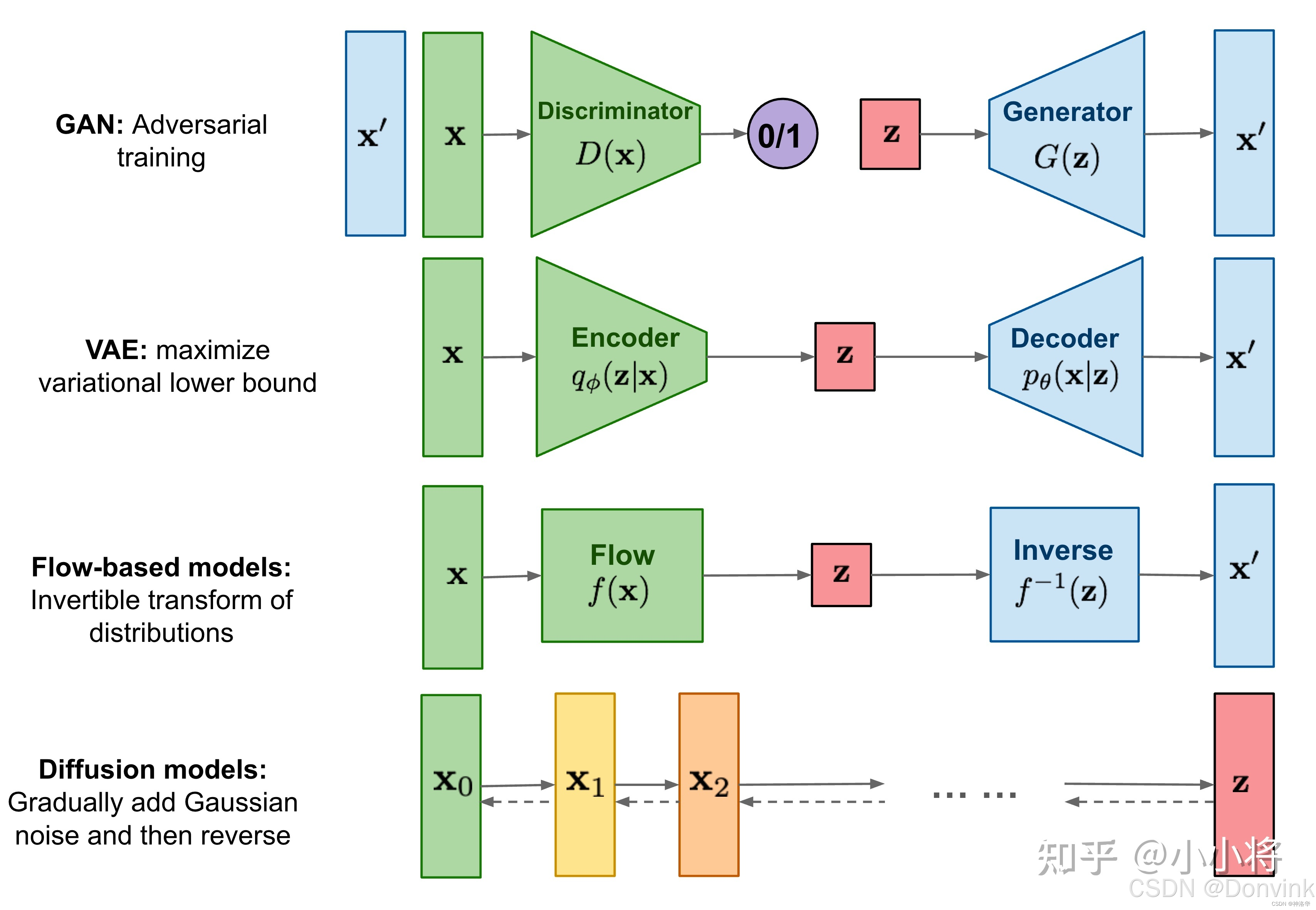
扩散模型与其他主流生成模型对比如下:
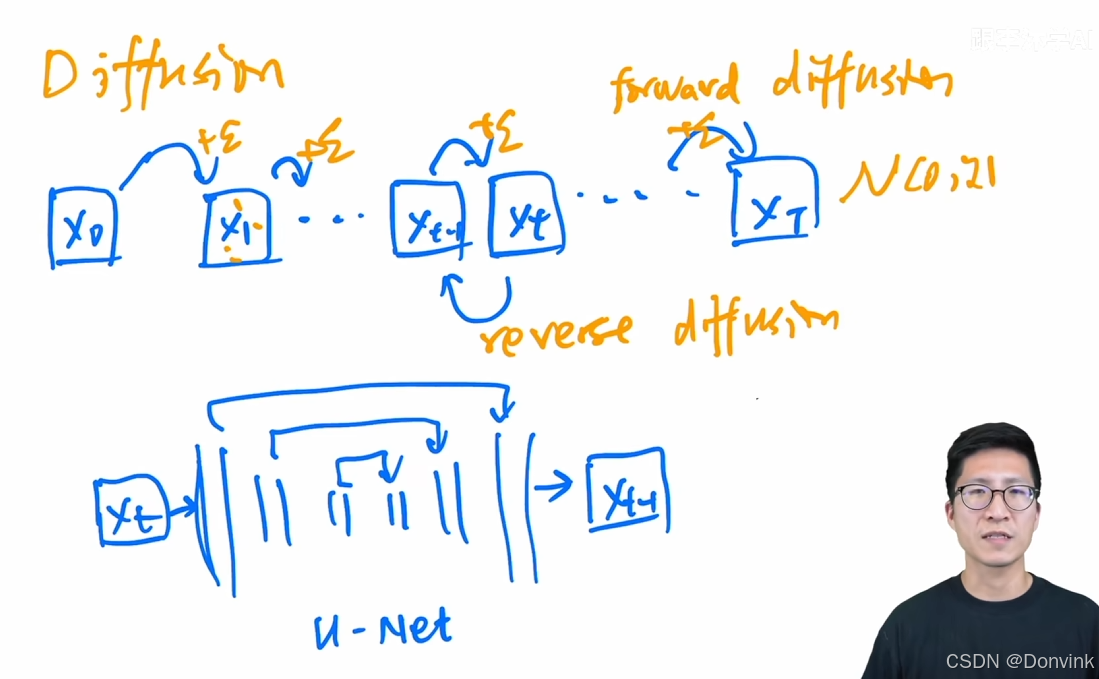
结合下面这张图我们具体来理解一下扩散模型的前向和逆向过程。
具体而言,假设有一张正常的图片X0,往这张图片里添加噪声,得到了X1,接着再往X1里添加噪声ε,再添加,每一步都添加一个很小的正态分布的噪声ε,一直加到最后,总共加了T次,如果这个T特别大,接近于无穷大,那么最终图片会变成一个真正的噪声,变成了正态分布 N(0, 1),即各向同性的正态分布。整个过程就叫做forward diffusion。
我们把前面的过程反过来,假如现在的输入是一个随机噪声XT,如果我们能找到一个函数,或者训练一个模型,能够把图像一步一步地恢复过来,恢复到最初的这个图片,就可以做图像生成任务了。我们随机抽样一个噪声,XT或者之前的任意一步Xt,训练一个模型把它从Xt变成Xt-1,然后再用同样的模型把Xt-1变成Xt-2,一步步倒退回去,所有步使用的模型都是共享参数的,即同一个模型,只需要抽样生成很多次。这个过程叫做reverse diffusion。
这也是扩散模型的不足之处,训练上比其他模型更贵一些,推理时也更慢一些,因为像GAN,只要训练好模型了,输入一个噪声,一次模型forward就能输出最终图片结果。但是对于扩散模型来说,一般T是1000步,即需要做1000次forward。
reverse diffusion通常采用一个常见的模型结构——U-Net,U-Net是一个CNN网络,先用编码器一点点把图片压缩变小,再用一个解码器一点一点把图像恢复回来,输入输入图像尺寸相同。为了让恢复做得更好,U-Net里还有一些skip connection,直接把信息从前面推过来,这样能恢复一些细节。后来也有一些改进,例如给U-Net里增加一些attention的操作,会让图片生成变得更好。
具体公式表示如下:
- 前向过程
- t 时刻的分布等于 t-1 时刻的分布+随机高斯分布的噪音,其中α是噪音的衰减值:
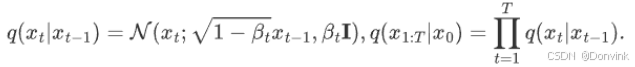
- 任意时刻的分布 Xt ,都可以通过 X0初始状态,以及步数计算出来:
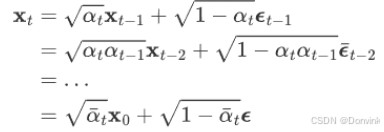
- 逆向过程
- 已知 Xt,求初始状态的 X0,这里利用贝叶斯公式来预测 X0,已知 Xt 的分布求 Xt-1时刻的分布:

3 DDPM
DDPM(Denoising Diffusion Probabilistic Models)是2020年6月发表的,其对原始的扩散模型做了一定的改进,使器优化过程更加的简单。DDPM第一次使得扩散模型能够生成很好的图片,算是扩散模型的开山之作。主要来说,DDPM有两个重要的贡献:
- 从预测转换图像改进为预测噪声
-
作者认为每次从 Xt预测Xt-1,直接预测图像到图像的转化不太好优化,所以考虑直接去预测每一步所添加的噪声ε,这样就简化了问题。
-
这种操作就有点类似ResNet的残差结构。每次新增一些层,模型不是直接从 x 去预测 y(这样比较困难),而是让新增的层去预测( y − x )。这样新增层不用全部重新学习,而是学习原来已经学习到的 x 和真实值 y 之间的残差就行。
-
目标函数:

-
time embedding
- U-Net模型输入,除了当前时刻的xt,还有一个输入time embedding(类似transformer里的位置编码),主要用于告诉 U-Net模型,现在到了反向过程的第几步。
- time embedding的一个重要功能就是引导U-Net生成。U-Net的每一层都是共享参数的,那怎样让其根据不同的输入生成不同的输出呢?因为我们希望从随机噪声开始先生成大致轮廓(全局特征),再一步步添加细节生成逼真的图片(局部特征,边边角角)。这个时候,有一个time embedding可以提醒模型现在走到哪一步了,我的生成是需要糙一点还是细致一点。所以添加time embedding对生成和采样都很有帮助,可以使模型效果明显提升。
- xt和time embedding可以直接相加,拼接或者是其它操作。
- 只预测正态分布的均值
- 正态分布由均值和方差决定。作者在这里发现,其实模型不需要学方差,只需要学习均值就行。逆向过程中高斯分布的方差项直接使用一个常数,模型的效果就已经很好。所以就再一次降低了模型的优化难度。
4 Guidance
4.1 classifier guidance
扩散模型采样和生成图片非常的慢,所以作者考虑如果有一种额外的指导可以帮助模型进行采样和生成就好了。于是作者借鉴了之前的一种常见技巧classifier guided diffusion,即在反向过程训练U-Net的同时,也训练一个简单的图片分类器。这个分类器是在ImageNet上训练的,只不过图片加了很多噪声,因为扩散模型的输入始终是加了很多噪声的,跟真实的ImageNet图片是很不一样的,所以是从头训练的。
当采样xt之后,直接扔给分类器,就可以看到图片分类是否正确,这时候就可以算一个交叉熵目标函数,对应的就得到了一个梯度。之后使用分类器对xt的梯度信息指导扩散模型的采样和生成。这个梯度暗含了当前图片是否包含物体,以及这个物体是否真实的信息。通过这种梯度的引导,就可以帮助U-Net将图片生成的更加真实,要包含各种细节纹理,而不是意思到了就行,要和真实物体匹配上。使用了 classifier guidance之后,生成的效果逼真了很多,在各种inception score上分数大幅提高。
除了最简单最原始的classifier guidance之外,还有很多其它的引导方式。
- CLIP guidance:将简单的分类器换成CLIP之后,文本和图像就联系起来了。此时不光可以利用这个梯度引导模型采用和生成,而且可以利用文本指导其采样和生成。(原来文生图是在这里起作用)
- image侧引导:除了利用图像重建进行像素级别的引导,还可以做图像特征和风格层面的引导,只需要一个gram matrix就行。
- text侧:可以用训练好的NLP大模型做引导。
以上所有引导方式,都是下面目标函数里的y yy,即模型的输入不光是xt和time embedding,还有condition。加了condition之后,可以让模型的生成又快又好。

4.2 classifier free guidance(有条件生成监督无条件生成)
额外引入一个网络来指导,推理的时候比较复杂(扩散模型需要反复迭代,每次迭代都需要额外算一个分数),所以引出了后续工作classifier free guidance。
classifier free guidance的方式,只是改变了模型输入的内容,除了 conditional输入外(随机高斯噪声输入加引导信息)还有 unconditional 的 采样输入,两种输入都会被送到同一个 diffusion model 从而让其能够具有无条件和有条件生成的能力。
得到有条件输出 fθ(xt, t, y) 和无条件输出 fθ(xt, t, ϕ) 后,就可以用前者监督后者,来引导扩散模型进行训练了。最后反向扩散做生成时,我们用无条件的生成,也能达到类似有条件生成的效果。这样一来就摆脱了分类器的限制,所以叫classifier free guidance。比如在训练时使用图像-文本对,这时可以使用文本做指导信号,也就是训练时使用文本作为y生成图像。然后把y去掉,替换为一个空集ϕ(空的序列),生成另外的输出。
扩散模型本来训练就很贵了,classifier free guidance这种方式在训练时需要生成两个输出,所以训练更贵了。但是这个方法确实效果好,所以在GLIDE 、DALL·E2和Imagen里都用了,而且都提到这是一个很重要的技巧。用了这么多技巧之后,GLIDE终于是一个很好的文生图模型了,只用了35亿参数,生成效果和分数就比DALL·E(120亿参数)还好。
OpenAI一看GLIDE这个方向靠谱,就马上跟进,不再考虑DALL·E的VQ-VAE路线了。将GLIDE改为层级式生成(56→256→1024)并加入prior网络等等,最终得到了DALL·E2。
5 DALLE2
5.1 两阶段生成
论文的训练数据集由图像 x 及其相应标题(captions) y 组成。给定图像 x ,经过训练好的CLIP模型分别得到文本特征zt和图像特征zi,然后训练两个组件来从标题生成图像:
- prior:先验模型 P(zi | y),根据标题 y 生成CLIP的图像特征zi。
- decoder :解码器P(x | zi, y),生成以CLIP图像特征zi和可选的文本标题 y为条件的图像x。
prior模型的输入就是CLIP编码的文本特征,其ground truth就是CLIP编码的图片特征,因为是图文对输入模型,CLIP是都能编码的。所以DALL·E2是一个两阶段的生成器。在先训练好CLIP之后,任意给定文本y yy,通过CLIP文本编码器生成文本特征。再根据prior生成图片特征,最后利用decoder解码图像特征得到生成的图片。CLIP+prior+decoder就是整个文生图模型:

5.2 decoder
decoder就是使用扩散模型,生成以CLIP图形特征和可选标题y为条件的图像,这部分就是在GLIDE基础上改进的。
首先,decoder利用了CLIP guidance和classifier-free guidance,也就是这里反向扩散过程中,指导信息要么来自CLIP模型,要么来自标题y,当然还有一些时候是guidance freed的。具体操作就是随机地在10%的时间里将CLIP特征设置为零,在50%的时间内删除文本标题y。这样做训练就更贵了,但是为了更好地效果,OpenAI还是把能用的都用了。
其次,为了提高分辨率,DALL·E2还用了层级式的生成,也就是训练了两个上采样扩散模型。一个将图像的分辨率从64×64上采样到256×256,另一个接着上采样的1024×1024。同时,为了提高上采样器的鲁棒性,还添加了噪声(第一个上采样阶段使用高斯模糊,对于第二个阶段,使用更多样化的BSR退化)。
最后,作者还强调它们只是用了空洞卷积(只有卷积没有自注意力,也就是没有用Transformer),所以推理时,模型可以适用任何分辨率。论文发现标题上采样没有任何益处,并且使用了 no guidance的unconditional ADM Nets。
5.3 prior
prior用于从文本特征生成图像特征,这部分作者试验了两种模型,两种模型都用了classifier-free guidance,因为效果好。
-
AR(自回归模型)
- 类似DALL·E或者GPT,将CLIP图像特征 zi 转为离散的code序列,masked掉之后从标题y进行自回归预测就行。
- 在CLIP中OpenAI就说过,这种自回归的预测模型训练效率太低了,为了使模型训练加速,还使用了PCA降维。
-
扩散模型
- 使用的是Transformer decoder处理序列。因为这里输入输出都是embedding序列,所以使用U-Net不太合适。
- 输入序列包括文本、CLIP的文本特征、timestep embedding、加了噪声之后的CLIP图像特征,还有Transformer本来就有的embedding(CLS token之类的)。最终这个序列拿来预测没有加过噪声的CLIP图像特征 zi 。
- 论文发现直接去预测没有污染过的图像特征 zi ,要比预测噪声效果更好(因为自从DDPM提出之后,大家都改为预测噪声了),预测时使用均方误差:(可以看到下面公式里是 zi 而非噪声)

参考资料:

















 9274
9274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









