







【0】README
本文使用 java 计算混淆矩阵,并利用 混淆矩阵值计算 分类指标;通用分类指标有: 查准率,查全率,查准率和查全率的调和均值F1值,正确率, AOC, AUC等;本文计算前4个指标;(附源代码和结果截图)
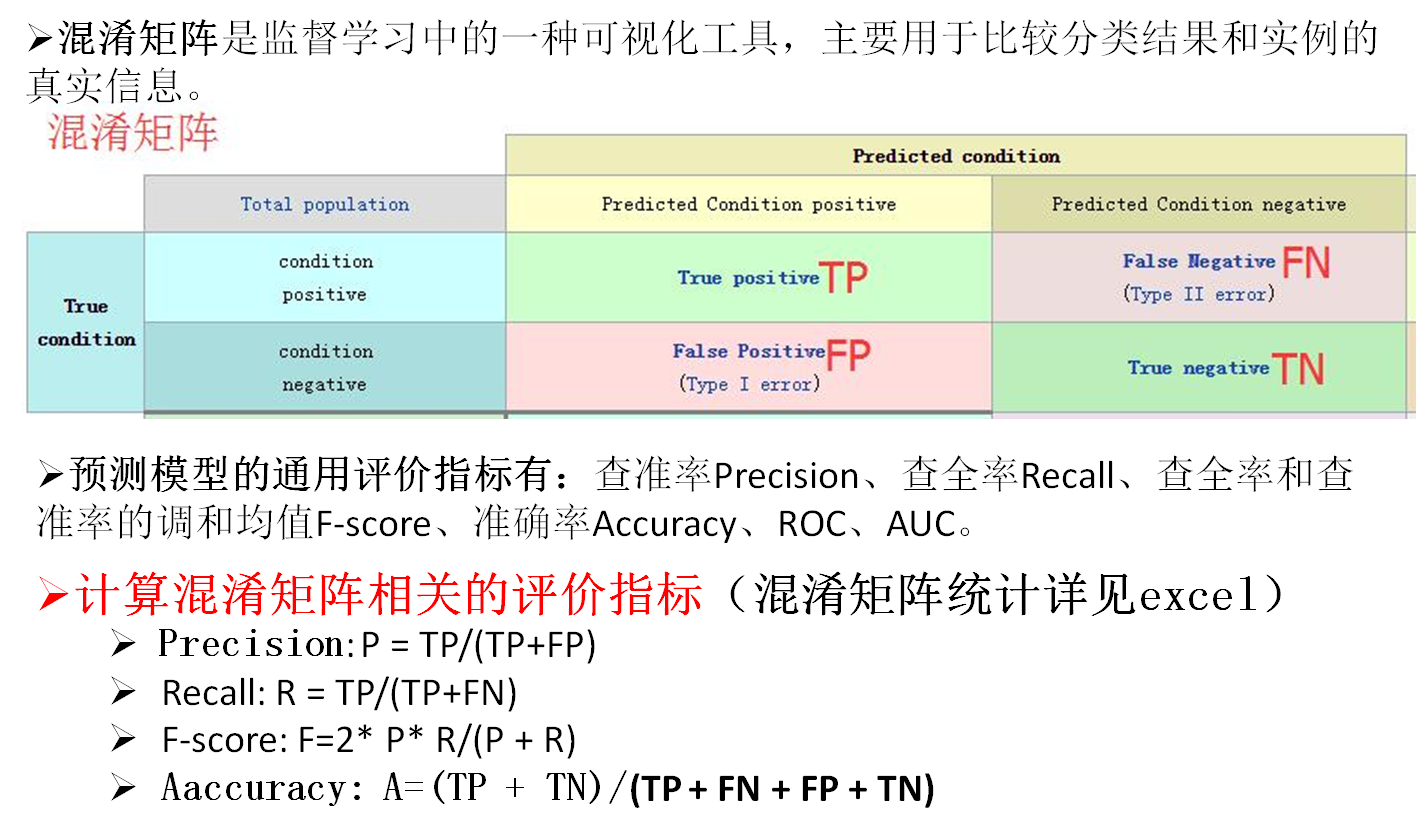
【1】什么是混淆矩阵(借用自己PPT截图)
【2】查准率和查全率的区别
查准率:查准率表示选出的样本中有多少比例样本是正例(期望样本);
查全率:查全率表示有多少比例的正样本(期望样本)被选出来了;
【3】如何计算多分类混淆矩阵的评价指标(摘自周志华老师的机器学习,极力推荐大家买一本)

【4】源码如下
// 计算混淆矩阵,并根据混淆矩阵计算 10次交叉验证下的 评估指标均值(精确度, 召回率, F值, 准确率 这4个指标)
public class SingleConfusionMatrix {
// C:\Users\pacoson\Desktop\confusion_matrix
private static String dir = "C:" + File.separator + "Users" + File.separator + "pacoson" + File.separator
+ "Desktop" + File.separator + "confusion_matrix";
private static double[][][] averages = new double[10][3][4]; // 10次交叉验证, 3个unknown(12, 24, 48),4个度量指标(查全率,查准率,F1,准确率)
private static int fold = 0;
private static int counter = 6;
public static void main(String[] args) {
File file = new File(dir);
showFiles();
}
// show files.
public static void showFiles() {
File[] files = new File(dir).listFiles();
for(File file: files) { // 遍历 dir 目录下的所有文件
String filename = file.getName();
String prefix = filename.split("_")[0];
if(prefix.length() > 1) continue;
fold = Integer.valueOf(prefix); // 10次交叉验证的编号
System.out.println("\n====== fold=" + fold + "======");
double[][] array = new double[100][6]; // item 数组
DataRead reader = new DataRead(file.getAbsolutePath());
reader.readDataToArray(1, 1, array); // 数据读取完毕
computeConfusion(0, array); // 预测长度12
// computeConfusion(1, array); // 预测长度24
// computeConfusion(2, array); // 预测长度48
break;
}
// computeAverage();
}
// column = 1(12), 2(24), 3(48)
static void computeConfusion(int column, double[][] array) {
// 1.计算confusion12/24/48: TP FN FP TN
int[][] confusions = new int[6][4];
counter = 6;
for (int id = 0; id < 6; id++) {
for (int i = 0; i < array.length; i++) {
if(array[i][column] == id) {
if(array[i][column+3] == id) // column = 1(12), 2(24), 3(48)
confusions[id][0]++; // TP
else
confusions[id][1]++; // FN
} else if(array[i][column] != id) {
if(array[i][column+3] == id)
confusions[id][2]++; // FP
else
confusions[id][3]++; // TN
}
}
}
// 2.计算 统计指标:
// 精确度P=TP/(TP+FP), 查准率
// 召回率R= TP/(TP+FN), 查全率
// f1值=2*P*R/(P+R)
// 准确率=(TP+TN)/(TP+FN+FP+TN)
double[][] metrices = new double[6][4]; // 精确度, 召回率, F1值, 分类准确率
for (int i = 0; i < confusions.length; i++) {
double[] metric = metrices[i];
int[] confusion = confusions[i];
System.out.print("confusion matrix: TP, FN, FP, TN: ");
for (int j = 0; j < confusion.length; j++) { // 打印每个混淆矩阵
System.out.print(confusion[j] + ", ");
}
System.out.println();
if(confusion[0] + confusion[2] != 0) // 分母不能为零.
metric[0] = (double)confusion[0] / (confusion[0] + confusion[2]); // 精确度
if(confusion[0] + confusion[1] != 0) // 分母不能为零.
metric[1] = (double)confusion[0] / (confusion[0] + confusion[1]); // 召回率
if(metric[0] + metric[1] != 0) // 分母不能为零.
metric[2] = (double)2*metric[0]*metric[1]/(metric[0] + metric[1]); // f值
metric[3] = (double)(confusion[0]+confusion[3]) / (confusion[0] + confusion[1]+ confusion[2]+ confusion[3]); // 准确率
if(confusion[3] == 100) { // 如果 TN == 100, 表明没有这个类成员(TN表示真实类别不是该类别且预测类别也不是该类别,那如果总数为100,则没有模型没有选出该类别)。
metric[3] = 0;
counter--;
}
}
// 3.求均值(宏精确度, 宏召回率, 宏F1值, 宏准确率)
// double[] average = new double[4];
// private static double[][][] averages = new double[10][3][4]; // 10次交叉验证, 3个unknown(12, 24, 48),4个度量指标(查全率,查准率,F1,准确率)
// double[][] metrices = new double[6][4]; // 精确度, 召回率, F1值, 分类准确率
double[] average = averages[fold][column];
System.out.println("counter = " + counter);
for (int j = 0; j < metrices[0].length; j++) {
double sum = 0;
for (int i = 0; i < metrices.length; i++) {
sum += metrices[i][j];
}
average[j] = sum/counter;
System.out.print(average[j] + " ");
}
System.out.println();
}
public static void computeAverage() {
System.out.println("\n === 计算10折交叉验证的统计指标均值 === \n");
// 预测长度为 12(j==0), 24(j==1), 48(j==2)
for (int j = 0; j < 3; j++) {
for (int k = 0; k < averages[0][0].length; k++) { // 4 个 items
double sum = 0;
for (int i = 0; i < averages.length; i++) { // 行(10折)
sum += averages[i][j][k];
}
System.out.print(sum/10 + " ");
}
System.out.println();
}
}
}

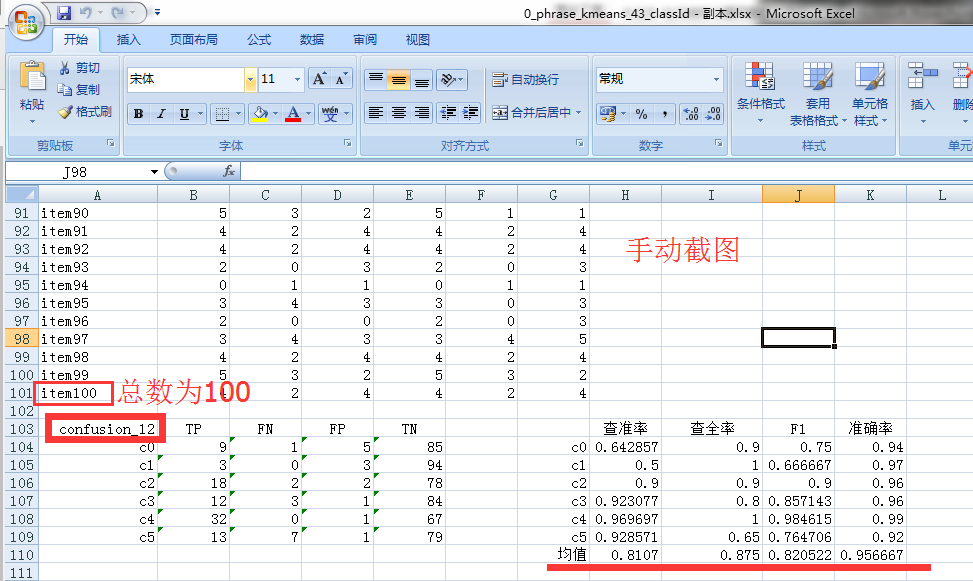
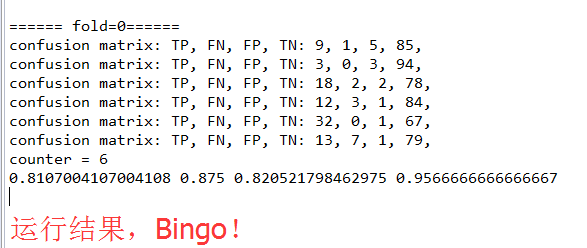
Tips: 10次交叉验证实验,只需要调用其中的 computeAverage() 方法 就可以计算 其10次的均值了。(这里只求出了某次交叉实验的均值)















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









