









D2-Net:A Trainable CNN for Joint Description and Detection of Local Features
论文链接:CVPR 2019 Open Access Repository
1.Introduction
研究背景:
1.建立像素级别的图像对应关系是许多视觉任务的基础,例如3D计算机视觉、视频压缩、跟踪、图像检索以及视觉定位等。
2.稀疏局部特征是一种流行的对应关系估计方法。
3.稀疏局部特征在各种图像条件下都应用的很好,但是在极端外观变换时表现较差。
研究目的:提出一组稀疏特征,它既能在变换条件下具有稳健性又能高效的匹配和存储。
研究方法:
1.通过deep CNN计算一组特征图。
2.用特征图去计算描述子并且检测特征点。
实验证明:
1.该方法比起稠密方法需要更少的内存。
2.在变换条件下表现得更好。
3.不需要任何训练的情况下达到了最佳的表现。
4.在标志性场景的大型数据集上进行微调可以进一步提高性能。
不足:
1.对比传统的稀疏特征方法,该方法由于需要提取稠密的描述子,所以更加的低效。
2.由于特征点检测基于higher-level的信息,导致更加稳健但是更加不准确。
2.Related Work
局部特征:
传统稀疏特征提取的方法基本上都是先进行特征提取“[7, 19, 29, 31, 33]” ,然后提取描述子“[7, 9, 24, 29, 44]” 。
该篇论文同时进行特征点提取和描述子提取,和“SuperPoint [13]” 较为相似。
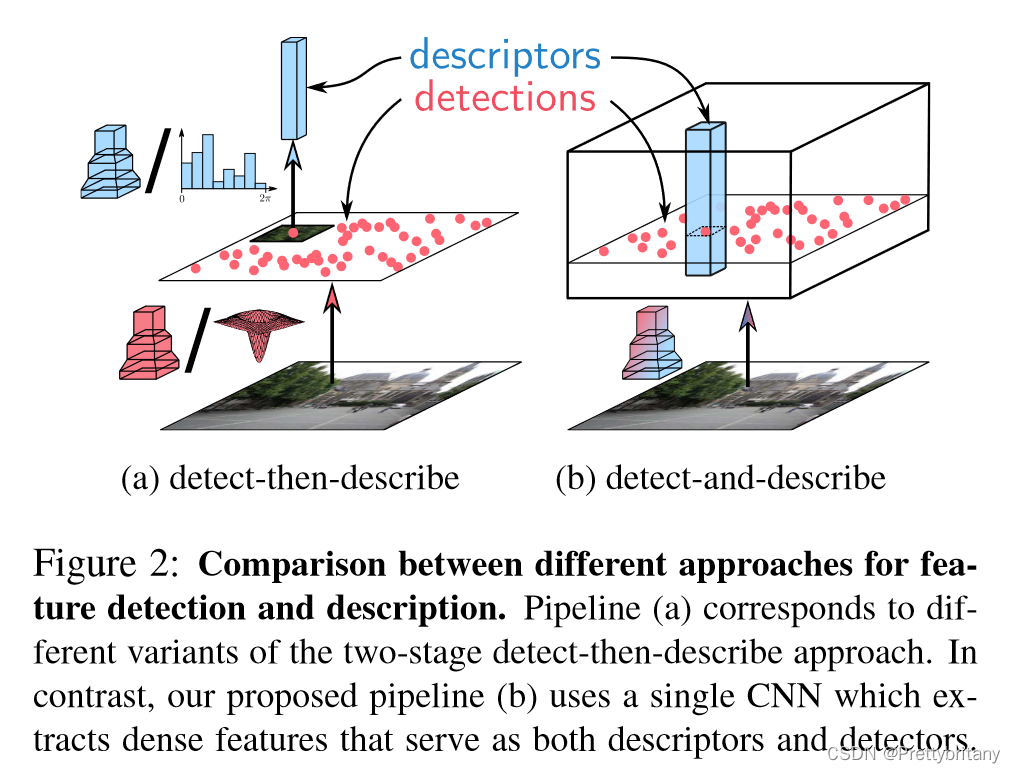
稠密描述子提取和匹配:
放弃特征点检测而直接在整张图片上进行稠密的描述子提取“[10, 15, 48, 52].” 这种方法比稀疏特征点匹配“[45, 58, 69],” 显现出更好的匹配结果。特别是在强烈光照变换下“[69].”
图像检索:
图像检索“[3, 18, 37, 40, 60, 61]”
首先基于稠密描述子提取然后将这些稠密描述子整合到图像级别的描述子中用于检索:“[3,37,60,61]”
与本文方法最相近的:“[37,60]”
目标检测:
与本文方法相似运用在目标检测领域的方法:[28, 41, 42].”
3.Joint Detection and Description Pipeline
CNN:F
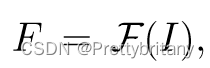

3.1.Feature Description
描述子向量d:
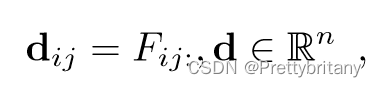
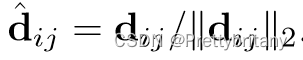
3.2.Feature Detection
2D检测响应图(类似SIFT中的DOG或者Harris角检测器中的角度得分图):
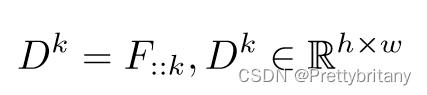
Hard feature detection:
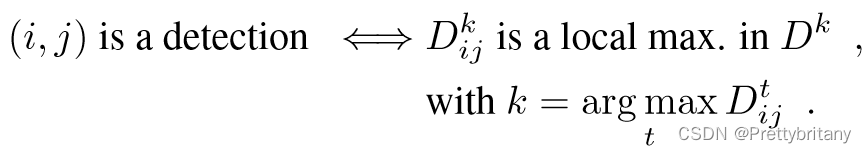
Soft feature detection:
上述硬检测过程被软化有助于更好的反向传播。
首先,定义一个软局部最大:
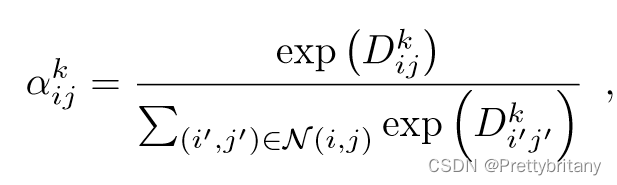
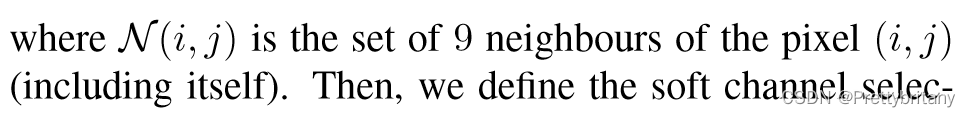
然后,定义软信道选择:
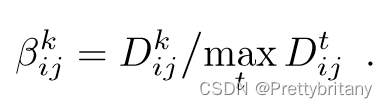
然后,综合:
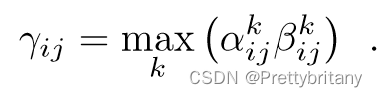
最后,像素的软检测分数:
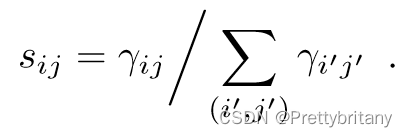
Multiscale Detection:
为了在尺度变化时依然具有稳健性,使用图像金字塔:
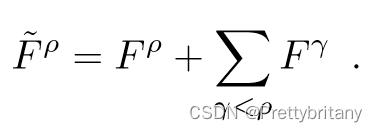
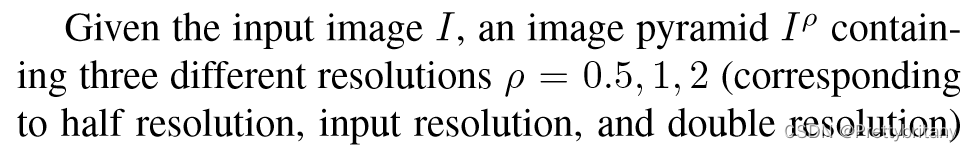
4.Jointly optimizing detection and description
介绍用于训练的损失函数、数据集。
4.1.Training loss
在检测方面,希望特征点在各种变化下的重复率高一些;在描述方面,希望描述子们是不相同的。
描述子损失参考文献“[6, 34]” ,
“triplet margin ranking loss” :


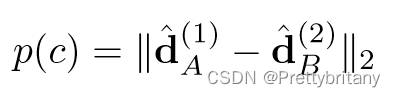
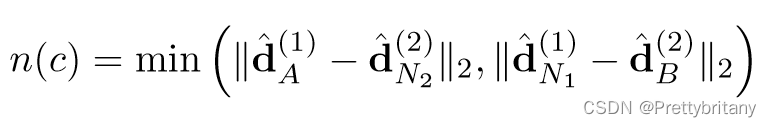
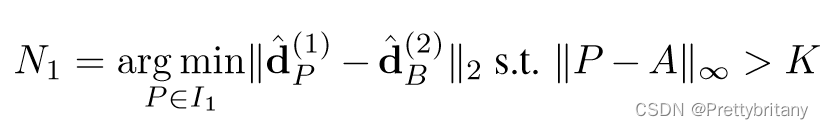
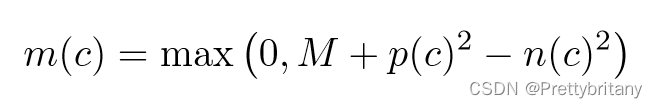
该损失函数可能会导致错误的匹配,因此在此基础上再加入检测损失部分:
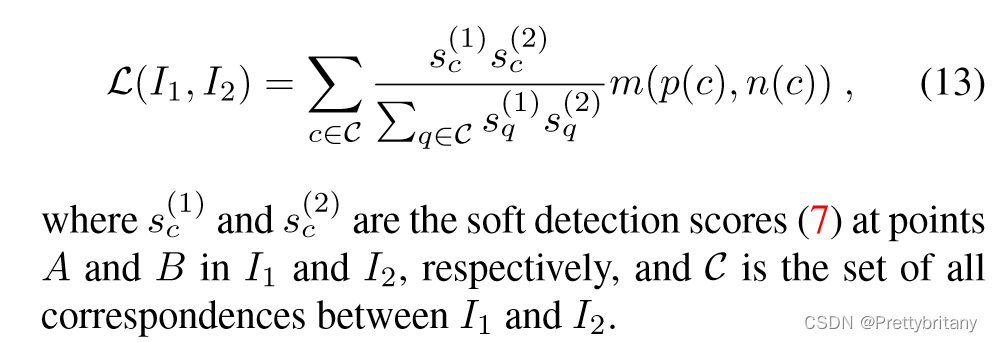
4.2.Traning Data
作者使用了由1,070,468张互联网照片重建的196个不同场景的MegaDepth数据集。数据集提供了102,681张图像的相机内外参数和多视图立体的深度图。
为了提取对应关系,作者首先考虑了所有具有至少50%重叠的稀疏SfM点云的图像对。对于每一对,第二张图像中具有深度信息的所有点都被投影到第一张图像中。然后运行一个深度检查以移除被遮挡的像素。最后,作者得到了327,036对图像。这个数据集被分割成一个验证数据集,包含18,149对图像(来自78个场景,每个场景少于500对图像),和一个训练数据集。
6.Conclusions
贡献:
1.提出了一个特征点检测和描述子生成同时进行的算法。
2.该算法在环境变化时能在相机定位技术上取得最好的结果。
未来工作:
1.提高特征点检测的精确度。
2.在损失中集成类似比率测试的目标。
比率测试:在特征检测中,比率测试是一种用于过滤关键点匹配的方法,通过消除当第二优匹配几乎同样好时的匹配。具体来说,对于图像1中的每个关键点,我们找到在图像2中的最接近的匹配。如果使用欧氏距离,这意味着在集合L2中,与L1中的关键点具有最小欧氏距离的关键点。
我们可以试图设置一个阈值并消除所有距离超过该阈值的配对。但是,情况并非那么简单,因为描述符内的不是所有变量都是"鉴别性"的:两个关键点可能具有小的距离测量,因为它们的描述符内的大多数变量具有相似的值,但是那些变量可能对实际的匹配无关。
因此,David Lowe提出了一种简单的方法,通过检查两个距离是否足够不同来过滤关键点匹配。如果他们不是,那么关键点将被消除,不会用于进一步的计算。这就是比率测试在特征检测中的工作原理。

















 4775
4775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









