









内容总结,本篇综述主要介绍和分析了以下几个方面:
-
• 概述了MM-LLMs的设计形式,将模型架构分为5个部分:模态编码器、输入投影器、语言模型骨干、输出投影器和模态生成器。阐述了每一部分的实现选择。
-
• 描述了MM-LLMs的训练流程,主要包括多模态预训练和多模态指令微调两个阶段。
-
• 总结分析了26种主流的MM-LLMs模型,从模型架构、训练数据集规模等多个维度进行了对比。
-
• 综合回顾了主要MM-LLMs在18个广泛使用的视觉语言评测集上的表现,并总结提炼出提升模型效果的重要训练方法。
-
• 探讨了MM-LLMs未来发展的5大方向:构建更强大的模型、设计更具挑战性的评估集、移动端/轻量级部署、具备实体性的智能和持续性指令调整。
综上,该论文系统梳理了MM-LLMs的框架、模型、评估指标和未来研究方向,对其现状和发展趋势进行了全面而深入的总结,为相关领域的研究与进一步发展奠定了基础。
部分模型 总结如下:

1.引言
1.1 多模态LLMs 的现状
最近,多模态大模型取得重大进展。随着数据集和模型的规模不断扩大,传统的 MM 模型带来了巨大的计算量,尤其是从头开始训练的话。研究人员意识到 MM 的研究重点工作在各个模态的连接上,所以一个合理的方法是利用好现成的训练好的单模态基础模型,尤其是 LLM。这样可以减少多模态训练的费用,提升训练效率。
MM-LLM 利用 LLM为各种 MM 任务提供认知能力。LLM 具有良好的语言生成,zero-shot 和 ICL 的能力。其他模态的基础模型则提供了高质量的表征。考虑到不同模态的模型是分开训练的,如何将不同模态连接起来,实现协同推理,是核心挑战。
这里面的主要工作便是通过多模态预训练和多模态的指令微调,来实现模态之间的对齐,以及模型输出与人类意图的对齐。
1.2 多模态的发展历程

关于多模态的发展主要有:
-
• 最初的发展集中在多模态的内容理解和文本的生成:Flamingo,BLIP-2, Kosmos-1,LLaVA/LLaVA-1.5/LLaVA-1.6,MiniGPT-4,MultiModal-GPT,Video-Chat,VIdeo-LLaMA,IDEFICS,Fuyu-8B,Qwen-Audio
-
• 同时实现多模态的输入和输出工作 MM-LMM,探索特定模态的生成,例如 Kosmos-2,Mini-GPT5,以及语音生成的 SpeechGPT
-
• 将 LLM 和外部工具继承进来,实现“any-to-any”的 多模态理解和生成。visual-chatgpt,ViperGPT,MM-React,HuggingGPT,AudioGPT
-
• 同样,有为了减少级联过程中传播误差的工作,有 NExT-GPT 和 CoDI-2,来开发任意模式的多模态模型
1.3 内容结构:
本文接下来的机构如下所示。第二节讲模型架构,第三节讲训练流程。
第二节模型架构分为五部分,不同模态的编码器 Encoder,输入 Projector,LLM 骨干,输出 Projector,不同模态的生成器。
训练流程包含连个部分,预训练流程和指令微调部分。同时提供了主流的数据集的介绍。
第四节,讨论 26 个最先进的多模态模型。
2.模型结构
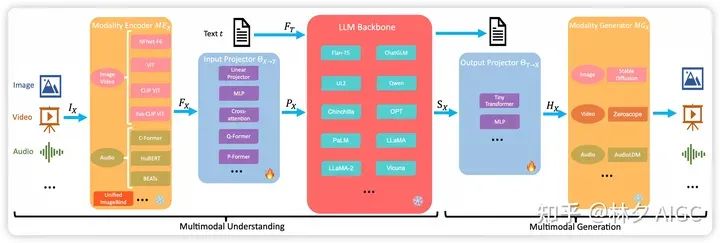
如图 2 所示,这里包含了通用多模态模型结构的五个组件部分,以及每个组件部分的常用选择。多模态理解主要是前三个部分。(模态对齐)训练期间,encoder,LLM Backbone 和 generator 一般保持冻结。主要优化输出和输出的 projector。由于Projector 是轻量级的模块,MM-LLMs 中可以训练的参数比例和总参数相比非常小(2% 左右),模型的总体参数规模取决于LLM 部分。
这里对论文的内容进行更正,目前有的多模态大模型,也会对 Encoder,甚至 LLM 进行训练,来提升整体的模型的能力。
2.1 Modality Encoder
模态编码器主要是对来自不同模态的输入进行编码,来获得相应的特征:
FX=MEX(IX)
存在各种预训练的编码器来处理不同的模态,模态可以是图像,视频,音频,3D 等。
视觉模态:
对于图像,一般有四个可选的编码器,NFNet-F6,ViT,CLIP VIT,EVA-CLIP ViT。
-
• NFNet-F6:是一个无归一化的 ResNet 网络,可以在增强过的数据集上获得 SOTA 的图像识别的性能。
-
• VIT:采用 transformer 模型,将 image 变成 patch,然后对图像进行处理。然后经过线性投影flatten,然后经过多个 transformer 模块。
-
• CLIP-VIT:利用大量的文本-图像快,通过对比学习来优化 ViT,将成对的文本图像视为正样本,其他的文本和图像视为负样本。
-
• EVA-CLIP:对大规模的 CLIP 训练稳定了训练过程和优化过程。
对于视频,可以统一采样 5 帧,进行与图像同样的处理。
音频模态:
通常使用 C-Former,HuBERT,BEATs 和 Whisper 等进行编码。
-
• C-Former:使用了 CIF 对齐机制来实现序列的转换,并且使用一个 Transformer 来提取音频特征。
-
• HuBERT:是一个自监督的语音表征徐诶框架,基于 BERT。通过离散hidden units 的mask 预测来实现。
-
• BEAT 是:是一个迭代的音频预训练框架,使用音频 Transformer 来学习双向编码表示。
2.2 输入 Projector
输出projector 的任务是将其他模态的编码特征 FX 与文本特征空间的特征T进行对齐。对齐后的特征作为prompts Px 联通文本特征 FT 输入到 LLM Backbone 内。给定 X 模态-text数据集 {IX,t} ,目标是最小化生成损失。
输入 Projecor 可以通MLP 或者多层 MLP 来实现。也有复杂的实现,比如 Cross-Attention,Q-Former,P-Former 等。Cross-Attention 使用一系列的可训练的 query 和编码特征 FX 作为 key 来压缩特征序列到固定的长度。将压缩的表示特征输给 LLM。
2.3 LLM Backbone
LLM作为核心智能体,MM-LLMs 可以继承一些显着的属性,如零样本泛化(zero-shot)、少样本 ICL、思想链 (CoT) 和指令遵循。LLM 主干处理来自各种模态的表示,参与有关输入的语义理解、推理和决策。它产生 (1) 直接文本输出 t,以及 (2) 来自其他模式(如果有)的信号token Sx 。这些信号token充当指导生成器是否生成 MM 内容的指令,如果是,则指定要生成的内容:
t,SX=LLM(PX,FT)
上式中,其他模态P_X的对齐后的表征,可以认为是软 prompt-tuning,输给 LLM Backbone。发而且一些研究工作引入了 PEFT 的方法,例如 Prefix-tuning,Adapter 和 LoRA。这些 case 里面,希望更少的参数可以被训练,甚至少于 0.1% 的 LLM 的参数参与训练。
通常用到的 LLM 模型有 Flan-T5,ChatGLM,UL2,Qwen,Chinchilla,OPT,PaLM,LLaMA ,LLaMA2 ,Vicuna 等。
2.4 Output Projector
输出Projector将 LLM 的输出的 token 表征 SX 转变成特征 HX ,然后输给生成器 MGX。
给定数据X-text数据集 {IX,t} ,首先将文本t输给 LLM,生成对应的 SX ,然后映射得到 HX 。模型优化的目标是最小化 HX 与 MGX的条件文本之间的距离。
2.5 模态生成器
模态生成器 MGX 一般用于生成不同的模态来输出。当前的工作一般使用现成的扩大模型(Latent diffusion model),例如 Stable Diffusion用于图像生成,Zeroscope用于视频生成,AudioLDM-2 用于音频生成。
输出 Projector 输出的特征 Hx 作为条件输入,在去噪的过程中,用于生成 MM 的内容。训练过程中, gt content 首先转换为 latent feature z0 ,由预训练好的 VQA 模型。然后噪声 ϵ 加到 z0 上,获得 noise latent feature zt ,预训练好的 UNet 用于计算条件损失,通过最小化 loss 来优化参数。
3.训练过程
3.1 预训练阶段
在预训练阶段,通常利用 X-Text 的数据集,来训练输入,输出的 Projector。通过优化损失函数来实现不同模态的对齐。PEFT 有时候用于 LLM Backbone。
X-文本数据集包含图像-文本、视频-文本和音频-文本,其中图像-文本有两种类型:图像-文本对(即)和交错图像-文本语料库(即,txt1>)。这些 X-Text 数据集的详细统计数据如附录 F 的表 3 所示。

3.2 多模态微调
多模态微调是对满足指令微调格式的一系列数据集对预训练好的多模态大模型进行微调。
通过这种微调,MM-LLM 是可以遵循新的指令泛化到没有见过的任务,增强 zero-shot 的能力。这个简单而有影响力的概念促进了 NLP 领域后续努力的成功,例如,InstructGPT、OPT-IML、InstructBLIP。
MM IT 包括监督微调(SFT)和 RLHF 两部分,目的是为了使得模型符合人类的意图或者偏好,并且增强 MMLLMs 的交互能力。
SFT 将 PT 阶段的额数据转换为指令-aware 的格式,使用 QA 任务作为例子。可以采用各种模板,例如:
(1) {Question} A short answer to the question is;
(2) Examine the image and respond to the following question with a brief answer: {Question}. Answer:
优化目标和预训练是相同的,SFT 数据可以构造为单论的 QA 或者多伦的 QA。
常用的 SFT 和 RLHF 的数据集见表 4。
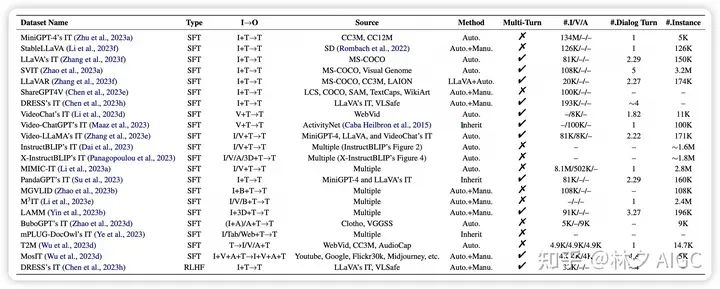
4.多模态大模型总结
4.1 26 个多模态大模型全面比较

如表1所示,对26 SOTA MM-LLMs的架构和训练数据集规模进行了全面比较。随后,简要介绍这些模型的核心贡献并总结了它们的发展趋势。
(1) Flamingo。代表了一系列视觉语言 (VL) 模型,旨在处理交错的视觉数据和文本,生成自由格式的文本作为输出。
(2) BLIP-2 引入了一个资源效率更高的框架,包括用于弥补模态差距的轻量级 Q-Former ,实现对冻结 LLMs 的充分利用。利用 LLMs,BLIP-2 可以使用自然语言提示进行零样本图像到文本的生成。
(3) LLaVA 率先将 IT 技术应用到 MM 领域。为了解决数据稀缺问题,LLaVA 引入了使用 ChatGPT/GPT-4 创建的新型开源 MM 指令跟踪数据集以及 MM 指令跟踪基准 LLaVA-Bench。
(4) MiniGPT-4 提出了一种简化的方法,仅训练一个线性层即可将预训练的视觉编码器与 LLM 对齐。这种有效的方法能够复制 GPT-4 所展示的功能。
(5) mPLUG-Owl 提出了一种新颖的 MM-LLMs 模块化训练框架,结合了视觉上下文。为了评估不同模型在 MM 任务中的表现,该框架包含一个名为 OwlEval 的教学评估数据集。
(6) X-LLM 陈等人 扩展到包括音频在内的各种模式,并表现出强大的可扩展性。利用Q-Former的语言可迁移性,X-LLM成功应用于汉藏语境。
(7) VideoChat 开创了一种高效的以聊天为中心的 MM-LLM 用于视频理解对话,为该领域的未来研究制定标准,并为学术界和工业界提供协议。
(8)InstructBLIP 基于预训练的BLIP-2模型进行训练,在MM IT期间仅更新Q-Former。通过引入指令感知的视觉特征提取和相应的指令,该模型使得能够提取灵活多样的特征。
(9) PandaGPT 是一种开创性的通用模型,能够理解 6 不同模式的指令并根据指令采取行动:文本、图像/视频、音频、热、深度和惯性测量单位。
(10) PaLI-X 使用混合 VL 目标和单峰目标进行训练,包括前缀完成和屏蔽令牌完成。事实证明,这种方法对于下游任务结果和在微调设置中实现帕累托前沿都是有效的。
(11) Video-LLaMA 引入了多分支跨模式PT框架,使LLMs能够在与人类对话的同时同时处理给定视频的视觉和音频内容。该框架使视觉与语言以及音频与语言保持一致。
(12) Video-ChatGPT 是专门为视频对话设计的模型,能够通过集成时空视觉表示来生成有关视频的讨论。
(13) Shikra 介绍了一种简单且统一的预训练 MM-LLM,专为参考对话(涉及图像中区域和对象的讨论的任务)而定制。该模型展示了值得称赞的泛化能力,可以有效处理看不见的设置。
(14) DLP 提出 P-Former 来预测理想提示,并在单模态句子数据集上进行训练。这展示了单模态训练增强 MM 学习的可行性。
(15) BuboGPT 是通过学习共享语义空间构建的模型,用于全面理解MM内容。它探索图像、文本和音频等不同模式之间的细粒度关系。
(16) ChatSpot 引入了一种简单而有效的方法来微调 MM-LLM 的精确引用指令,促进细粒度的交互。由图像级和区域级指令组成的精确引用指令的结合增强了多粒度 VL 任务描述的集成。
(17) Qwen-VL 是一个多语言MM-LLM,支持英文和中文。Qwen-VL 还允许在训练阶段输入多个图像,提高其理解视觉上下文的能力。
(18) NExT-GPT 是一款端到端、通用的any-to-any MM-LLM,支持图像、视频、音频、文本的自由输入输出。它采用轻量级对齐策略,在编码阶段利用以LLM为中心的对齐方式,在解码阶段利用指令跟随对齐方式。
(19) MiniGPT-5 是一个 MM-LLM,集成了生成 voken 的反演以及与稳定扩散的集成。它擅长为 MM 生成执行交错 VL 输出。在训练阶段加入无分类器指导可以提高生成质量。
参考资料
`[1] Visual Instruction Tuning towards General-Purpose Multimodal Model: A Survey https://arxiv.org/abs/2312.16602 [2] MM-LLMs: Recent Advances in MultiModal Large Language Models https://arxiv.org/abs/2401.13601`
本文转自 https://mp.weixin.qq.com/s/caxIWUAy2jXWZ1490NqDkg,如有侵权,请联系删除。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









