



首先,我们需要了解一下,什么是机器学习?
机器学习其实是人工智能的一个领域,本质上是研究怎样让计算机像人一样进行学习,获取新的知识和技能,从而不断改善自身的性能。
1.机器学习vs传统编程
在传统的编程过程中,计算机的工作主要是根据人们给它的数据和规则去进行计算,最终得到答案。
程序员需要提前写好所有规则,让计算机能够依照规则进行执行,例如要让计算机判断图片上的是猫还是狗,就得一条条写清楚猫和狗的特点(规则),但是这么一条条要全部写出来,程序员表示臣妾做不到啊~

于是机器学习反其道而行,我们不告诉计算机具体的规则,而是给计算机大量的数据,让计算机在数据中总结规律,从而能去运用规律。
我们给计算机看几千张猫的照片,不用去给它解释猫的耳朵有点像三角形,有胡须,还会喵喵叫等等,只需要计算机通过这些照片(数据)去总结规律,自然就能认识猫了。
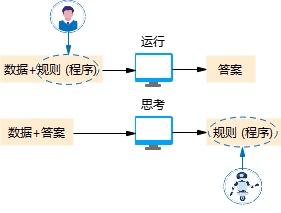
传统编程:程序员写规则→程序执行→得到结果
机器学习:给程序数据→程序学习→自动得出规则
传统编程和机器学习的它们的本质区别就是:谁在制定规则?
传统编程适用于规则明确、逻辑清晰的问题;机器学习适用于规则复杂、难以人工总结的场景。
2.机器学习的三大学习方式
机器学习的核心学习方式主要分为三类:监督学习、无监督学习、强化学习。
-
监督学习:有标准答案的刷题模式
监督学习是机器学习中最常见的学习方式之一,核心逻辑和我们上学刷题如出一辙——有明确题目、有标准答案,学完就能直接“应试”。
它的训练数据都带有“标签”,相当于“输入内容+正确结果”的配套套餐,模型就像认真刷题的学生,通过反复学习海量“题目(输入特征)+答案(标签)”,慢慢摸清两者之间的对应规律(映射关系),看到A特征,就能对应B结果

-
无监督学习:没有标准答案的探索模式
与监督学习不同,无监督学习的输入数据都是不带标签的原始素材。
模型得像侦探一样,自己从海量数据里找到隐藏的规律。
它的核心任务是挖掘数据的内在结构:哪些数据长得像可以归为一类?数据的核心特征是什么?有没有偏离常规的“异类”?
这些全都靠模型自主发现。

-
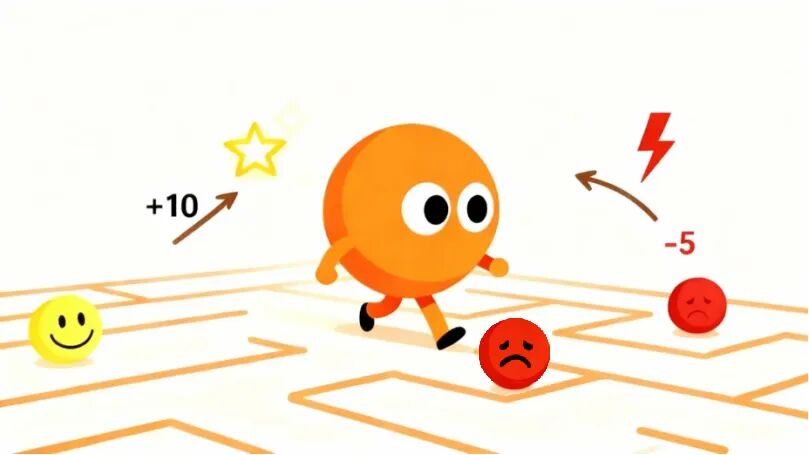
强化学习:边试错边优化的闯关升级模式
强化学习的核心是在互动中成长,既没有监督学习的固定标准答案,也不像无监督学习那样没有明确的目标,它更像是一款闯关游戏,模型就是“玩家”,环境则是“游戏地图”,有明确的“通关目标”,还有即时的奖惩机制。
模型会在环境中不断尝试行动,做对了(靠近目标)能拿到奖励,做错了(偏离目标或遇到障碍)则得到惩罚。
通过一次次试错,模型可以慢慢优化行动策略,从“处处碰壁”到“精准避坑”,最终找到最快通关的最佳路径。
3.机器学习的学习N步曲
机器学习的过程不是一步到位的,它也有一套明确步骤的成长流程,要从菜鸟变大神,AI也需要经历“找素材、选方法、勤练习、验成果、上岗实战”的完整路径。
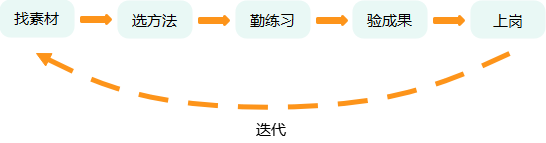
机器学习的核心过程可以概括为5步:数据准备→模型选择→训练优化→评估测试→部署应用,本质是“用数据喂模型、用反馈调整模型、用实战验证模型”的闭环。
1. 数据收集与预处理
学习的第一步就是收集学习素材(数据),如果模型要使用监督学习方式训练,那么就要收集“输入+标签”的配套数据,如果模型要使用无监督学习方式进行训练,那么就要收集原始无标签的数据。
当然,收集到的数据还需要进一步的加工和整理(数据清洗、数据预处理等),以便模型能够读懂。
2. 选择学习方式和算法
模型就像是一个学习工具,不同的模型,擅长处理不同任务类型的问题,比如有的擅长处理图片,有的擅长处理文字。
模型的选择取决于任务类型和数据特征,在训练时,需要根据任务的性质和数据的特点来选择模型的学习方式和算法。
文档君整理了一个表格,三种方式到底怎么选,一目了然~
| 学习方式 | 适用场景 | 常见算法 |
|---|---|---|
| 监督学习(刷题) | 要预测“是/否”、“A类/B类”或具体数值,选它! |
|
| 无监督学习(探索) | 要找相似组、简化数据、找异常,选它! |
|
| 强化学习(闯关) | 要AI自主决策、边试错边成长,选它! |
|
3. 训练优化
模型训练是通过数据不断优化模型参数的过程。
当把整理好的数据喂给模型,并选择学习方式和算法后,还需要在模型的学习过程中不断纠错调优,让模型在训练数据上学习规律(监督学习学“输入-标签”的映射;无监督学习挖数据结构;强化学习根据奖惩情况调整策略)。
4. 评估测试
模型完成学习后也需要进行模拟考试,看看模型能不能举一反三。
在评估测试中,我们需要用没学过的新数据测试模型效果,并用具体的指标判断效果(比如准确率、误差值等),如果测试结果不达标,那么模型还得继续回炉重造。
5. 部署应用
模型通过测试后就可以正式上岗了,把训练好的模型嵌入产品中(如APP、系统、机器人),模型就可以实时处理新数据了。
当然,上岗之后的模型还需要持续监控它的表现,并用新数据迭代优化模型,保证模型的长期有效性。
END
看完 AI 的 “成长流程”,你觉得哪个步骤最像你学习或工作中的 “关键环节”?
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

😝有需要的小伙伴,可以扫描下方二v码免费领取【保证100%免费】🆓

















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









