






CrossFormer 实现图像分类以及视觉任务的骨干网络替换
它使用交替的局部和全局注意力击败了 PVT 和 Swin。
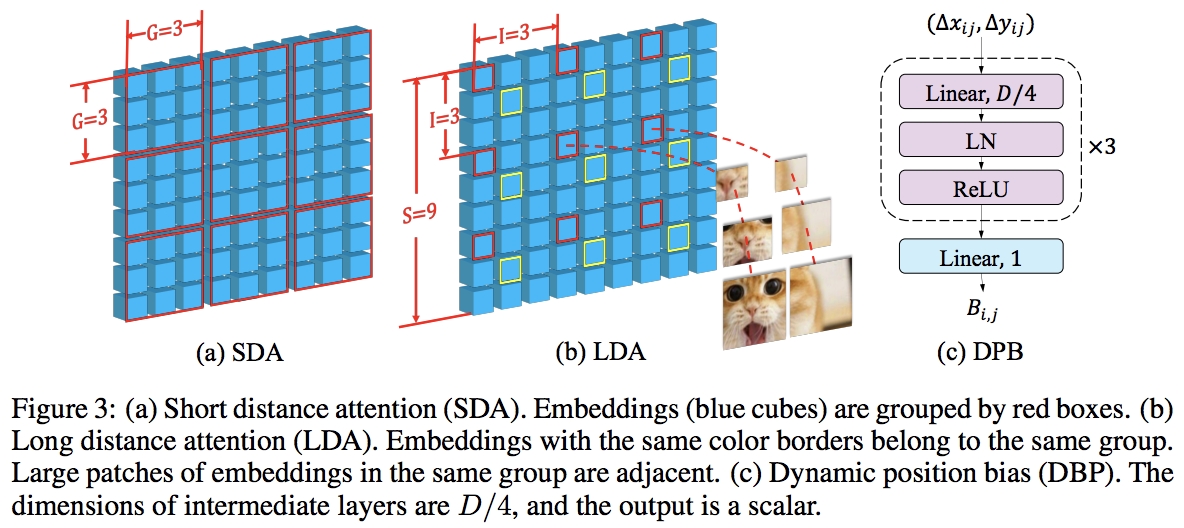
全局注意力是在窗口维度上完成的,以降低复杂性,还具有跨尺度嵌入层,被证明是可以改进所有视觉转换器的通用骨干网络。
并设计了动态相对位置偏差,以允许网络推广到更高分辨率的图像。
只限pytorch框架
ID:92100681596231987
UOSB_TEAM

CrossFormer:革新图像分类与视觉任务的骨干网络
在视觉计算领域,骨干网络的设计一直是研究的热点。近期,CrossFormer作为一种新兴的网络架构,实现了在图像分类以及视觉任务中的骨干网络替换,并以其出色的性能引起了广泛关注。本文将深入探讨CrossFormer的实现原理、其相对于其他网络的优势,以及它在图像分类和视觉任务中的实际应用。
一、CrossFormer概述
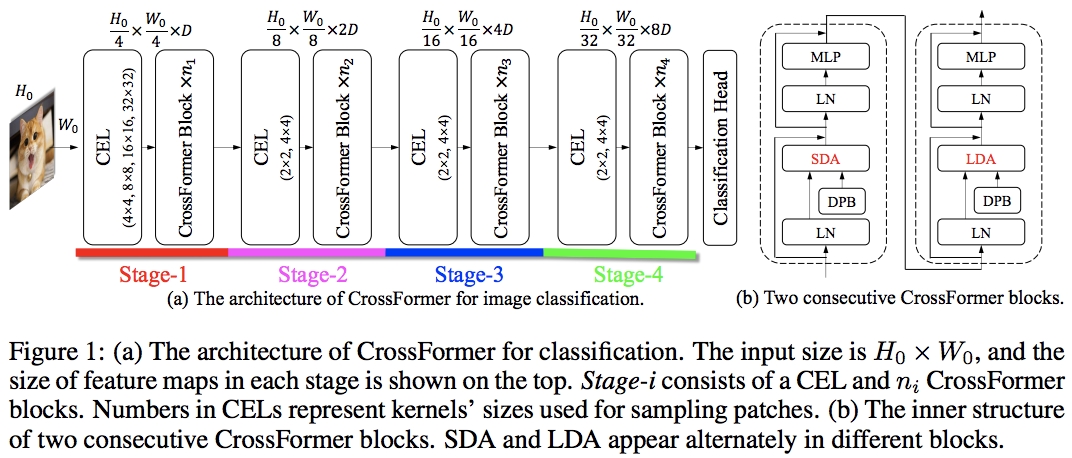
CrossFormer是一种结合了局部和全局注意力机制的网络架构,旨在提高视觉任务的性能。它通过交替的局部和全局注意力机制,实现了对图像信息的有效捕捉和整合。这种创新的设计思路,使得CrossFormer在性能上超越了诸如PVT和Swin等网络。
二、全局注意力机制
CrossFormer中的全局注意力机制是其核心创新之一。该机制在窗口维度上完成全局信息的整合,旨在捕获整个图像范围内的依赖关系。这种设计降低了模型的复杂性,并提高了效率。更重要的是,全局注意力机制能够捕捉到图像中跨尺度的信息,这对于图像分类和视觉任务至关重要。
三、跨尺度嵌入层
CrossFormer引入了跨尺度嵌入层的概念。这一设计证明了其作为一种可以改进所有视觉转换器的通用骨干网络的潜力。通过跨尺度嵌入层,网络能够同时处理不同尺度的信息,从而提高对不同大小目标的感知能力。
四、动态相对位置偏差
为了进一步提高网络的性能,CrossFormer还设计了动态相对位置偏差。这一设计允许网络更好地处理不同分辨率的图像,提高了模型的泛化能力。在图像分类任务中,这一特性使得CrossFormer能够更准确地识别出图像中的对象及其位置。
五、仅在PyTorch框架下的实现
值得一提的是,CrossFormer目前仅限于在PyTorch框架下实现。PyTorch的灵活性和动态图特性使得实现这种复杂的网络架构变得更为容易。这也为研究人员和开发者提供了更多的便利,促进了CrossFormer的应用和推广。
六、实际应用与性能表现
在实际应用中,CrossFormer表现出了出色的性能。在图像分类任务中,它取得了显著的效果,显著超越了PVT和Swin等网络。此外,在目标检测、语义分割等视觉任务中,CrossFormer也展现出了其优越的性能。
七、总结与展望
CrossFormer作为一种新兴的网络架构,在图像分类和视觉任务中表现出了强大的性能。其结合局部和全局注意力机制的设计思路,以及跨尺度嵌入层和动态相对位置偏差等创新设计,使得它在性能上超越了现有的网络。尽管目前仅限于在PyTorch框架下实现,但这并不妨碍其在视觉计算领域的研究和应用。未来,我们期待CrossFormer能够在更多的视觉任务中展现其潜力,并推动计算机视觉领域的发展。
具体的代码,程序如下地址:http://wekup.cn/681596231987.html
















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









