






收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
基于LSTM(长短期记忆网络)算法的共享单车需求预测研究是一个结合了时间序列分析和深度学习技术的课题。以下是对该研究的详细阐述:
一、研究背景与意义
随着共享单车的普及和市场竞争的加剧,准确预测共享单车的需求对于共享单车企业优化资源配置、提高运营效率具有重要意义。LSTM算法作为一种特殊的循环神经网络(RNN),擅长处理时间序列数据中的长期依赖关系,因此被广泛应用于共享单车需求预测中。
二、LSTM算法原理
LSTM是一种改进的RNN,其设计旨在解决传统RNN在处理长期依赖问题时的局限。LSTM通过引入门控机制(包括遗忘门、输入门和输出门)来控制信息的流动,从而保持信息的长期依赖性和稳定性。这些门控机制使得LSTM在处理长期序列数据时能够更有效地捕捉和利用信息。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
环境:Python3.8.5、Tensorflow2.10
————————————————
二、功能介绍
数据收集:收集共享单车租赁系统的历史数据,包括租赁数量、时间信息(如日期、小时)、天气状况(如温度、湿度、风速等)、地理位置等。
数据预处理:处理缺失值、异常值,对数据进行归一化或标准化,以适应LSTM的要求。同时,根据业务需求和数据特点,提取并转换有用的特征,如进行one-hot编码或时间编码等。
网络结构设计:构建一个包含LSTM层的神经网络模型。该模型通常包括输入层、LSTM层、全连接层和输出层。其中,LSTM层负责处理时序数据并捕捉长期依赖关系;全连接层将LSTM层的输出映射到最终预测结果;输出层则生成预测结果。
模型训练与优化:使用训练数据对LSTM模型进行训练,并通过优化算法(如Adam、RMSprop等)调整网络参数以最小化预测误差。同时,采用均方误差(MSE)或其他适合回归任务的损失函数来评估模型的性能。
验证与测试:利用验证集调整模型超参数(如LSTM层数、隐藏单元数、学习率等),并用测试集评估模型的最终性能。常用的评估指标包括均方根误差(RMSE)、平均绝对误差(MAE)等。
三、核心代码
部分代码:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
cycling_datas = pd.read_csv('data/hour.csv')
# print(cycling_datas)
# 首先看下读到的数据、显示前20天的骑行人数数据
x = cycling_datas["dteday"][:24 * 20]
y = cycling_datas["cnt"][:24 * 20]
plt.plot(x, y)
plt.xlabel("date") # 日期
plt.ylabel("Number of riders") # 骑行人数
plt.xticks(rotation=90) # 横坐标每个值旋转90度
plt.savefig("./result/日期-骑行人数图.png")
plt.show()
plt.close()
# 显示温度的骑行数据
# 实际温度值 = 温度值(概率)* 温度最大值41
plt.scatter(x=cycling_datas['temp'] * 41, y=cycling_datas['cnt'], c='#7f9eb2', marker='+')
plt.xlabel("Actual temperature") # 实际温度
plt.ylabel("Number of riders") # 骑行人数
plt.savefig("./result/温度-骑行人数图.png")
plt.show()
plt.close()
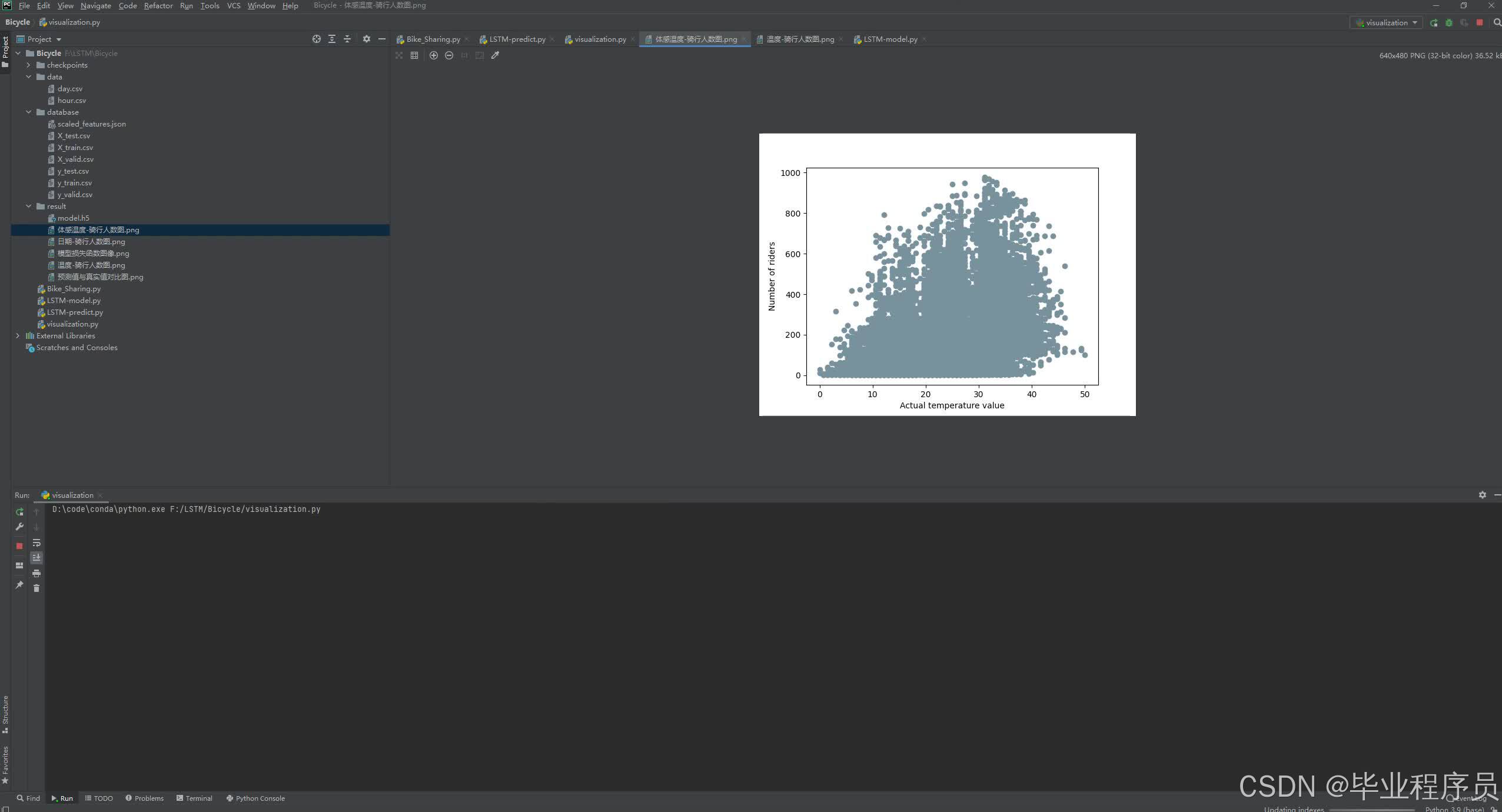
# 显示感觉温度的骑行数据
# 实际感觉温度值 = 体感温度值(概率)* 感觉温度最大值50
plt.scatter(x=cycling_datas['atemp'] * 50, y=cycling_datas['cnt'], c='#77919d', marker='o')
plt.xlabel("Actual temperature value") # 实际感觉温度值
plt.ylabel("Number of riders") # 骑行人数
plt.savefig("./result/体感温度-骑行人数图.png")
plt.show()
plt.close()
# 显示风速的骑行数据
# 实际风速值 = 风速值(概率)* 风速最大值67
plt.scatter(x=cycling_datas['windspeed'] * 67, y=cycling_datas['cnt'], c='#274c5e', marker='^')
plt.xlabel("Actual wind speed value") # 实际风速值
plt.ylabel("Number of riders") # 骑行人数
plt.savefig("./result/风速-骑行人数图.png")
plt.show()
plt.close()
# 显示湿度的骑行数据
# 实际湿度值 = 湿度值(概率)* 湿度最大值100
plt.scatter(x=cycling_datas['hum'] * 100, y=cycling_datas['cnt'], c='#274c5e', marker='*')
plt.xlabel("Actual humidity value") # 实际湿度值
plt.ylabel("Number of riders") # 骑行人数
plt.savefig("./result/湿度-骑行人数图.png")
plt.show()
plt.close()
# 分析相关性
# 我们来看下温度、体感温度、临时骑行用户、已注册用户、湿度、风速和总骑行人数的相关性热图
# corr()函数表示计算值得相关性。它的完整单词是correlation。
corrMatt = cycling_datas[["temp", "atemp", "casual", "registered", "hum", "windspeed", "cnt"]].corr()
mask = np.array(corrMatt)
mask[np.tril_indices_from(mask)] = False
# 用彩色的矩形绘制矩形的图就是热图
# heatmap()函数的参数说明
# 参数1:二维的矩形数据集
# 参数2:mask表示如果数据中有缺失值的cell就自动被屏蔽
# 参数3:square如果是True,表示cell的宽和高相等
# 参数4:annot表示在每个cell上标出实际的数值
sns.heatmap(corrMatt, mask=mask, square=True, annot=True)
plt.savefig('./result/热力图.png')
plt.show()
plt.close()
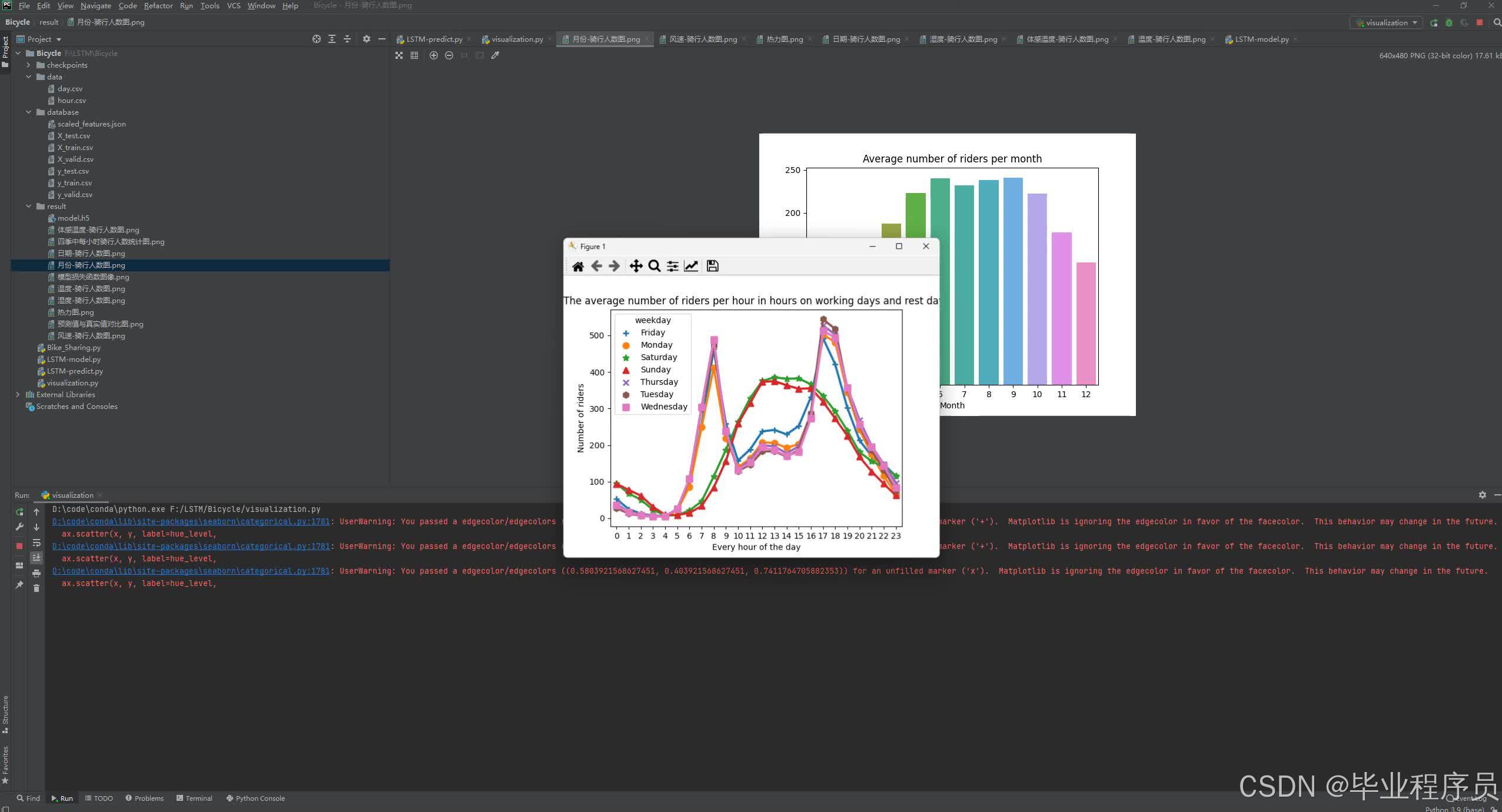
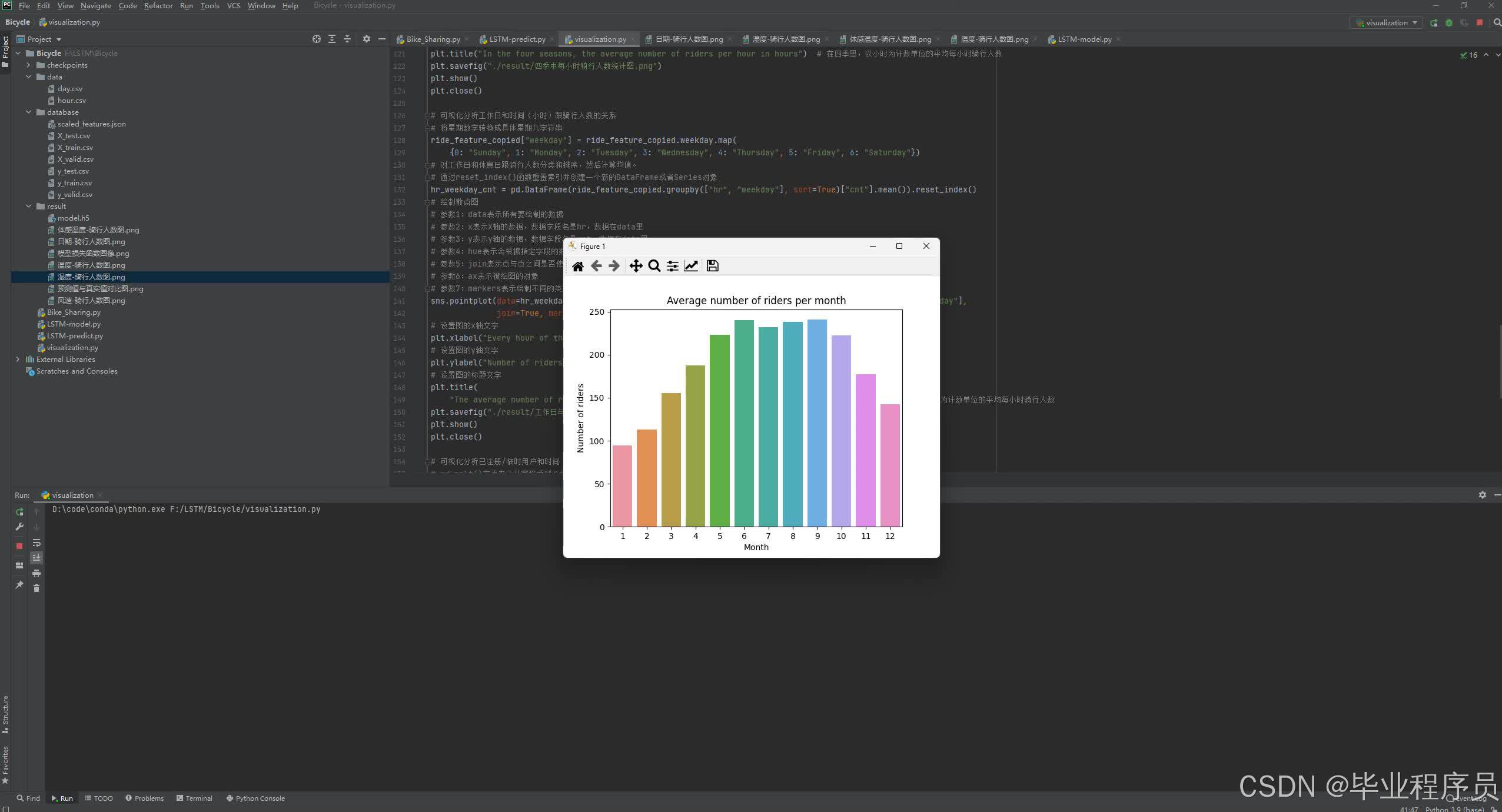
# 可视化分析月份和骑行人数的关系
# 对每个月份的骑行人数分类,然后计算均值。
# 通过reset_index()函数重置索引并创建一个新的DataFrame或者Series对象
mnth_cnt = pd.DataFrame(cycling_datas.groupby("mnth")["cnt"].mean()).reset_index()
# 对DataFrame根据月份进行从小到大排序,使用ascending参数
mnth_cnt = mnth_cnt.sort_values(by="mnth", ascending=True)
# 月份数字
mnth_cnt['mnth'] = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12"]
# 绘制柱状图
# 参数data表示,x和y的列字段名在原始数据的mnth_cnt里,ax就是绘图的对象
# 参数1:data表示所有要绘制的数据
# 参数2:x表示X轴的数据,数据字段名是mnth,数据在data里
# 参数3:y表示y轴的数据,数据字段名是cnt,数据在data里
# 参数4:ax表示被绘图的对象
sns.barplot(data=mnth_cnt, x='mnth', y='cnt')
# 设置图的x轴文字
plt.xlabel("Month") # 月份
# 设置图的y轴文字
plt.ylabel("Number of riders") # 骑行人数
# 设置图的标题文字
plt.title("Average number of riders per month") # 平均每月骑行人数
plt.savefig("./result/月份-骑行人数图.png")
plt.show()
plt.close()
# 可视化分析季节和时间(小时)跟骑行人数的关系
# 将季节数字转换成具体的季节字符串
ride_feature_copied = cycling_datas.copy()
ride_feature_copied["season"] = ride_feature_copied.season.map({1: "Spring", 2: "Summer", 3: "Autumn", 4: "Winter"})
# 对每个季节里的每天每具体小时的骑行人数分类和排序,然后计算均值。
# 通过reset_index()函数重置索引并创建一个新的DataFrame或者Series对象
hr_cnt = pd.DataFrame(ride_feature_copied.groupby(["hr", "season"], sort=True)["cnt"].mean()).reset_index()
# 绘制散点图
# 参数1:data表示所有要绘制的数据
# 参数2:x表示X轴的数据,数据字段名是hr,数据在data里
# 参数3:y表示y轴的数据,数据字段名是cnt,数据在data里
# 参数4:hue表示会根据指定字段的数据的个数来绘制色彩的线和点
# 参数5:join表示点与点之间是否使用线来绘制连接上
# 参数6:ax表示被绘图的对象
# 参数7:markers表示绘制不同的类别用不同的标记符号
sns.pointplot(data=hr_cnt, x=hr_cnt["hr"], y=hr_cnt["cnt"], hue=hr_cnt["season"], join=True,
markers=['+', 'o', '*', '^'])
# 设置图的x轴文字
plt.xlabel("Every hour of the day") # 一天里的每小时
# 设置图的y轴文字
plt.ylabel("Number of riders") # 骑行人数
# 设置图的顶部标题文字
plt.title("In the four seasons, the average number of riders per hour in hours") # 在四季里,以小时为计数单位的平均每小时骑行人数
plt.savefig("./result/四季中每小时骑行人数统计图.png")
plt.show()
plt.close()
# 可视化分析工作日和时间(小时)跟骑行人数的关系
# 将星期数字转换成具体星期几字符串
ride_feature_copied["weekday"] = ride_feature_copied.weekday.map(
{0: "Sunday", 1: "Monday", 2: "Tuesday", 3: "Wednesday", 4: "Thursday", 5: "Friday", 6: "Saturday"})
# 对工作日和休息日跟骑行人数分类和排序,然后计算均值。
# 通过reset_index()函数重置索引并创建一个新的DataFrame或者Series对象
hr_weekday_cnt = pd.DataFrame(ride_feature_copied.groupby(["hr", "weekday"], sort=True)["cnt"].mean()).reset_index()
# 绘制散点图
# 参数1:data表示所有要绘制的数据
# 参数2:x表示X轴的数据,数据字段名是hr,数据在data里
# 参数3:y表示y轴的数据,数据字段名是cnt,数据在data里
# 参数4:hue表示会根据指定字段的数据的个数来绘制色彩的线和点
# 参数5:join表示点与点之间是否使用线来绘制连接上
# 参数6:ax表示被绘图的对象
# 参数7:markers表示绘制不同的类别用不同的标记符号
sns.pointplot(data=hr_weekday_cnt, x=hr_weekday_cnt["hr"], y=hr_weekday_cnt["cnt"], hue=hr_weekday_cnt["weekday"],
join=True, markers=['+', 'o', '*', '^', 'x', 'h', 's'])
# 设置图的x轴文字
plt.xlabel("Every hour of the day") # 一天里的每小时
# 设置图的y轴文字
plt.ylabel("Number of riders") # 骑行人数
# 设置图的标题文字
plt.title(
"The average number of riders per hour in hours on working days and rest days") # 在工作日和休息日里,以小时为计数单位的平均每小时骑行人数
plt.savefig("./result/工作日与休息天每小时骑行人数统计.png")
plt.show()
plt.close()
# 可视化分析已注册/临时用户和时间(小时)跟骑行人数的关系
# pd.melt()方法表示从宽格式到长格式的转换数据,可选择设置标识符变量
# 这里的标识符是字段hr,变量字段是casual或registered的新字段名variable,而值是value
hr_cas_reg_data = pd.melt(cycling_datas[["hr", "casual", "registered"]], id_vars=['hr'],
value_vars=['casual', 'registered'])
# print(hr_cas_reg_data)
# 然后通过reset_index()函数重置索引并创建一个新的DataFrame或者Series对象
# variable就是表示已注册/临时用户,而value就是表示骑行人数
hr_cas_reg_data = pd.DataFrame(hr_cas_reg_data.groupby(["hr", "variable"], sort=True)["value"].mean()).reset_index()
# print(hr_cas_reg_data)
# 绘制散点图
# 参数1:data表示所有要绘制的数据
# 参数2:x表示X轴的数据,数据字段名是hr,数据在data里
# 参数3:y表示y轴的数据,数据新字段名是value,其实就是骑行个数,数据在data里
# 参数4:hue表示会根据指定字段的数据的种类个数来绘制色彩的线和点
# 参数5:hue_order表示绘制的色彩的顺序
# 参数6:join表示点与点之间是否使用线来绘制连接上
# 参数7:ax表示被绘图的对象
# 参数8:markers表示绘制不同的类别用不同的标记符号
sns.pointplot(data=hr_cas_reg_data, x=hr_cas_reg_data["hr"], y=hr_cas_reg_data["value"],
hue=hr_cas_reg_data["variable"], hue_order=["casual", "registered"], join=True, markers=['p', 's'])
# 设置图的x轴文字
plt.xlabel("hour")
# 设置图的y轴文字
plt.ylabel("Number of riders")
# 设置图的标题文字
plt.title("Number of riders per hour")
plt.savefig("./result/注册与临时用户一天中每小时骑行人数图.png")
plt.close()
四、效果图
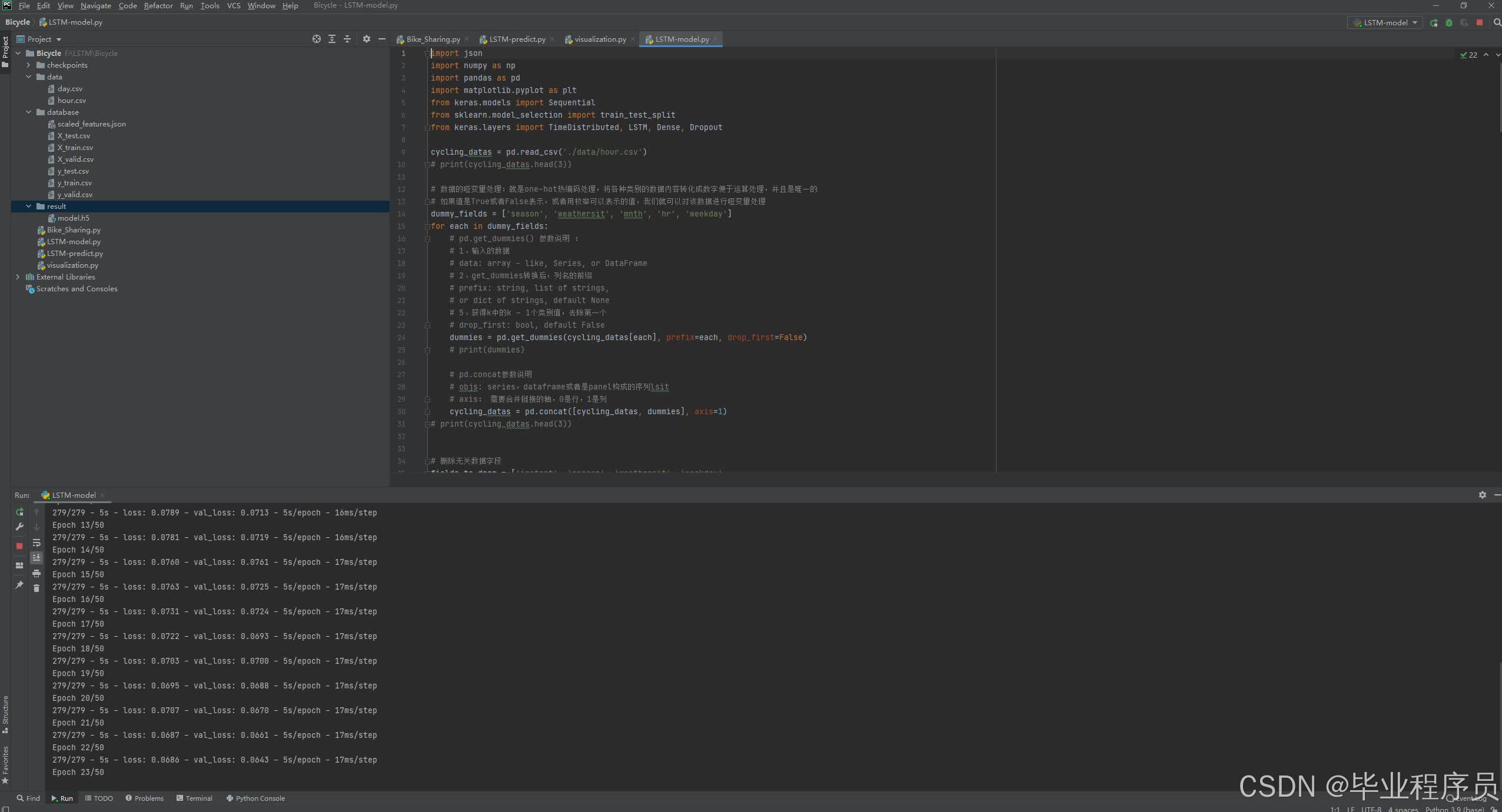
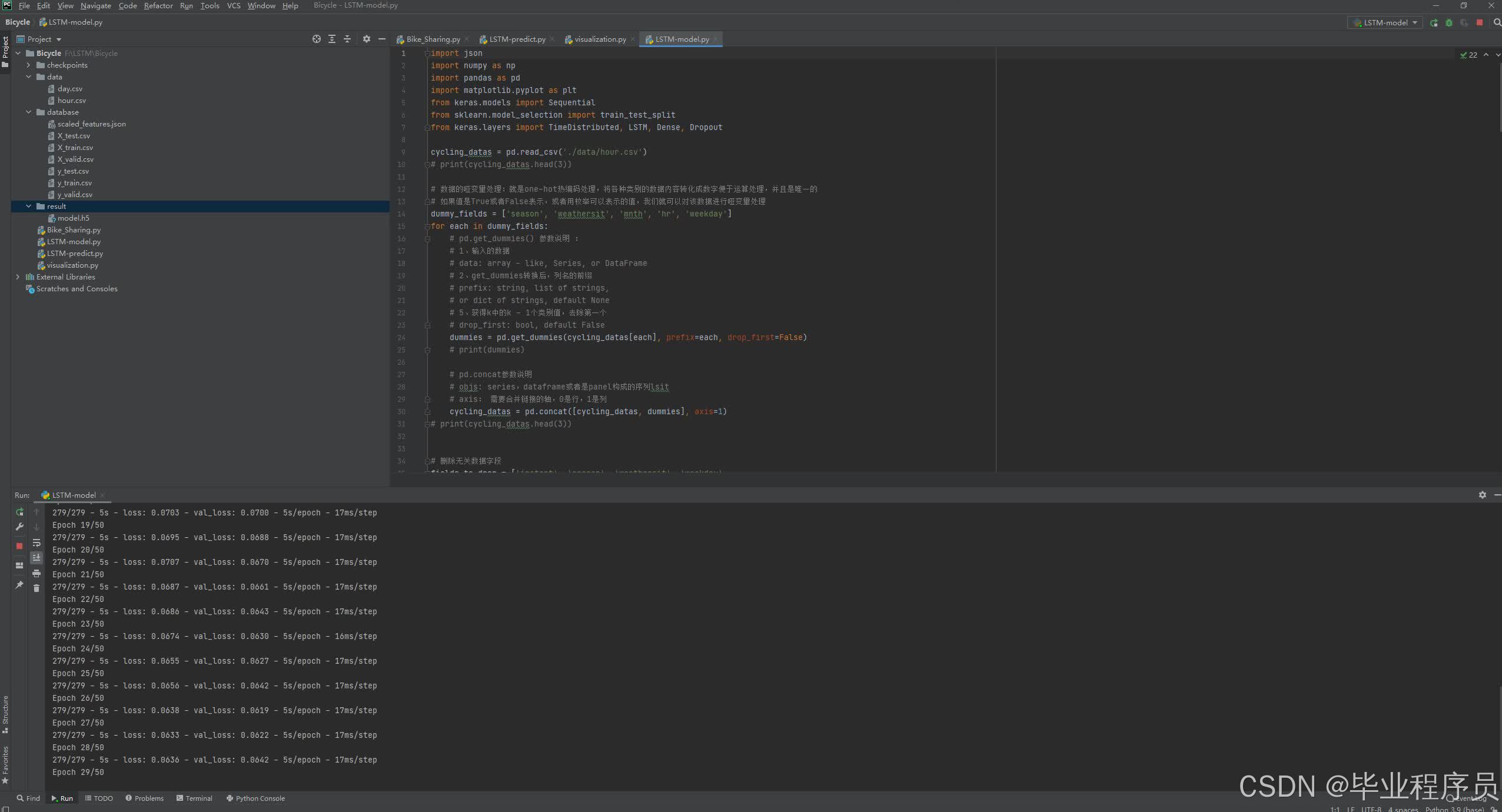
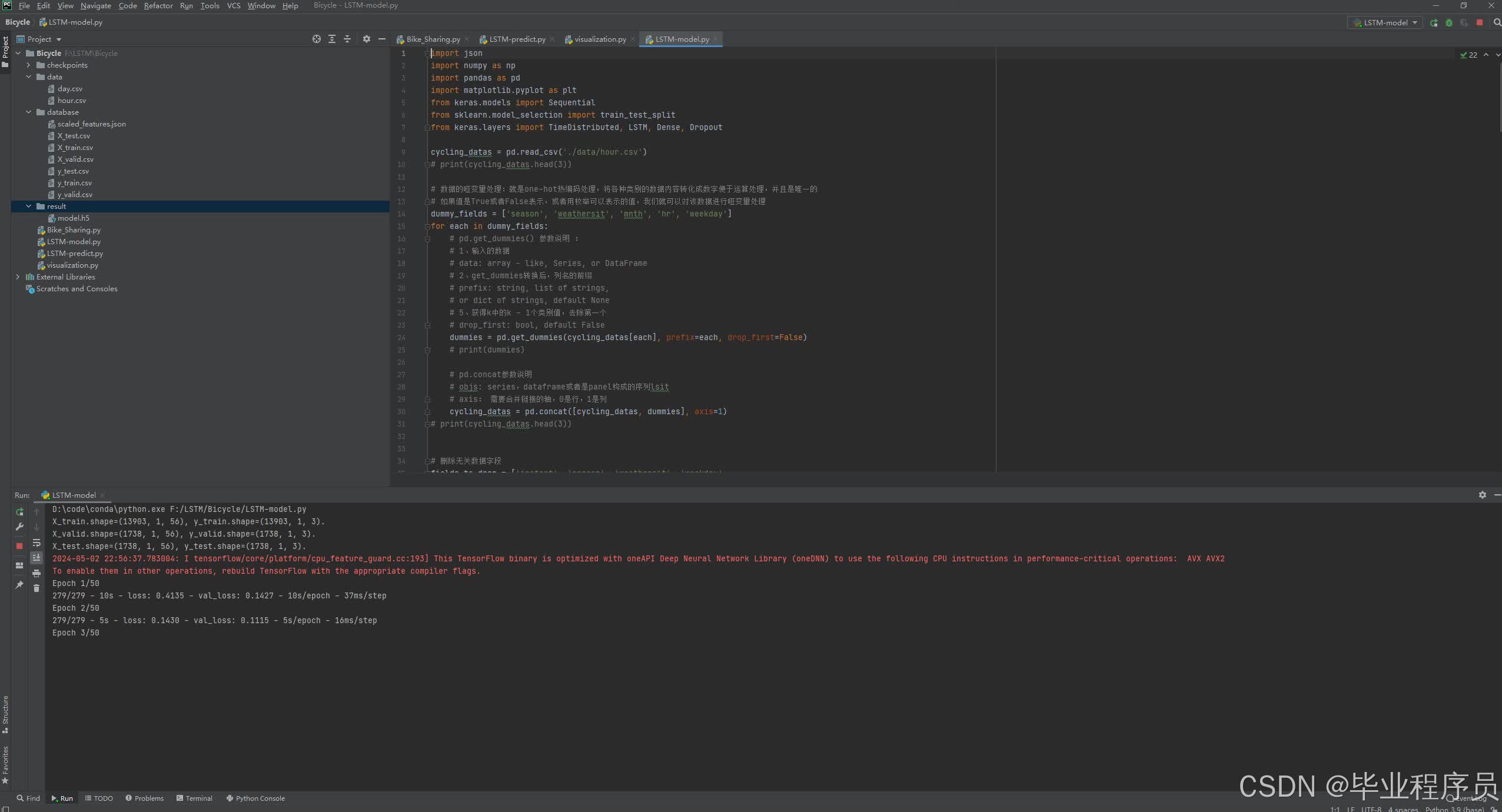
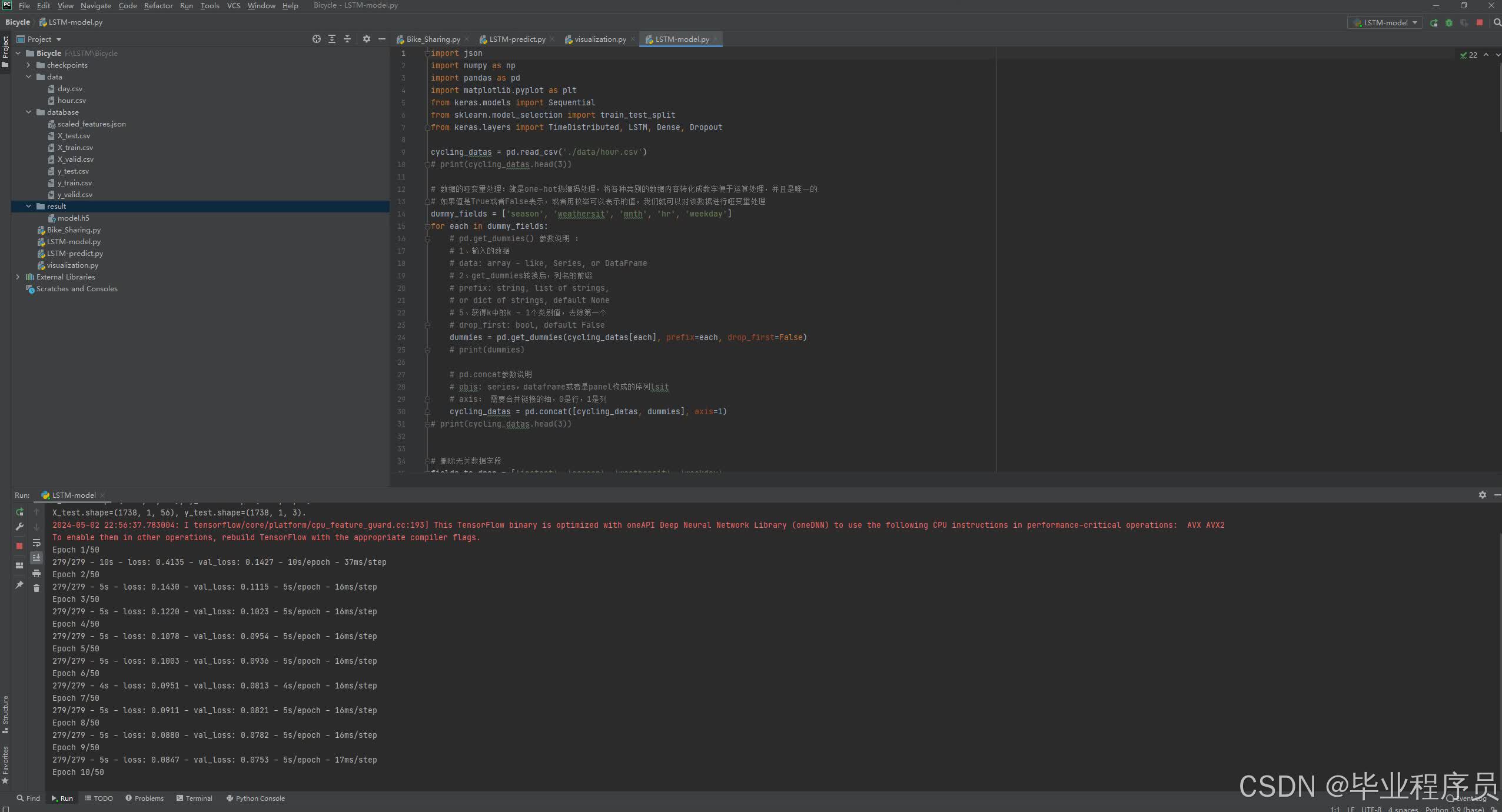
五、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

















 3196
3196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









