







实例分割和跟踪:深入解析与应用
什么是实例分割?
实例分割是一种计算机视觉任务,它不仅识别图像中的物体类别,还精确勾勒出每个物体的轮廓。这为理解图像的空间分布提供了详细的见解。与语义分割不同的是,实例分割对每个物体进行唯一标记和精确划分,这对物体检测、医学成像等任务至关重要。

在实例分割中,算法不仅要区分不同的类别,还要区分同一类别的不同个体。例如,在一张包含多只猫的照片中,实例分割不仅能告诉你哪些像素属于“猫”这一类别,还能明确指出每一只猫的具体位置和形状。
实例分割的应用场景
- 安防监控:用于人群管理、异常行为检测。
- 自动驾驶:车辆、行人和其他障碍物的精确识别。
- 医疗影像分析:肿瘤、病变组织的精确定位。
- 零售分析:店内顾客行为追踪,货架商品监测。
实例分割与对象跟踪结合的优势
当实例分割与对象跟踪相结合时,系统可以在连续的视频帧中保持对同一物体的一致标识。这种组合提供了以下优势:
- 持续性识别:即使物体暂时离开视野或被遮挡,也能在重新出现时正确识别。
- 轨迹重建:生成物体移动的完整轨迹,便于后续分析。
- 复杂场景处理:在拥挤环境中有效区分多个相似物体。
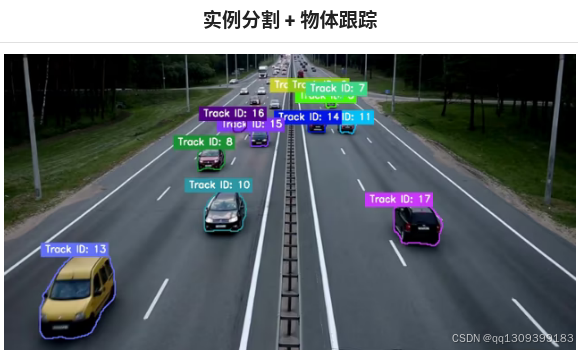
实现示例
下面是一个使用 YOLO11 进行实例分割和对象跟踪的 Python 示例。为了简化说明,我们将省略具体框架名称,专注于实现逻辑和技术细节。
import cv2
# 加载分割模型
model = YOLO("yolo11n-seg.pt") # 使用分割模型
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# 初始化视频写入器
out = cv2.VideoWriter("instance-segmentation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
print("Video frame is empty or video processing has been successfully completed.")
break
# 执行预测
annotator = Annotator(im0, line_width=2)
# 检查是否有掩码结果
if results[0].masks is not None:
clss = results[0].boxes.cls.cpu().tolist()
masks = results[0].masks.xy
# 绘制分割框和标签
for mask, cls in zip(masks, clss):
color = colors(int(cls), True)
txt_color = annotator.get_txt_color(color)
annotator.seg_bbox(mask=mask, mask_color=color, label=model.names[int(cls)], txt_color=txt_color)
# 写入输出视频
out.write(im0)
cv2.imshow("instance-segmentation", im0)
# 按 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord("q"):
break
out.release()
cap.release()
cv2.destroyAllWindows()
seg_bbox 参数详解
| 名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
mask | array | None | 分割掩码坐标,定义了物体边界。 |
mask_color | RGB | (255, 0, 255) | 每个分割框的屏蔽颜色,用于区分不同物体。 |
label | str | None | 分段对象的标签,显示物体所属类别。 |
txt_color | RGB | None | 被分割和跟踪物体的标签颜色,确保文本清晰可见。 |
实例分割与对象跟踪的区别
- 实例分割:识别并勾勒图像中的单个物体,赋予每个物体独特的标签和遮罩。
- 对象跟踪:在实例分割的基础上延伸,能够在不同帧中为物体分配一致的标签,实现对同一物体的连续追踪。
两者结合可以提供更加丰富的信息,不仅知道当前帧中有哪些物体及其位置,还能了解它们随时间的变化情况。
为什么选择 YOLO11 而不是其他模型?
YOLO11 相比其他模型如 Mask R-CNN 或 Faster R-CNN,具有以下几个显著优点:
- 速度与精度平衡:YOLO11 在保持高精度的同时,能够以实时的速度处理图像。
- 易于部署:模型轻量化设计,方便跨平台部署。
- 社区支持:活跃的开发者社区,提供了丰富的教程和文档支持。
- 端到端训练:从数据预处理到模型训练,再到推理,整个流程简洁高效。

实现对象跟踪
要实施对象跟踪,可以通过 model.track 方法,并确保每个对象的 ID 在各帧之间分配一致。以下是简化的代码示例:
while True:
ret, im0 = cap.read()
if not ret:
break
annotator = Annotator(im0, line_width=2)
results = model(im0, persist=True)
if results[0].boxes.id is not None and results[0].masks is not None:
masks = results[0].masks.xy
track_ids = results[0].boxes.id.int().cpu().tolist()
for mask, track_id in zip(masks, track_ids):
annotator.seg_bbox(mask=mask, mask_color=colors(track_id, True), track_label=str(track_id))
out.write(im0)
cv2.imshow("instance-segmentation-object-tracking", im0)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
数据集支持
对于训练模型(如分割和跟踪),有许多公开可用的数据集可以选择。这些数据集涵盖了各种应用场景,包括但不限于:
- COCO 数据集:广泛用于目标检测和实例分割任务。
- Cityscapes 数据集:特别适合城市环境下的图像分割和物体识别。
- KITTI 数据集:适用于自动驾驶领域的研究,包含大量真实道路场景的数据。
通过利用这些数据集,可以有效地训练和验证模型性能,确保其在实际应用中的可靠性和准确性。
结论
实例分割和对象跟踪是现代计算机视觉技术的重要组成部分,它们为理解和处理复杂场景提供了强大的工具。无论是安防监控、自动驾驶还是医疗影像分析,这项技术都能发挥重要作用。通过上述示例和配置,您可以快速上手并在项目中应用这些先进的视觉处理方法。如果有任何问题或需要进一步的帮助,请随时联系我。


















 7957
7957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









