







如何v处理新能源充电站负荷预测数据集并应用AI算法进行预测 可通过数据加载、预处理、特征工程等进行处理 通过大数据分析和机器学习,AI模型能够根据历史能耗数据、天气情况、对充电站的能耗进行精准预测等
——新能源充电站负荷预测数据集
文章目录
【数据背景】随着新能源汽车的快速发展,充电站作为支撑这一变革的重要基础设施,其能耗管理显得尤为关键。为了实现更高效的能源利用和优化运营成本,可以引入先进的AI算法,对充电站的能耗进行精准预测。通过大数据分析和机器学习,AI模型能够根据历史能耗数据、天气情况、交通流量等多种因素,预测未来的能耗趋势。这不仅有助于提升充电站的能源使用效率,还能为新能源汽车用户提供更加稳定可靠的充电服务。
【文件目录】包含以下所示的数据文件:
Data Files:数据文件夹
- Boulder_charging_load.csv
- EVnetNL_charging_load.csv
- PALO_charging_load.csv
- Perth1_charging_load.csv
- Perth2_charging_load.csv
MetaProbformer:参考项目代码 - data
- datasets
- exp
- fig
- models
- utils
- main.py
- README.md
- requirements.txt
【数据说明】该数据集为已发表《MetaProbformer for Charging Load Probabilistic Forecasting of Electric Vehicle Charging Stations》中的实验所采用的电动汽车充电站负荷预测数据集,共包含4个真实的充电负荷数据集:Boulder、EVnetNL、PALO和Perth。每个数据集都包含每个充电事件的开始和结束时间以及总能耗kWh,然后将每个原始数据转换为相应的数据集,包含1hr时间颗粒度内的平均充电负荷kW。
Boulder数据集的起始时间为2018-1-1 0:00,结束时间为2020-7-31 23:00,包含31个月的充电负荷数据。
EVnetNL数据集的起始时间为2019-1-1 0:00,结束时间为2019-12-31 23:00,包含12个月的充电负荷数据。
PALO数据集的起始时间为2011-7-29 0:00,结束时间为2011-12-5 16:00,包含4个月的充电负荷数据。
Perth数据集的起始时间为2016-9-1 0:00,结束时间为2018-8-31 23:00,包含24个月的充电负荷数据。
以下文字及代码仅供参考。
处理新能源充电站负荷预测数据集并应用AI算法进行预测,通过以下步骤系统地进行。我们将涵盖数据加载、预处理、特征工程、模型选择与训练、评估和部署。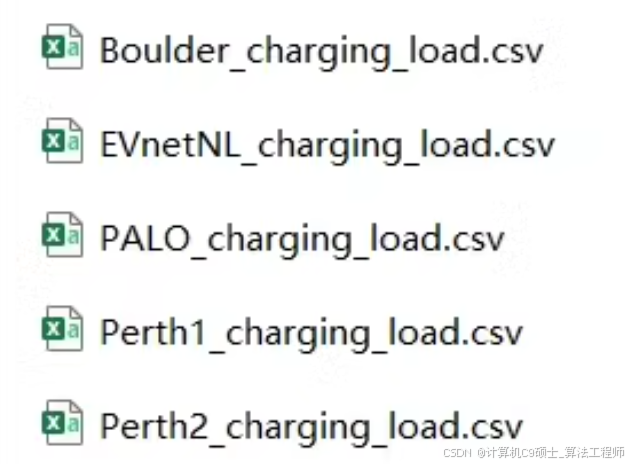
1. 数据理解与准备
加载数据
首先,我们需要加载并检查原始充电负荷数据文件。
import pandas as pd
# 定义函数加载CSV文件
def load_charging_load_data(file_path):
return pd.read_csv(file_path, parse_dates=['timestamp'])
# 加载各个充电站的负荷数据
data_files = {
'Boulder': 'path/to/Data_Files/Boulder_charging_load.csv',
'EVnetNL': 'path/to/Data_Files/EVnetNL_charging_load.csv',
'PALO': 'path/to/Data_Files/PALO_charging_load.csv',
'Perth1': 'path/to/Data_Files/Perth1_charging_load.csv',
'Perth2': 'path/to/Data_Files/Perth2_charging_load.csv'
}
charging_loads = {name: load_charging_load_data(path) for name, path in data_files.items()}
# 查看样本数据
for name, df in charging_loads.items():
print(f"Data from {name}:")
print(df.head())
print("\n")
2. 数据预处理
处理缺失值和异常值
确保所有时间戳连续,并处理任何缺失或异常的数据点。
def preprocess_data(df):
# 确保时间戳连续
df.set_index('timestamp', inplace=True)
df = df.resample('H').mean().interpolate(method='linear') # 按小时重采样并线性插值填充缺失值
# 处理异常值(例如,通过设置上下限)
df['load_kW'] = df['load_kW'].clip(lower=0) # 负荷不能为负数
return df.reset_index()
# 应用预处理到所有数据集
preprocessed_data = {name: preprocess_data(df) for name, df in charging_loads.items()}
特征工程
创建额外的特征以辅助预测,如时间特征、天气信息、节假日等。
from datetime import datetime
def add_features(df):
df['hour'] = df['timestamp'].dt.hour
df['day_of_week'] = df['timestamp'].dt.dayofweek
df['month'] = df['timestamp'].dt.month
df['is_weekend'] = df['day_of_week'].isin([5, 6]).astype(int)
# 添加天气信息和其他外部数据(假设已有这些数据)
# df = df.merge(weather_data, on='timestamp', how='left')
return df
# 应用特征工程到所有数据集
featured_data = {name: add_features(df) for name, df in preprocessed_data.items()}
3. 模型选择与训练
我们可以使用时间序列预测模型,如LSTM、GRU或Transformer架构(如MetaProbformer),来进行充电负荷预测。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
# 创建LSTM模型作为示例(可以根据需要选择其他模型)
def build_lstm_model(input_shape):
model = Sequential([
LSTM(50, return_sequences=True, input_shape=input_shape),
Dropout(0.2),
LSTM(50, return_sequences=False),
Dropout(0.2),
Dense(25),
Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
return model
# 准备训练数据(假设我们选择了Boulder数据集作为例子)
df_boulder = featured_data['Boulder']
train_size = int(len(df_boulder) * 0.8)
train_data = df_boulder.iloc[:train_size]
test_data = df_boulder.iloc[train_size:]
# 将数据转换为适合LSTM输入的形式
def create_dataset(df, time_step=60):
X, y = [], []
for i in range(len(df) - time_step - 1):
X.append(df[['load_kW', 'hour', 'day_of_week', 'month', 'is_weekend']].iloc[i:(i + time_step)].values)
y.append(df['load_kW'].iloc[i + time_step])
return np.array(X), np.array(y)
time_step = 60 # 使用过去60个小时的数据来预测下一个小时的负荷
X_train, y_train = create_dataset(train_data, time_step)
X_test, y_test = create_dataset(test_data, time_step)
# 构建并训练模型
model = build_lstm_model((X_train.shape[1], X_train.shape[2]))
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=64)
4. 模型评估与优化
评估模型性能,并尝试调整超参数或引入更多特征来提高模型的表现。
from sklearn.metrics import mean_squared_error
# 在测试集上评估模型
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
5. 测试与推理
在测试集上评估模型表现,并保存最佳模型用于后续的推理任务。
# 显示预测结果
plt.figure(figsize=(12, 6))
plt.plot(y_test, label='True Load')
plt.plot(predictions, label='Predicted Load')
plt.title('Charging Load Prediction vs True Values')
plt.legend()
plt.show()
注意事项
- 持续改进:随着新数据的积累,模型可能需要不断更新和优化。
- 解释性:为了提高模型的信任度,可以使用SHAP值或LIME等工具来解释模型决策过程。
- 外部数据源:考虑引入更多的外部数据源,例如天气预报、交通流量等,以提高预测准确性。
特别注意事项 - 时间序列预测
对于时间序列预测,以下是额外的建议:
-
周期性和趋势:分析数据中的周期性和长期趋势,并根据需要调整模型结构或引入特定的特征。
-
多步预测:如果需要预测未来多个时间点的负荷,可以采用递归或多输出模型策略。
-
季节性因素:考虑到电动汽车充电行为可能受到季节性因素的影响(如夏季和冬季的不同需求模式),可以在模型中加入这些因素。
-
外部变量:如天气条件、节假日、特殊事件等,都可能影响充电站的负荷。确保有足够的外部数据来捕捉这些变化。
-
模型选择:根据具体需求选择合适的模型。例如,MetaProbformer结合了元学习和概率预测的优点,适用于不确定性较高的场景。


















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









