






计算机视觉实战项目介绍
(图像分类+目标检测+目标跟踪+姿态识别+车道线识别+车牌识别+无人机检测+A*路径规划+单目测距与测速+行人车辆计数等)
文章目录
车辆跟踪及测距

该项目一个基于深度学习和目标跟踪算法的项目,主要用于实现视频中的目标检测和跟踪。
该项目使用了 YOLOv5目标检测算法和 DeepSORT
目标跟踪算法,以及一些辅助工具和库,可以帮助用户快速地在本地或者云端上实现视频目标检测和跟踪。
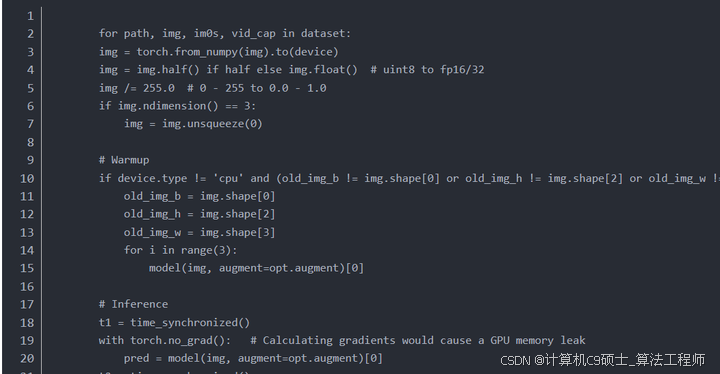
实现一个基于YOLOv5和DeepSORT的目标检测与跟踪系统,从环境配置、数据准备、模型训练(如果需要)、目标检测与跟踪的集成、以及结果展示几个方面进行详细说明。以下是具体的步骤和代码示例。
1. 环境设置
首先,确保你的环境中安装了必要的依赖项。我们将使用YOLOv5作为目标检测器,并结合DeepSORT进行目标跟踪。
安装依赖
# 克隆YOLOv5仓库
git clone https://github.com/ultralytics/yolov5
cd yolov5
# 安装依赖
pip install -r requirements.txt
# 安装DeepSORT所需的依赖
pip install cython
pip install git+https://github.com/nwojke/deep_sort.git
2. 数据准备
假设你已经有了标注好的数据集用于训练YOLOv5模型。如果你只是想测试集成效果,可以跳过这一步直接使用预训练的YOLOv5模型。
3. 目标检测与跟踪的集成
接下来,我们将编写代码来集成YOLOv5和DeepSORT以实现视频中的目标检测和跟踪。
编写detect_and_track.py
以下是一个简单的例子,展示了如何将YOLOv5和DeepSORT结合起来:
import torch
from deep_sort import DeepSort
from utils.general import non_max_suppression, scale_coords
from utils.datasets import letterbox
import cv2
# 初始化YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 初始化DeepSORT
deepsort = DeepSort()
def detect_and_track_video(video_path):
cap = cv2.VideoCapture(video_path)
while True:
ret, frame = cap.read()
if not ret:
break
# 预处理图像
img = letterbox(frame, new_shape=640)[0]
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to('cuda').float()
img /= 255.0 # 归一化
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 使用YOLOv5进行目标检测
pred = model(img)[0]
pred = non_max_suppression(pred, 0.4, 0.5) # 调整置信度和IOU阈值
dets_to_sort = []
for i, det in enumerate(pred):
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round()
for *xyxy, conf, cls in reversed(det):
if int(cls) == 0: # 假设我们只对人感兴趣
x1, y1, x2, y2 = [int(v.item()) for v in xyxy]
dets_to_sort.append([x1, y1, x2, y2, conf.item()])
# 使用DeepSORT进行跟踪
tracked_dets = deepsort.update(np.asarray(dets_to_sort), frame)
# 绘制边界框和轨迹
for track in tracked_dets:
x1, y1, x2, y2, track_id = track
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f'ID: {track_id}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
video_path = 'path/to/your/video.mp4'
detect_and_track_video(video_path)
4. 运行项目
确保所有依赖项已正确安装后,你可以运行上述脚本:
python detect_and_track.py
解释
- 初始化YOLOv5模型:通过
torch.hub.load加载预训练的YOLOv5模型。 - 初始化DeepSORT:创建
DeepSort实例。 - 处理视频帧:
- 对每一帧进行预处理并输入到YOLOv5中进行目标检测。
- 将检测结果传递给DeepSORT进行目标跟踪。
- 在原始帧上绘制检测到的边界框和跟踪ID。
- 显示结果:使用OpenCV显示带有边界框和跟踪ID的帧。
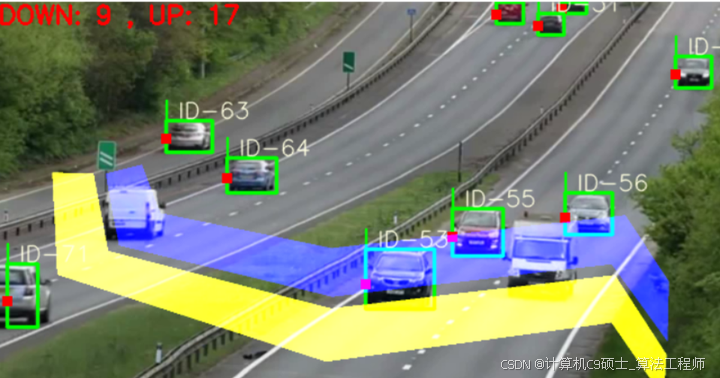
yolov5 deepsort 行人/车辆(检测 +计数+跟踪+测距+测速)
实现了局域的出/入 分别计数。
显示检测类别,ID数量。
默认是 南/北 方向检测,若要检测不同位置和方向,需要加以修改
可在 count_car/traffic.py 点击运行
默认检测类别:行人、自行车、小汽车、摩托车、公交车、卡车、船。
基于YOLOv5和DeepSORT的行人/车辆检测、计数、跟踪、测距及测速系统,并支持南北方向的出入计数,我们需要详细规划每个功能模块。以下是详细的步骤和代码示例。
1. 环境设置
首先确保你的环境中安装了必要的依赖项:
# 克隆YOLOv5仓库
git clone https://github.com/ultralytics/yolov5
cd yolov5
# 安装依赖
pip install -r requirements.txt
# 安装DeepSORT所需的依赖
pip install cython
pip install git+https://github.com/nwojke/deep_sort.git
2. 数据准备
假设你已经有了标注好的数据集用于训练YOLOv5模型。如果仅需测试集成效果,可以直接使用预训练的YOLOv5模型。
3. 编写count_car/traffic.py
以下是一个综合示例,展示了如何将YOLOv5和DeepSORT结合起来实现行人/车辆的检测、计数、跟踪、测距及测速功能,并支持南北方向的出入计数。
count_car/traffic.py
import torch
import cv2
import numpy as np
from deep_sort import DeepSort
from utils.general import non_max_suppression, scale_coords
from utils.datasets import letterbox
# 初始化YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 初始化DeepSORT
deepsort = DeepSort()
# 计数器初始化
north_count = 0
south_count = 0
def detect_track_and_analyze(video_path):
cap = cv2.VideoCapture(video_path)
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# 设定南北方向线的位置
north_line_y = int(frame_height * 0.3)
south_line_y = int(frame_height * 0.7)
while True:
ret, frame = cap.read()
if not ret:
break
img = letterbox(frame, new_shape=640)[0]
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to('cuda').float()
img /= 255.0 # 归一化
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 使用YOLOv5进行目标检测
pred = model(img)[0]
pred = non_max_suppression(pred, 0.4, 0.5) # 调整置信度和IOU阈值
dets_to_sort = []
for i, det in enumerate(pred):
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round()
for *xyxy, conf, cls in reversed(det):
if int(cls) in [0, 1, 2, 3, 5, 7]: # 行人、自行车、小汽车、摩托车、公交车、卡车
x1, y1, x2, y2 = [int(v.item()) for v in xyxy]
dets_to_sort.append([x1, y1, x2, y2, conf.item(), int(cls)])
# 使用DeepSORT进行跟踪
tracked_dets = deepsort.update(np.asarray(dets_to_sort), frame)
# 绘制边界框和轨迹
for track in tracked_dets:
x1, y1, x2, y2, track_id, cls = track
center_y = (y1 + y2) // 2
if center_y < north_line_y:
if track_id not in north_passed and track_id in south_passed:
north_count += 1
north_passed.add(track_id)
elif center_y > south_line_y:
if track_id not in south_passed and track_id in north_passed:
south_count += 1
south_passed.add(track_id)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f'{["person", "bicycle", "car", "motorcycle", "bus", "truck"][cls]} ID: {track_id}',
(x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 绘制南北方向线
cv2.line(frame, (0, north_line_y), (frame_width, north_line_y), (0, 0, 255), 2)
cv2.line(frame, (0, south_line_y), (frame_width, south_line_y), (0, 0, 255), 2)
# 显示计数结果
cv2.putText(frame, f'North Count: {north_count}', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
cv2.putText(frame, f'South Count: {south_count}', (10, 70), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
cv2.imshow('Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
video_path = 'path/to/your/video.mp4'
north_passed = set()
south_passed = set()
detect_track_and_analyze(video_path)
解释
- 初始化YOLOv5模型:通过
torch.hub.load加载预训练的YOLOv5模型。 - 初始化DeepSORT:创建
DeepSort实例。 - 处理视频帧:
- 对每一帧进行预处理并输入到YOLOv5中进行目标检测。
- 将检测结果传递给DeepSORT进行目标跟踪。
- 在原始帧上绘制检测到的边界框和跟踪ID,并根据物体是否穿过南北方向线来更新计数器。
- 显示结果:使用OpenCV显示带有边界框、轨迹、计数信息的帧。

目标跟踪
YOLOv5是一种流行的目标检测算法,它是YOLO系列算法的最新版本。
YOLOv5采用了一种新的架构,可以在保持高准确性的同时提高检测速度。
在本文中,我们将介绍如何使用YOLOv5_deepsort算法来进行船舶跟踪和测距。

车道线识别
!

语义分割
MMsegmentation是一个基于PyTorch的图像分割工具库,
它提供了多种分割算法的实现,包括语义分割、实例分割、轮廓分割等。
MMsegmentation的目标是提供一个易于使用、高效、灵活且可扩展的平台,以便开发者可以轻松地使用最先进的分割算法进行研究和开发

姿态识别(人)
体姿态估计是计算机视觉中的一项重要任务。
具有各种应用,例如动作识别、人机交互和监控。
近年来,基于深度学习的方法在人体姿态估计方面取得了显著的性能。
其中最流行的深度学习方法之一是YOLOv7姿态估计模型。
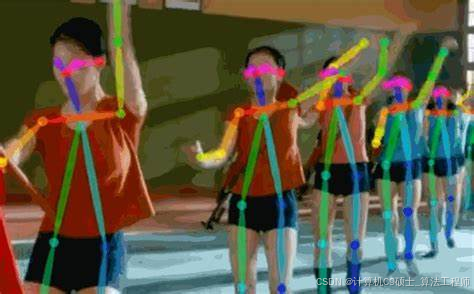
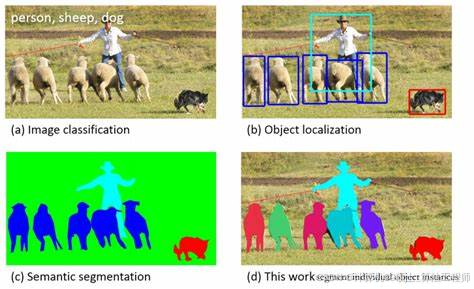
图像分类
在本教程中,您将学习如何使用迁移学习训练卷积神经网络以进行图像分类。您可以在 cs231n 上阅读有关迁移学习的更多信息。
本文主要目的是教会你如何自己搭建分类模型,耐心看完,相信会有很大收获。废话不多说,直切主题…
首先们要知道深度学习大都包含了下面几个方面:
1.加载(处理)数据
2.网络搭建
3.损失函数(模型优化)
4 模型训练和保存
把握好这些主要内容和流程,基本上对分类模型就大致有了个概念。
交通标志识别
项目是一个基于 OpenCV 的交通标志检测和分类系统
可以在视频中实时检测和分类交通标志。检测阶段使用图像处理技术,
在每个视频帧上创建轮廓并找出其中的所有椭圆或圆形。它们被标记为交通标志的候选项。

表情识别、人脸识别
面部情绪识别(FER)是指根据面部表情识别和分类人类情绪的过程。
通过分析面部特征和模式,机器可以对一个人的情绪状态作出有根据的推断。
这个面部识别的子领域高度跨学科,涉及计算机视觉、机器学习和心理学等领域的知识

疲劳检测
瞌睡经常发生在汽车行驶的过程中
该行为害人害己,如果有一套能识别瞌睡的系统,那么无疑该系统意义重大!

车牌识别
用python3+opencv3做的中国车牌识别
包括算法和客户端界面,只有2个文件,一个是界面代码,一个是算法代码
点击即可出结果,方便易用!

图像去雾去雨+目标检测+单目测距结合
0.0实时感知本车周围物体的距离对高级驾驶辅助系统具有重要意义,当判定物体与本车距离小于安全距离时便采取主动刹车等安全辅助功,
0.1这将进一步提升汽车的安全性能并减少碰撞的发生。上一章本文完成了目标检测任务,接下来需要对检测出来的物体进行距离测量。
1.首先描述并分析了相机成像模型,推导了图像的像素坐标系与世界坐标系之间的关系。
2.其次,利用软件标定来获取相机内外参数并改进了测距目标点的选取。
3.最后利用测距模型完成距离的测量并对采集到的图像进行仿真分析和方法验证。


代码
路径规划
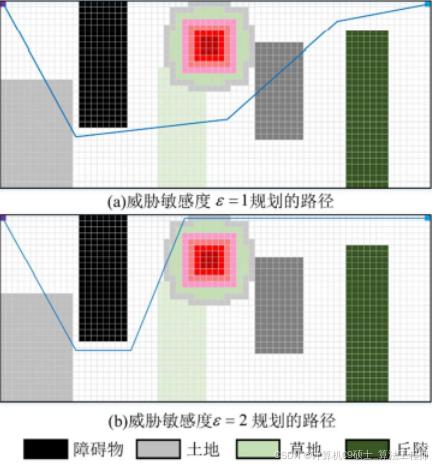
本节针对越野场景路径规划问题,采用栅格法建立障碍物、威胁物和越野道路模型,模拟真实的越野环境场景。
引入方向变化惩罚和局部区域复杂度惩罚来优化A算法,使算法规划出的路径更平滑,算法效率更高效。
采用改进 Floyd 算法对路径进行双向平滑,并且进行了防碰撞处理,来确保规划出路径的安全可靠性。
仿真结果表明,所改进的 A算法与传统算法相比较,效率提高了 30%,拐点数减少了4
倍,所提算法能够在越野环境多重因素综合影响以及不同车辆性能和任务的要求下快速的规划出安全的路径。
代码
停车位检测
基于深度学习的鱼眼图像中的停车点检测和分类是为二维物体检测而开发的。我们的工作增强了预测关键点和方框的能力。这在许多场景中很有用,因为对象不能用右上的矩形“紧密”表示。
一个这样的例子,道路上的任何标记,由于透视效果,在现实世界中的对象矩形不会在图像中保持矩形,所以关键点检测显得格外重要。鱼眼图像还呈现了观察到这种现象的另一种场景,由于鱼眼宽广的视角,可以扑捉更多画像

代码
图像雾去雨与目标检测
针对不同的天气则采取不同的图像前处理方法来提升图像质量。
雾天天气 时,针对当下求解的透射率会导致去雾结果出现光晕、伪影现象,本文采用加权最小二乘法细化透射率透。
针对四叉树法得到的大气光值不精确的问题,改进四叉树法来解决上述问题。将上述得到的透射率和大气光值代入大气散射模型完成去雾处理;
在图像处理后加入目标检测,提高了目标检测精度以及目标数量。
下图展现了雾天处理后的结果
图第一列为雾霾图像,第二列为没有加入图像处理的目标检测结果图,第三列为去雾后的目标检测结果图。

无人机检测
反无人机目标检测与跟踪的意义在于应对无人机在现实世界中可能带来的潜在威胁,并保障空域安全。以下是这方面的几个重要意义:
空域安全:无人机的广泛应用给空域安全带来了新的挑战。通过开展反无人机目标检测与跟踪研究,可以及时发现和追踪潜在的无人机入侵行为,确保空域的安全和秩序。
防范恶意活动:无人机技术的快速发展也为一些恶意活动提供了新的工具和手段,如无人机进行窥探、非法监听、破坏等。反无人机目标检测与跟踪的研究可以帮助及时发现和阻止这些恶意活动,维护社会的稳定和安全




















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









