







1、贷前策略搭建初期
在贷前策略搭建初期上线多少规则比较好?是不是一次上线越多规则越好?既怕上多了无效策略导致上线时间的延后,错失业务进入市场的最佳良机,也怕上线规则漏过一些坏人,导致前期的风险指标难以交代。
到底应该如何控制这个平衡?其实,一般在业务上线初期,规则越少越好,最好要有一个MVP版本,且一定要能支持快速迭代。
具体原因有如下三点:
01、业务初期需要快速试水
业务初期需要快速试水,摸清目标客群的自然风险情况,这样才能快速在产品层面进行评估和调整;前期试水和后期试水产生风险绝对值在量级上是完全不一样的。前期较少,也可以快速止损;
02、上线后,需要足够的样本量
上线后策略的迭代优化,需要足够的样本量,前期更多的样本能帮助快速定位问题并补足漏洞,这样漏洞越来越少,业务拓广的信心也越来越大;同时,可以避免迭代时样本不够的尴尬境地,影响迭代速度;
03、离线观测
初期缺少自身客群的Y值,无法准确量化定义前期策略的效用,所以一些不确定的策略均可离线观测。
2、贷前策略搭建中期
在贷前策略搭建中期,业务量已经达到了一个相对可观的量级,可以支持细分客群的量化分析,同时也具备足够的样本量。接下来就需要进行大规模的量化分析和策略迭代。
策略搭建中期,主要分为以下四个阶段:
01、线上A/B Test
进行大规模、有序的可用规则线上A/B Test,这个过程主要目标还是在找坏人,将测试无误的规则转正上线;
02、交叉分析,剔除杂质
将这批转正的规则集合进行内部交叉分析,剔除杂质。简单来说,就是看有哪些规则是可以被其它多条规则所替代的;再将剔除杂质后的这批转正的规则集合与原有规则集合进行交叉分析,进一步剔除杂质;
03、回捞
在拒绝的客户中找一些好的客户捞回,这个时候也需要做大量的A/B Test,验证无误的规则转正上线;
04、分类和归纳
最后就是对精炼的策略进行分类和归纳整理,形成完成的策略体系。
在这个阶段扩充的规则,并不是每次都是雷同的,不同的产品类型和业务场景,分析拓展出来的规则属性都不一样,这也是策略的难点,需要结合实际业务来调整。
就像树的种子都差不多,但长成大树后形态是有差异的一样。
3、贷前策略搭建后期
经过中期策略系统的优化后,针对当前客群已经有了一套比较适合的贷前策略,接下来需要把这套策略上升一个维度,就是细分客群,做差异化审批。
当策略分析人员在经过日复一日的风险策略体系全生命周期管理后,因为其已经熟悉不同产品、不同客群的差异化审批策略,就能针对任何一个新客群、新信贷产品,在较少数据甚至没有数据可依的初期,设计出上线策略的MVP版本,帮助业务在开展初期以最小的风险代价打下坚实的策略基础。
贷前风控都是围绕这么个流程,主要分为以下三个模块:
01信息核验
在金融信贷业务中,信息核验是用户申请进件后的第一个风控环节,具体表现类型包括身份核验、人脸识别、位置诊断、核身鉴权等,这些策略必然是产品的准入规则,很多数据来源是通过调用外部接口来实现的,例如身份二要素核验、手机号三要素核验等。
02欺诈识别
反欺诈在整个信贷领域里是非常凸显的一个模块,它的目的并不是挖掘真正的信用风险,而是想识别它的欺诈风险。识别欺诈包括名单过滤、欺诈检测、多头识别、交叉验证等。
03授信决策
授信决策是通过多个维度的指标信息,对申请用户的信用风险进行评估,并根据相关策略来决策审批是否通过或拒绝,具体表现形式有标签规则、信用评分、模型评级、决策矩阵等。
贷前风控策略模块的构成信贷业务的贷前风控流程,首先是申请用户发起进件,业务方通过用户填写的申请信息,以及从外部调用的授权信息,获取风控体系所需要的多维数据,从而加工出策略与模型的相关特征指标,然后按照策略规则的原理逻辑,形成了完善的贷前风控策略,然后根据策略或模型的具体决策逻辑,对用户进行量化分析与风险评估,同时以风控决策引擎配置好的决策规则,来对申请用户进行订单审批与额度授信。
贷前规则类型(业务角度)在信贷产品的线上风控体系,策略是其中重要的组成部分,策略模块由多个规则构成,而规则属性又包括多种类型。从策略应用角度区分,贷前规则类型包括准入条件、逻辑信息、要素核验、名单过滤、标签拒绝、模型评级、产品定价等。
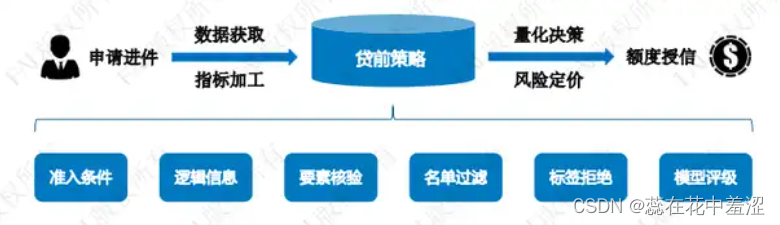
上面给大家介绍的是6个类型,从应用的角度来说,还有别的维度,只是这6个类型是容易理解且重要一些。大家可以通过下图举例去看下是怎么去执行的。下图是一个比较标准化的基本顺序,当然在具体业务当中会适当的调整。

策略规则的常见类型
从开发角度来讲,主要从以下几个维度去进行划分:
第一种,按特征类型划分连续型和离散型,对应的规则类型有:连续多区间、二分类和多分类。
一个特征字段的类型有连续型和离散型,离散性又可以划分为字符型和数字型。
连续型特征比较通俗易懂,即将规则划分成多区间,通过每个区间研究数据样本的分布情况。
离散型有二分类和多分类。二分类如有“是否某电商平台欺诈黑名单”,黑名单不是0就是1。多分类规则取值不局限于两类,如有取值范围为A、B、C、D、E的“信用评分风险等级”。
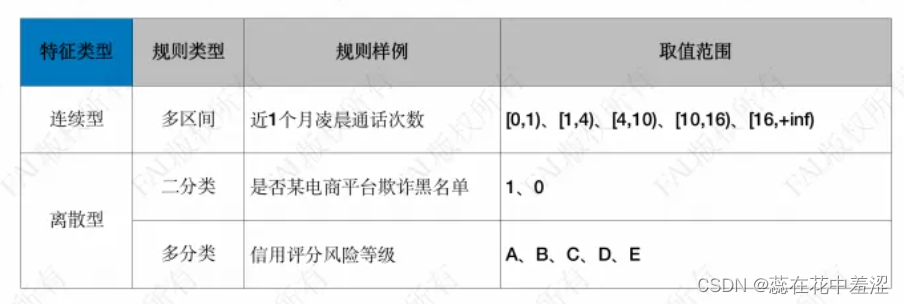
二分类和多分类是有较大的区别,尤其从开发角度。一方面是验证的难易程度,从业务角度二分类体现的是一个用户的正反两面性质。而多分类在很多情况下取值是有序的,不仅要考虑区分度,还要考虑单调性。不管是多区间还是二分类、多分类,需要综合考虑其对应的占比和坏账率。
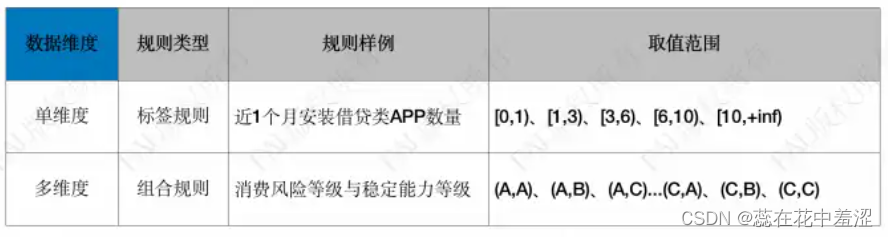
第二种,按“数据维度”划分为单维度和多维度,规则类型有:标签规则和组合规则。
举个例子,如:某个用户近1个月他安装借贷类APP的数量,这可以看到只体现了一个维度,即不考虑时间窗口,只考虑用户安装APP的业务属性。很多业务当中是多维度的组合,可能是两个维度或者多个维度,尤其是采用决策树模型的时候,根据很多数据源不断去交叉,交叉后就得到了很多个维度的规则。
举个例子,如:一个用户的消费风险等级与稳定能力等级。交叉结果可能是这个用户消费风险等级是低级,比如C级,是最差的。但他是不是特别坏的用户呢?不一定,虽然比较差,但不是绝对差。如果稳定能力也很差的话,做一个交叉,从矩阵的角度就是多维度组合,这样效果反而更好一些的。
第三种,从“风险等级”维度划规则,规则类型有:刚性、高柔和低柔。
- 风险等级简单来讲就是高低的区别,在业务中真正做规则的时候,往往需要挖掘一些风险高的阈值。那该如何识别风险,只需要将特征数据分布划分多个区间,把某个区间风险很高的对应的阈值做出一条规则。但既然是风险很高的规则,那不就是一个区间吗?这里给大家介绍另一个方法。为了实现风险精细化管理与评估,可以考虑将风险较高区间划分为多个区间。
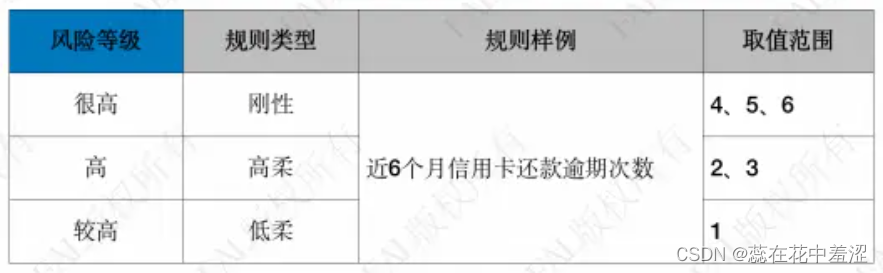
举例子,把某规则通过样本分布划分了十个区间,把其中最后三个区间分别组成三套规则。虽然是同一数据源,但阈值不同,阈值不同代表里边每个区间的坏账率表现是有明显差异的。通过坏账率的高低就可以把它定义成很高、高、较高的风险等级。在规则的角度,可以定义成刚性、高柔、低柔。命中刚柔规则,不容置疑,直接拒绝掉。而命中高柔和低柔进行打标签,进入下一环节。在这种规则开发思路的情况下,最终可以形成多个不同风险等级的策略规则集,在风控决策应用过程中,单条规则不做决策,所有规则综合决策,可参考以下:
- 命中刚性规则的数量>0,拒绝
- 命中高柔规则的数量>5,拒绝
- 命中低柔规则的数量>10,拒绝

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









