






大家好,我是老渡。
上周跟朋友们分享了视频内容总结的智能体,帮我们提高学习效率。

从下载视频,分离音频,到音频转文本,再到大模型总结,没少忙活。
结果今天发现智谱发布了新的视觉大模型 GLM-4V-Plus,能分析、总结视频内容,把上面的流程都免了。

以下面这篇讲解线性代数的视频为例
用 GLM-4V-Plus 模型总结视频核心要点,只需输入视频url和prompt即可。
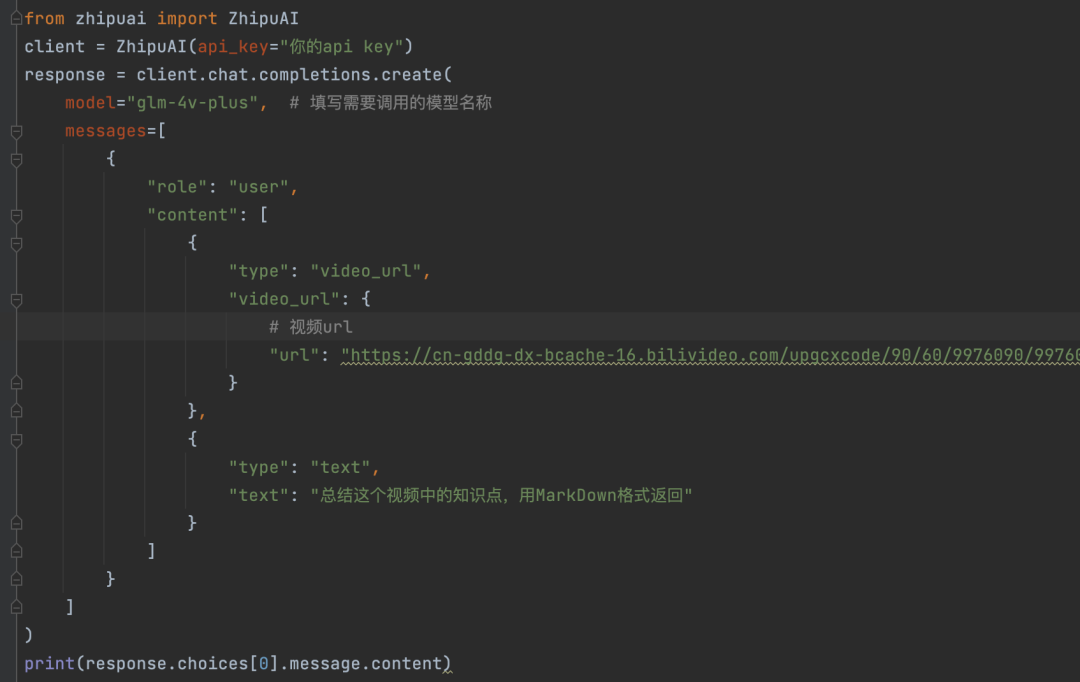
输出结果:

可以看到 GLM-4V-Plus 模型能读懂视频内容并总结,并且总结的非常详细。拥有视频理解能力的大模型,除了能帮我们提高学习效率,还可以将总结内容送入本地知识库,做一个多模态知识库助手。
仅几行 Python 代码就替代了我们之前开发的智能体,不得不说,智谱这届 plus 模型确实强。
代码中需要的 api key,可在智谱大模型开放平台(bigmodel.cn)获取,文末可直达。
GLM-4V-Plus 既然能分析视频,那分析图片自然不在话下。比如,下面这张图片
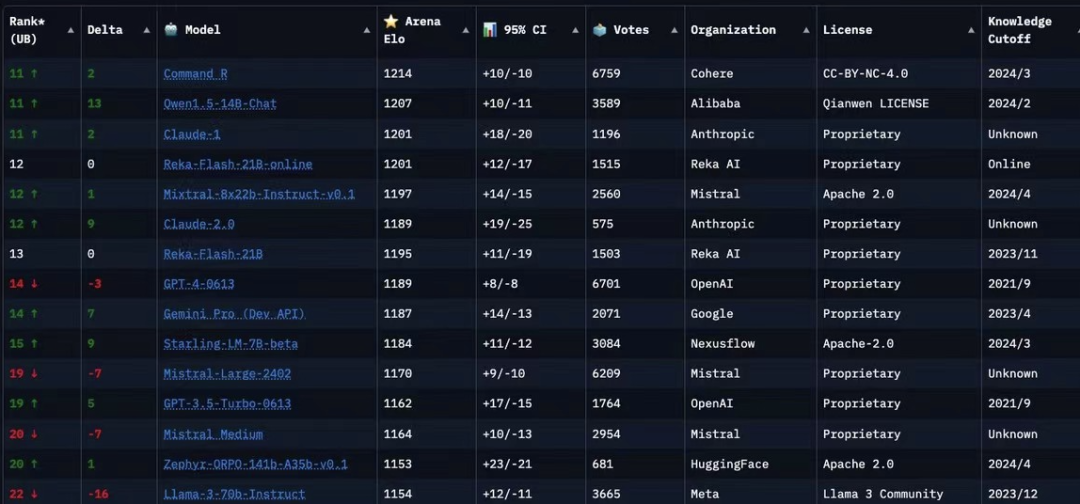
我们可以让 GLM-4V-Plus 转成相同格式的文本内容

GLM-4V-Plus 用 MarkDown 表格输出与原图表格一致,并且解析内容也是正确的
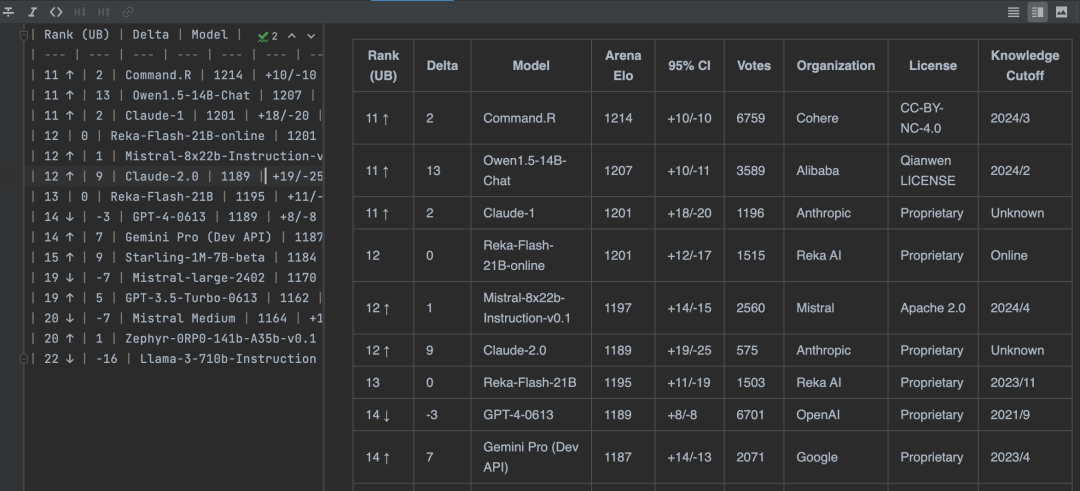
这个功能就可以取代 OCR 识别了,轻松提取图片中的文本,既方便又准确。
有些朋友可能还有这样的需求:将PDF转成MarkDown文本,同时保持PDF中的格式

目前有不少开源项目支持这类需求。大致思路是先将 PDF 转成图片,用视觉大模型将图片转成相同格式的文本。这时候,GLM-4V-Plus 就派上用场了。
此外,GLM-4V-Plus 也支持上传多图,分析一系列图片行为。比如,下面是摔倒视频中抽取的关键帧

我们可以让 GLM-4V-Plus 从一系列关键帧中判断是否有摔倒行为。
之前摔倒检测用骨骼点识别+神经网络花了很长时间才实现的,现在用 GLM-4V-Plus 轻松就搞定了。
使用下来,感觉 GLM-4V-Plus 的视觉能力是挺强大的。视觉跟大模型结合可以开发出很多有用、有趣味的AI应用,推荐大家用一下。















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









