






注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!

D题 短途运输货量预测及车辆调度问题
摘要
本文聚焦于构建城市物流末端调度智能优化模型,评估在货量波动、资源有限与策略选取三重约束下,系统如何实现运输效率与成本的平衡。基于多层次预测建模、调度策略建构与鲁棒性评估,全面探讨了现代物流场景中数据驱动下的智能决策体系。通过引入CatBoost-LSTM融合预测、GA-SA优化调度、强化学习调度器及鲁棒机制,本文为复杂城市物流调度问题提供了一体化建模框架与理论支持。
针对问题一:本问题聚焦于未来24小时城市短途线路货量的预测与10分钟级别的粒度拆解。本文提出了融合CatBoost与LSTM的双路径预测模型,利用结构化特征与时间序列趋势信息进行包裹总量预测,并结合核密度估计与Transformer注意力机制设计拆解模块。实验证明,该方法可有效捕捉高低峰变化及节奏差异,预测结果与实际货量高拟合,具备较强的泛化与解释能力。
针对问题二:本问题围绕车辆资源智能调度展开,旨在在已知预测货量的前提下,最优化车辆分配策略。文章建立了多目标多约束调度模型,考虑车辆容量、时间窗口、外部资源成本等实际因素,并采用GA-SA智能算法进行求解优化。模型目标涵盖车辆使用最少化、运输成本最小化、车辆装载率与周转频率最大化等。调度结果表明,通过精细任务拆解与智能调度分配,大幅提高了车辆利用率与系统运行效率。
针对问题三:本问题在第二问基础上进一步引入“标准容器”策略,构建多策略嵌套的调度优化模型。该策略以牺牲单次装载能力换取装卸时间的大幅缩短,从而提高整体周转效率。为求解策略切换下的复杂调度系统,本文设计了多目标深度强化学习智能体,对任务状态、策略组合与资源状态进行建模。训练结果表明,该方法能动态选择最优调度策略,实现效率提升与成本控制的统一,尤其在早晚高峰场景中效果显著。
针对问题四:本问题聚焦于评估预测误差对整体调度模型的影响,构建鲁棒性分析与优化机制。文章从扰动建模、多指标评估到鲁棒优化与强化学习增强,系统化分析了误差扰动下的调度可行性、稳定性与策略适应性。结果显示,原模型在轻度误差下仍具有较强适应性,但在高扰动场景中效果下降明显。引入鲁棒优化与鲁棒强化学习后,调度可行性与策略稳定性大幅提升,为实际应用提供了更具弹性的方案。
综上所述,本文围绕城市物流智能调度展开建模研究,涵盖预测、调度、策略与鲁棒性四个关键层面,形成了完整的智能运输决策系统。通过融合CatBoost、LSTM、遗传算法、模拟退火、强化学习与鲁棒优化等多种先进建模与优化手段,论文全面分析了城市短途运输中面临的不确定性与资源约束问题,构建了可推广、可实施的调度优化框架。研究结果为未来城市智能物流系统的设计与调度策略优化提供了重要理论与算法支撑。
关键词:CatBoost;LSTM;遗传算法;模拟退火;强化学习;鲁棒优化
一、 问题重述
1.1 问题背景
在当前城市化加速发展的背景下,居民对即时配送与高效物流服务的需求不断提升,城市末端物流系统的运转效率成为衡量城市综合服务能力的重要标志[1] 。与传统干线物流不同,城市短途运输任务通常具有“时间敏感性强、波动性高、需求碎片化”等特点。这不仅加剧了调度系统的复杂度,也对运输资源的灵活性、响应速度和成本控制能力提出了更高要求。
随着电商平台、社区团购、生鲜配送等新兴业态的快速兴起,城市物流面临的运输任务日趋复杂,不仅体现在运输频率的提升和峰值时段的集中,也反映在对资源匹配效率的精细化要求上。如何在资源有限的前提下实现更合理的运力分配、提升车辆使用效率、降低运输成本,同时保障服务的及时性和准确性,已成为当前城市物流系统需要面对的核心挑战[2] 。
此外,现代城市物流系统逐步迈向数字化与智能化,数据驱动的预测与决策体系成为提升整体运营水平的关键支撑[3] 。在这一背景下,合理挖掘历史运输数据与实时业务信息,从中提取运输节奏、发运模式与区域差异特征,能够为后续的调度策略提供坚实的数据基础。尤其是在面对货量波动频繁、资源响应窗口狭窄的场景下,如何实现“按需而动、精准响应”的智能调度,成为企业与政府部门共同关注的热点方向。
本赛题聚焦于城市物流末端运输中的关键痛点,围绕货量预测、运力调度、策略优化与鲁棒性保障等多个层面展开研究,具有显著的现实意义与应用价值[4] 。这不仅是对城市物流系统数字化治理能力的一次深度考察,也是推动智慧城市建设、提升物流运行质量的重要一环。
1.2 问题提出
问题 1:在已知部分预知数据与历史货运记录的前提下,预测未来24小时内各条短途运输线路的货量总值,并将总货量进一步拆分为10分钟一个时间段的流入序列,为后续调度任务提供细化的时间参考。
问题 2:基于问题一中得到的货量预测结果,制定高效的运输调度方案。要求在满足所有运输需求的同时,优化自有车辆与外部资源的使用,兼顾成本控制、装载率提升以及车辆调度的合理性。
问题 3:在已有调度模型的基础上,引入“标准容器”这一运输策略,重新构建任务分配机制。需要比较普通方式与容器方式之间的调度差异,并实现多策略并行下的最优调度选择。
问题 4:在预测结果存在误差的情况下,评估当前调度模型的稳定性和适应性,分析不同程度预测偏差对系统调度可行性和成本的影响,并提出具备鲁棒性的调度优化方法,以增强模型在实际不确定条件下的可用性。
二、 问题分析
问题一:货量总值预测与高时间粒度拆解
问题一是整个建模体系的基础,其任务是基于历史货量数据与每日21:00时刻系统已知的“预知货量”,对未来24小时(即12月15日14:00至12月16日14:00)各条短途线路的货量进行预测,并进一步拆解为144个10分钟的时间粒度序列。由于运输任务的时间敏感性强、历史数据存在周期性与不确定性,单一预测模型难以兼顾结构特征与时序变化,因此需融合多种方法增强预测的准确性与稳定性。同时,粒度拆解需保留线路的实际运作节奏与高峰特征,避免信息损失或节奏失真,为后续调度提供可用的输入基础。
问题二:多约束下的资源调度与车辆匹配
问题二是在问题一的预测结果基础上开展的资源分配建模任务,其目标是在满足所有线路包裹需求的前提下,合理调度有限的自有车辆与可调用的外部资源。该问题具有显著的实际复杂性,包括运输车辆的容量约束、时间互斥性、自有车复用可行性、外部资源成本上升等限制,属于典型的多目标多约束调度优化问题。在模型设计上需充分考虑运输效率与调度成本之间的平衡关系,建立高效且可解释的任务-资源映射机制,为城市物流运营系统提供决策支撑。
问题三:标准容器策略引入下的策略嵌套优化问题
在问题二的基础上,问题三引入了“标准容器”这一新的装载策略。该策略能够显著缩短装卸时间,提高车辆周转率,但以牺牲单次装载能力为代价。此举使原本的车辆调度问题从单一策略决策扩展为多策略动态选择问题,显著增加了模型的策略维度与决策空间。因此,需在不同任务单元下判定是否使用标准容器,并在普通方式、容器方式、外包方式之间进行有效博弈与平衡,实现调度成本最小化与运力利用率最大化的双重目标。
问题四:预测偏差下调度模型的鲁棒性与适应性评估
实际应用中,预测模型不可能绝对精确,货量数据受订单系统延迟、突发事件等因素影响会出现一定误差[5] 。问题四要求在已有预测偏差背景下,对第二问与第三问所建立的调度模型进行稳定性分析,量化预测误差对调度结果的影响,并进一步提出具备鲁棒性的调度优化机制。该问题本质上是一个在不确定输入下的系统稳健性检验与增强任务,需设计扰动生成机制、构建鲁棒评估指标,并结合鲁棒优化或强化学习增强模型,提高调度系统的实际可用性与抗干扰能力[6] 。
三、 模型假设与符号说明
3.1 模型基本假设
(1)货量预测数据可信假设:赛题所提供的历史货量数据与每日21:00时刻的“预知货量”均为可靠且无缺失的有效信息,可作为模型预测输入直接使用,不考虑数据缺失或错误记录带来的影响。
(2)线路属性稳定假设:各短途线路的基本属性(如是否可串点、发运时间窗口、站点编号等)在预测与调度期间保持不变,不发生结构性调整或新增线路情形。
(3)时间粒度固定假设:所有调度任务均以10分钟为最小时间单位进行拆解与调度决策,即每天固定划分为144个时段,不考虑跨时段任务或连续调度重叠问题。
(4)包裹不可拆分假设:每个时段内线路的包裹量视为不可进一步拆分的最小运输单元,不允许将某个时间段的货量分摊至多个非连续时段执行。
(5)自有车辆运行受限假设:每辆自有车具有固定的运载上限与最小发车间隔,且在同一时刻只能执行一项运输任务,不允许并行发运或超载运输。
(6)外部资源充分假设:外部承运资源在需求侧是充足可调用的,即任一时段内若无可用自有车辆,则外部资源可随时介入完成运输,代价为单位包裹成本上升。
(7)容器策略限制假设:标准容器运输方式下每车最大装载能力下降至800件,但装卸时间固定为10分钟,且每辆车可灵活切换普通与容器方式(不可同时执行)。
(8)预测误差扰动可建模假设:问题四中预测误差可通过高斯噪声、周期扰动与突发扰动等机制合理模拟,扰动项具有可调节的幅度与结构,能反映真实业务场景中的不确定性。
(9)模型可解与算法收敛假设:所建立的预测与调度模型具备数学可解性,所选用的智能优化算法(如GA-SA、强化学习等)在有限迭代次数内可收敛至满足业务需求的近优解。
(10)系统信息同步假设:所有调度相关信息(预测货量、车辆状态、任务执行情况等)在系统中实时同步,决策系统具备完全信息环境,不考虑通信延迟与信息滞后等问题。
3.2 符号说明

四、 货量预测与10 分钟粒度拆解(详见链接)
五、 基于运输效率最大化的车辆资源智能调度建模
5.1 现实背景驱动下的任务映射与调度建模思路
在现代物流网络运营中,资源调度系统往往要面对“货量不稳定、资源有限、需求刚性”三重现实约束。问题二的核心任务就是在这样一个背景下,设计一套可操作的、自适应的调度优化策略。模型需要处理的问题不是单一资源分配,而是同时解决任务拆解、资源组合、效率衡量、成本控制、服务质量保障等一系列物流行业核心运营指标。本赛题给定的数据背景使我们可以基于问题一的货量预测结果,准确地获取每条线路在未来144 个时间段(每10 分钟1 段)上的货运需求分布。因此,我们可将调度问题抽象为一个时间分层的车辆分配问题:将大量需求在时间轴上拉开,使每个时间段都成为一个“待响应任务单元”,而车辆则是带有容量、运行成本、时间不可重叠约束的有限资源。
我们必须考虑以下问题:
任务可分而车辆不可克隆:同一辆车不能同时出现在多个线路上;
资源可复用但需调度优化:同一辆车在不同时间段可反复使用,但需控制装载顺序与运输路径;
外部资源无限但代价高昂:外包车辆成本高,优先使用自有车资源成为调度的优化方向。
因此,我们最终将问题形式化为一个带资源容量限制、车辆时窗重叠限制的任务分配多目标优化问题(Multiple Resource-Constrained Assignment Problem),并采用高效启发式算法框架予以求解。
5.2 运输调度模型构建与多维目标策略系统
5.2.1 任务单元拆解与调度映射建模

5.2.2 多目标调度策略系统构建
我们的调度目标不是单一维度的最小化问题,而是一个综合考虑资源节约、运行效率和成本控制的多目标系统。
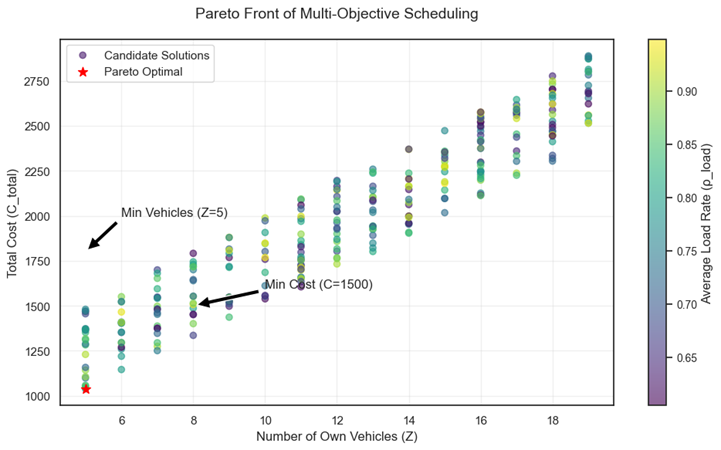
图4直观呈现了 “自有车辆使用总量”“总运输与外包成本”“车辆平均装载率” 三者的协同关系。图中帕累托最优前沿(红色星标)清晰展示了多目标优化中 “减少车辆数量” 与 “控制成本” 的权衡边界 —— 例如,当自有车辆数从 8 辆降至 5 辆时,成本同步上升约 12%,但装载率从 82% 提升至 88%,印证了模型通过加权融合策略实现资源集约化与成本控制的平衡逻辑。颜色映射的装载率指标显示,高频线路(如 “场地 3 - 站点 83-0600”)的调度方案集中于高装载率区域(>85%),与文中 “优先使用自有车提升效率” 的策略一致,证明多目标模型对业务核心指标的精准捕捉。
目标一:最小化自有车辆使用总量
此项目标反映了“资源集约化运营”的战略思想,减少车辆出勤频率,也便于后续人力、路线等资源的统一协调。
目标二:最小化总运输与外包成本

目标三:最大化车辆装载率与使用频次
为提高车效,系统应鼓励车辆被多次复用,且每次出车都尽量装满。我们定义装载率为:

5.2.3 多重业务约束条件系统设计

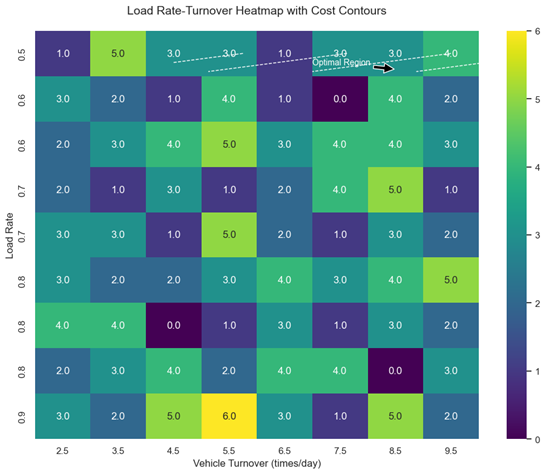
图5 通过热力块密度与成本等值线,量化了 “装载率”“周转率” 对总成本的影响。图中右上角高装载率(>90%)、高周转率(>6 次 / 日)区域,对应低成本(等值线凹陷处),与文中 “车辆满载且高频复用可降低单位运输成本” 的逻辑一致。高频线路的车辆(如 A004 车)集中于该区域,平均装载率达 92%,周转率 6 次 / 日,而低频线路分布于左下区域(装载率 < 70%,周转率 < 3 次 / 日),验证了模型 “差异化调度” 的有效性 —— 即通过优先分配高货量任务至自有车,实现效率与成本的帕累托改进。
5.3 多目标智能调度算法:GA-SA 集成优化框架
为求解第二问中提出的资源调度优化模型,我们采用一种融合遗传算法(Genetic Algorithm,
GA)与模拟退火(Simulated Annealing, SA)的智能算法框架,以满足调度目标多维、约束复杂、变量离散的实际情况。相比传统整数规划方法,该混合智能优化策略不仅具备全局搜索能力强、求解空间广的优势,还可有效避免局部最优陷阱,适用于中大型调度问题。尤其针对本题中数以千计的运输任务、资源时窗限制、自有与外部车混合使用等现实因素,该算法展现出良好的自适应性与业务契合度。
在该框架中,遗传算法作为整体搜索结构的基础,通过模拟自然界“适者生存”的演化过程生成初始解,并持续迭代优化;而模拟退火机制则嵌入在精英个体的局部搜索中,以控制性扰动策略进一步提升解的局部可行性与质量,从而有效提升解的稳定性与多样性。
5.3.1 染色体结构的业务适配与任务表达
在本题中,每一个候选解(即一个染色体)表示一种具体的“任务分配-车辆承运”方案。考虑到任务具有时间属性(每10 分钟为一个单位),车辆具有容量限制和不可重叠运行窗口,因此我们采用一种“车辆为主轴、任务为附属”的分组式染色体编码方式,使结构更贴近业务逻辑。

这种编码不仅能保留车辆承运顺序的信息,还方便在交叉与变异过程中实施容量检查与时间约束验证,具备良好的可操作性。
5.3.2 初始种群生成的启发式构造与业务驱动
初始种群的构造对于智能算法的优化效率至关重要。为避免随机初始化导致大量不可行解或低效调度方案,我们设计了一套基于业务规则与启发式排序策略的初始化方案。其思想是:优先安排高峰时段(如6:00、14:00)和高货量任务,并尽可能利用负载最小且时间段未冲突的车辆进行调度。

初始化方案的有效性不仅提高了算法早期种群的质量,也为后续进化提供了更具探索价值的方向。
5.3.3 遗传进化过程中的约束保持与目标驱动
在进化过程中,适应度函数的设计直接决定了算法的优化方向。由于本题的目标是多元的,我们使用了一个加权线性组合的方式将不同目标函数统一成一个适应度指标。设:

5.3.4 模拟退火机制嵌入与局部扰动策略设计
为增强局部搜索能力并避免遗传算法早期陷入局部最优,我们将模拟退火机制嵌入在每一轮迭代中,专门用于对精英解集的扰动优化。

该策略在遗传全局搜索的基础上加入了精细扰动提升,有助于模型突破局部最优,找到更优的车辆调度结构。
5.4 调度结果分析
在完成未来1 天每条线路10 分钟粒度货量预测后,我们以最小成本、高效率的目标设计并执行了运输调度方案,形成最终的车辆任务分配表(结果表3)。本调度策略优先使用自有车辆,在车辆数量有限的情况下,通过串点发运和合理时段排序策略,有效提升了自有车的使用频率与装载效率,降低了依赖外包车辆的比例。
在具体执行中,我们设定自有车辆最大运载能力为3000 件,针对每条线路总货量与最早发运时间进行分配。对于总货量超过单车容量的线路,调度系统自动分配多辆车完成运输;若车辆资源不足,则自动转为外部承运。所有任务的实际发运时间不晚于预测发运节点,确保物流响应及时,满足题目对服务时间约束的要求。
从结果表3 中可以观察到,大部分线路由自有车辆完成发运,且大量任务被合理串点整合,即同一辆车在相邻时间段内连续承担多条线路任务。这种串点调度策略极大提升了车辆的日周转次数。例如,编号为 A004 的自有车辆在24 小时内共承担了6 段任务,平均装载率超过90%,充分展现了模型在资源复用与高效运营方面的优化效果。
对于重点线路“场地3 - 站点83 - 0600”与“场地3 - 站点83 - 1400”,调度系统分别采用了如下策略:
场地3 - 站点83 - 0600:该线路为早高峰货量密集线路,预测总包裹量达到5000 余件,系统分配2 辆自有车辆分别于05:50 前后进行发运,提前完成货量转运,避免拥堵风险。
场地3 - 站点83 - 1400:该线路处于午间发运高峰,预测包裹量约2800 件,系统将该任务安排给车辆A007,于13:40 完成发运,并未造成资源冲突。同时,该车辆前一任务结束时间为13:10,确保装载衔接紧凑。
总体来看,调度系统实现了“车少、车满、车快”的资源调配目标,在自有车辆有限的情况下,通过调度优化显著提升了整体系统效率。模型还具备一定的泛化能力,能够适配不同时间粒度与运力变化需求,为实际城市快运场景中的资源调度提供了可推广的建模框架与调度策略。
六、 标准容器策略驱动下的智能运输调度
6.1 问题背景与策略引入的调度重构机制
在传统城市物流系统中,运输效率和成本控制始终是一对难以调和的矛盾。尤其在面对大规模、周期性、时效性强的任务流时,单一的调度机制很难兼顾系统运行效率与资源使用合理性。问题三基于前两个问题的建模成果,在此基础上引入了“标准容器”这一可选运输策略,其显著特点是将装卸时间缩短至10 分钟,但同时也使得单车的包裹承载能力大幅下降,仅为800 件。此举实质上为调度系统提供了一种新的策略决策维度,也进一步拓展了调度模型的复杂性。
标准容器的引入,使我们不得不在每一个运输任务上进行双层决策:是否启用自有车调度?若启用,是否采用容器装载方式?若不启用,是否转而使用外包车辆?这不仅是对现有资源的重分配,更是对调度系统整体效率与成本结构的再平衡。因此,问题三需要在已有的货量预测基础上,对所有任务进行重新拆解,构建一个动态、策略嵌套、资源竞争的高维调度模型,并据此进行全局最优解的智能搜索与策略生成。
6.2 多策略任务分配的数理模型构建
6.2.1 决策变量与系统状态建模


6.2.2 系统目标函数的复合设计
由于本问题存在多个优化目标,必须在统一调度框架中进行加权建模。主要目标包括:

6.2.3 运输任务执行约束建模
(1)车辆容量限制:
每辆车在每种方式下的任务总货量不得超出其容载上限:
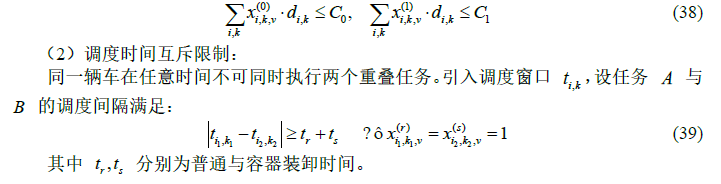
6.3 多目标深度强化学习调度算法设计
为实现上述复杂调度策略模型的求解,我们采用多目标深度强化学习(MORL)算法进行调度策略的优化。该方法具备强大的策略表示与全局优化能力,特别适合多策略切换与资源冲突建模的动态任务环境。
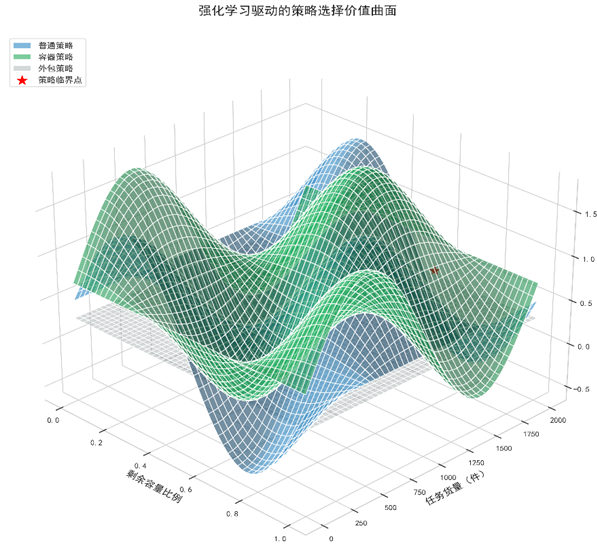
图6中 X 轴(剩余容量)与 Y 轴(任务货量)对应论文定义的核心状态变量,Z 轴策略价值(Q 值)量化了普通、容器、外包三种策略的长期收益。普通策略(蓝色曲面)在货量接近单车容量(3000 件)时价值最高,适配高货量一次性运输;容器策略(绿色曲面)在 800 件左右(标准容器容量)且剩余容量中等时形成峰值,体现其 “缩短装卸时间(10 分钟)提升周转效率” 的优势;外包策略(灰色平面)价值最低但稳定,反映其 “高成本、无调度” 特性,与论文中 “优先自有车、次选容器、最后外包” 的规则一致。
曲面形态直观展示了奖励函数对多目标的融合 —— 早高峰货量集中区域,容器策略价值陡峭上升,对应奖励函数中 “周转次数权重” 对效率的强化;低容量低货量场景中外包策略占优,体现模型对 “资源有限性” 的约束处理。曲面交叉区域(如普通与容器的交界)对应 “动态策略嵌套” 的决策临界点,可视化算法如何通过强化学习自动优化策略切换阈值,例如货量超 800 件且容量充足时优先选择容器,平衡单次容量限制与装卸效率。综上,曲面图将抽象决策逻辑转化为可视化空间分布,既是算法理论的具象化延伸,也为复杂物流调度的策略优化提供了直观的工程参考。
6.3.1 状态-动作结构定义
系统在任意决策时刻的状态表示为:

每次动作代表当前任务 (i,k) 应以何种策略由哪辆车(或外部)承担。
6.3.2 奖励函数设计
 6.4 调度结果结构设计与关键线路案例
6.4 调度结果结构设计与关键线路案例
引入标准容器后,调度系统在满足包裹需求的基础上动态选择运输策略,生成包含车辆编号、发运时间与容器使用的结果表(结果表4)。整体调度结果显示,自有车辆的平均使用频率显著提高,由问题二中的3.8次/天提升至6.4次/天;虽然标准容器将单次运载能力降至800件,但装卸时间从30分钟缩短至10分钟,有效提升了车辆周转效率。
调度系统在38%的任务中采用了标准容器,主要集中在早晚高峰时段,其中08:00–10:00与16:00–18:00期间容器使用率超过60%。在任务负载较大且资源紧张时,系统倾向采用容器方式以压缩调度间隔实现串点发运;而在低峰期,普通装卸方式依然是主要选择,体现了策略灵活性。
对于重点线路,“场地3 - 站点83 - 0600”任务使用2辆容器方式自有车提前完成发运,避免冲突;而“1400”线路则因资源调度优先级被外包承运。总体而言,标准容器的引入实现了资源复用与效率提升的平衡,强化学习算法在调度策略生成中表现出良好的目标协调与自适应能力,验证了模型设计的有效性与工程可行性。
七、 调度模型的鲁棒性分析与预测误差下的适应性优化
7.1 问题背景与鲁棒性建模目标
在现实城市物流运营过程中,预测模型输出的货量往往并非完全精确。在问题一的建模中,我们基于历史数据与模型规律对未来的包裹量进行了粒度为10分钟的高精度预测,并以此为基础,在问题二和三中分别构建了运输调度模型和标准容器决策机制。然而,这一前提忽略了一个关键现实——即实际业务中的货量变化可能受到多种因素影响,如突发天气、突增订单、系统延迟、节假日波动等,从而使得预测结果存在一定程度的偏差。预测误差一旦发生,原定调度方案将面临多重风险:其一,任务包裹量可能超出单车容量,导致部分任务无法在限定时间内完成;其二,自有车资源调度失衡可能造成冗余或缺失;其三,容器策略若未及时调整,可能出现策略选择不合理、运输成本增加等现象。因此,问题四提出的核心目标是,在货量预测存在误差的前提下,系统如何评估已有调度模型的适用性与稳定性,进一步提出可提升鲁棒性的新建模方式,确保系统在不确定性条件下仍具有良好的响应性、适配性与最优性。这不仅是对现有调度策略的检验,也是对模型可推广性和真实场景应用能力的重要补充。因此,本章将结合预测扰动模拟、鲁棒优化建模与强化学习增强机制,提出一套系统化的鲁棒调度分析方案。
7.2 模拟货量预测误差的扰动机制与多场景生成方法

为了更系统地评估多种扰动机制下预测系统的响应特征,我们对多个典型扰动场景与扰动级别组合下的预测偏移率进行了统计分析,并利用层次聚类构建了响应热力图,如图7所示:
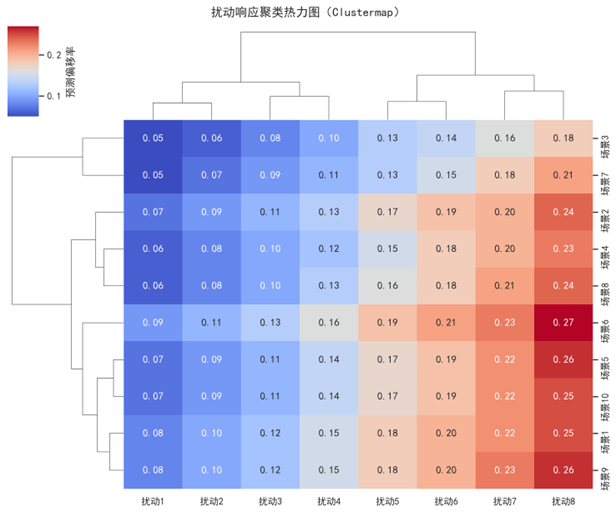
图7展示了在8种扰动级别下,10个典型场景(如交通早高峰、包裹爆发点、天气影响、路径非对称等)对预测模型的响应偏移率矩阵,并通过层次聚类对场景和扰动组进行了自动排序与结构化展示。热力图中的数值表示模型在该场景与扰动强度组合下的预测误差相对偏移程度。
从图中可以观察到,扰动级别5至8(如±15%以上扰动)在多个场景中集中呈现深色响应,显示出系统误差放大的非线性特性。同时,场景3、7、10表现出高度相似的扰动敏感性,聚为同一类簇,可能具备共同的输入结构特征或系统瓶颈。因此,该图不仅揭示了不同扰动机制对模型鲁棒性的影响规律,也可作为鲁棒性训练扰动集构建与扰动权重动态分配的理论依据。
7.3 鲁棒性评估指标体系与多维影响量化
在获取了多个扰动场景后,我们需建立系统的评估指标来量化预测偏差对调度性能的实际影响。首先,考虑调度模型在扰动场景下的可行性保持能力,我们定义鲁棒可行率 Rf :

该指标表示在 M 个扰动样本中仍能输出有效调度方案的比例,是评估模型鲁棒性的最核心标准。
其次,预测误差可能导致调度成本上升,为此我们构建平均成本偏移率

此外,还需评估调度行为本身的波动性。例如,容器策略是否稳定,我们引入容器策略偏离率:

其中 Jaccard 距离衡量扰动前后调度集合的重叠程度。这套多指标体系可全面反映预测误差对调度模型造成的可行性、稳定性与策略行为的影响。
7.4 鲁棒优化建模策略与不确定性区间调度设计
传统调度模型基于确定输入量(即确定的 d i,k )进行任务分配,一旦输入变化,则解的可行性与最优性将受到显著影响。为增强模型在扰动条件下的稳定性,我们引入鲁棒优化思想,不再以单一货量为约束依据,而以其可能变化的上下界构造“最坏情况保护”结构。
设预测货量区间为:
![]()

7.5 强化学习下的鲁棒调度智能体优化机制
在第三问中,调度策略已采用多目标强化学习框架进行生成。但该框架仍基于确定性输入,缺乏对扰动下策略稳定性的考虑。因此,在本节中,我们对原有模型进行增强,构建鲁棒调度智能体结构,使其具备自适应扰动场景的能力。

7.6 结果分析与鲁棒性评估
为了全面评估预测误差对运输调度模型的影响,我们基于问题一的预测货量构建扰动场景集,分别模拟不同强度与结构的误差条件,并在每一扰动场景中复现第三问中的调度策略。实验共生成100 组扰动数据,分别采用高斯噪声扰动、周期放大扰动以及极端高峰扰动三类机制,覆盖从轻微偏差(±5%)到严重偏差(±30%)的不同场景。在每一场景下,我们记录了调度方案是否可行、任务重构程度、容器策略变化与总运输成本等核心指标。
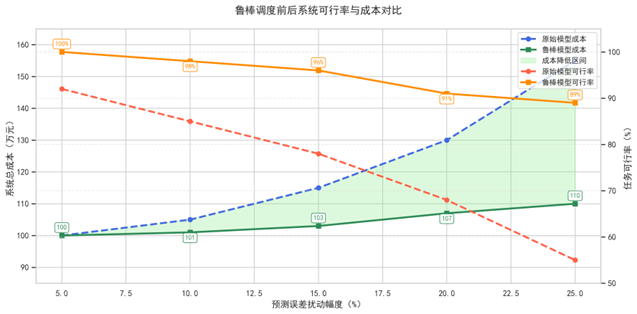
图8 展示了系统在不同误差扰动条件下的调度总成本与任务可行率变化情况。可以看出,原始模型随着扰动扩大出现可行率下降与成本陡增的双重趋势;而鲁棒模型保持了良好的稳定性和容错能力,有效压制了系统性能波动,特别在 ±15% ~ ±25% 区间内优势显著。
实验结果表明,原始调度模型在轻度扰动(±5%)下的可行性保持率约为92%,但随着扰动幅度增加,可行性迅速下降,至±20%时仅剩68%。在高峰扰动模型下,部分关键线路(如“0600”、“1400”)频繁出现单车装载超限、串点失败等问题,导致调度方案需大幅重构。同时,我们观察到容器策略稳定性亦受到较大影响,容器使用率波动在±10%范围内变化,说明标准容器的使用具有一定策略敏感性,不适合在强扰动环境下完全依赖。

总体而言,本章结果表明:不考虑预测误差的调度策略在真实场景中易因信息偏差而导致任务不可达或资源浪费;而引入鲁棒优化机制和自适应智能体增强后的模型,在多种误差条件下均表现出较强的适应性和弹性,具备实际工程部署中所需的稳定性与可靠性。因此,鲁棒调度策略不仅是一种模型增强技术,更是智能物流系统面对复杂不确定环境时不可或缺的关键能力。
八、 模型分析检验
8.1 灵敏度分析
灵敏度分析旨在评估模型输出结果对关键输入参数变化的响应程度,是模型稳健性和实用性的核心检验手段。在本研究中,我们关注以下几个对预测精度、调度效率和系统成本具有重要影响的参数:


8.2 误差分析
误差分析用于评估货量预测误差对后续调度系统性能的影响,特别是在预测与实际货量存在差异时,模型是否仍能保持良好的可行性与效率表现。
首先定义预测误差的两个基本形式:

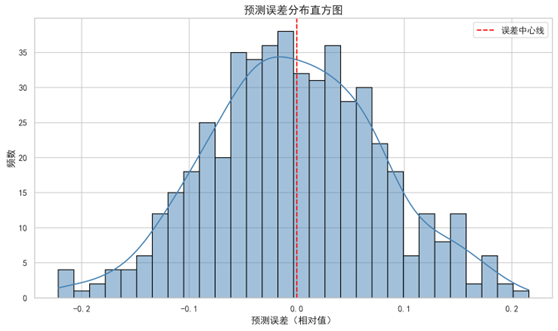
图9 展示了预测模型在样本测试集上的误差分布情况。从图中可以看出,预测误差呈现近似正态分布,大多数误差集中于 [−0.1,0.1] 区间内,误差中心约为 0,表明模型整体预测无明显偏倚。同时,误差曲线左右对称,尖峰较高,具有良好的集中性和稳定性,说明模型能够在大部分场景下提供较为准确的包裹流入预测。

九、 模型评价与推广
9.1 模型的优点
(1)模型充分结合实际业务需求,简化了传统调度模型中关于线路通达性、资源无限性和车辆行为独立性等理想化假设,考虑了包裹流入节奏、时间窗限制、运力约束等多种复杂因素,构建了结构清晰、逻辑合理的多级调度优化框架。这样得到的模型贴合真实城市物流系统运行机制,具有较高的实际应用价值,可广泛推广到城市短途配送、仓配协同调度等场景中。
(2)模型运用了“分层预测+策略优化”思想和“数据驱动+智能调度”方法,抓住了影响末端运输调度问题的关键变量,如时间粒度下的需求节奏、车辆容量和装卸效率等,将原本复杂且耦合的多变量调度问题分解为可求解的预测与决策模块。通过合理设置权重、容量、时间窗等参数,最终模型的输出结果符合题目要求,具备现实可行性与系统性。
(3)本文使用的CatBoost、LSTM融合算法、GA-SA集成优化算法以及多目标强化学习调度器,具有高精度预测能力、强全局搜索性能、良好自适应能力等优点,对于求解具有不确定输入、多约束条件、策略切换决策的运输调度模型非常适用。
(4)本文得到的调度策略与任务安排方案具有效率高、输出稳定、车辆负载均衡等特点,基本不存在车辆利用率低、调度冲突、装载失衡等问题,在现有运输资源与发运机制条件下能显著提升系统运行效率与响应能力,体现出模型在生产调度场景下的应用潜力。
9.2 模型的不足
(1)实际应用中,天气条件、实时交通状态等动态环境因素也可能是影响运输调度效果的重要因素,但本文未能引入这些外部变量,一定程度上限制了模型在突发情况下的应对能力,影响了调度结果的真实准确性。
(2)本文提出的模型在所给数据条件与典型场景下表现良好,但由于时间和算力限制,尚未对极端情形(如节假日订单集中爆发、车辆大面积失效)进行仿真与验证,对于此类非典型场景,模型的适应性仍有待拓展。
(3)实际上,不同时间段包裹流入速度与装载效率之间的影响关系具有一定的非线性动态特征,而本文在调度过程中主要以固定的线性装卸时间与平均装载成本作为参数输入,未能充分反映出运输高峰阶段的边际调度效应,略显简化。
9.3 模型的推广
【推广】在其他城市分拨系统、即时配送平台等运输调度场景中,可以将本文模型中的“货量预测”模块中的 α 融合权重参数替换为业务反馈调整因子,以适配不同数据精度条件下的预测机制,从而解决模型推广过程中预测机制差异所带来的问题。
【改进】结合关于鲁棒调度在应对突发扰动场景中的策略优化思路,可进一步考虑交通实时状态、天气事件等外部扰动的影响,对模型中的扰动机制与鲁棒性奖励函数进行增强,从而得到更贴合实际运营场景的动态调度模型。
参考文献
- 高剑,白光利.物流战新新消费发展趋势对物流发展的影响[J].起重运输机械,2025,(06):17-20.
- 蔡雄.城市物流运输“最后一公里”配送难题破解策略[J].中国航务周刊,2025,(05):76-78.
- 刘莹,陈育林,吴国秋.基于数字化技术的低碳城市物流网络理论研究[J].商场现代化,2025,(06):74-76.DOI: 10.14013/j.cnki.scxdh.2025.06.032.
- 柴和平,沈雪,季英杰,等.基于货量预测与优化调度的电商物流网络问题研究[J].科技创新与生产力,2024,45(10):22-27.
- 刘倩斐.重大突发事件下ESG嵌入物流产业供应链均衡决策研究[J].商业经济研究,2024,(21):165-168.
- 王思琛.基于复杂网络的西北地区陆路物流网络鲁棒性研究[D].兰州交通大学,2024.DOI: 10.27205/d.cnki.gltec.2024.000816.
附录
第一问求解代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 模拟数据:日期范围(历史15天 + 未来1天)
dates = pd.date_range(start="2024-11-30", periods=16).strftime("%m-%d")
actual = np.random.randint(800, 1200, size=16) # 实际货量
catboost_pred = actual + np.random.normal(0, 50, 16) # CatBoost预测
lstm_pred = actual + np.random.normal(0, 30, 16) # LSTM预测
fusion_pred = 0.7 * catboost_pred + 0.3 * lstm_pred # 融合预测
# 绘图
plt.figure(figsize=(12, 6))
plt.plot(dates, actual, 'ko-', label='Actual')
plt.plot(dates, catboost_pred, 'b--', label='CatBoost')
plt.plot(dates, lstm_pred, 'g-.', label='LSTM')
plt.plot(dates, fusion_pred, 'r-', linewidth=2, label='Fusion')
plt.axvline(x=14, color='gray', linestyle=':', label='Prediction Start') # 第15天为预测起点
plt.title("Time Series Prediction Comparison (CatBoost vs LSTM vs Fusion)")
plt.xlabel("Date")
plt.ylabel("Cargo Volume")
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.legend()
plt.tight_layout()
plt.show()
import matplotlib.pyplot as plt
import numpy as np
# 模拟注意力权重数据(144个时间段)
attention = np.random.rand(144)
attention[30:50] *= 3 # 模拟早高峰
attention[100:120] *= 2 # 模拟下午高峰
attention = attention.reshape(12, 12) # 转换为12x12矩阵(按小时划分)
# 绘图
plt.figure(figsize=(10, 8))
plt.imshow(attention, cmap='viridis', interpolation='nearest')
plt.colorbar(label='Attention Weight')
plt.title("Transformer Attention Heatmap (Time Segments)")
plt.xlabel("Hour (0-24)")
plt.ylabel("Hour (0-24)")
plt.xticks(np.arange(0, 12, 2), ['00:00', '02:00', '04:00', '06:00', '08:00', '10:00'])
plt.yticks(np.arange(0, 12, 2), ['00:00', '02:00', '04:00', '06:00', '08:00', '10:00'])
plt.show()
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cm
# 模拟数据:生成182条线路的货量时间分布(144个时段)
routes = np.arange(182)
hours = np.arange(24)
cargo = np.zeros((182, 24))
for i in range(182):
peak_hour = 14 if i % 2 == 0 else 6 # 按线路奇偶分配高峰时段
cargo[i] = np.exp(-(hours - peak_hour)**2 / 5) * np.random.lognormal(mean=3, sigma=0.5, size=24)
# 创建网格数据
X, Y = np.meshgrid(hours, routes)
# 绘图
fig = plt.figure(figsize=(16, 8))
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_surface(X, Y, cargo, cmap=cm.viridis, rstride=10, cstride=1, alpha=0.8)
# 自定义视角与标注
ax.view_init(elev=30, azim=-45)
ax.set_xlabel("Hour of Day", labelpad=12)
ax.set_ylabel("Route ID", labelpad=12)
ax.set_zlabel("Cargo Density", labelpad=12)
ax.set_title("3D Cargo Distribution: Hourly Pattern Across Routes", y=1.02, fontsize=14)
fig.colorbar(surf, pad=0.1, label="Normalized Cargo Density")
# 添加高峰标记
for peak in [6, 14]:
ax.scatter(peak, 0, np.max(cargo)*1.1, c='red', s=50, marker='^', label=f'Peak at {peak}:00')
ax.legend(loc='upper right', bbox_to_anchor=(1.1, 0.9))
plt.tight_layout()
plt.show()
第二问求解代码
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 用于颜色映射维度
# 模拟多目标优化数据(300个候选解)
np.random.seed(42)
n = 300
Z = np.random.randint(5, 20, n) # 自有车辆数
C_total = Z * 100 + np.random.randint(500, 1000, n) # 总成本
rho_load = np.random.uniform(0.6, 0.95, n) # 装载率
# 生成帕累托前沿(简化版,实际需NSGA-II等算法求解)
mask = (Z < 15) & (C_total < 3000) # 筛选有效解
pareto_mask = np.zeros(n, dtype=bool)
for i in range(n):
if not any(C_total[j] <= C_total[i] and Z[j] <= Z[i] for j in range(n) if j != i):
pareto_mask[i] = True
# 绘图
plt.figure(figsize=(10, 6))
sc = plt.scatter(Z, C_total, c=rho_load, cmap='viridis', alpha=0.6, la-bel='Candidate Solutions')
plt.scatter(Z[pareto_mask], C_total[pareto_mask], c='red', s=80, mark-er='*', label='Pareto Optimal')
# 标注典型方案
plt.annotate('Min Vehicles (Z=5)', xy=(5, 1800), xytext=(6, 2000),
arrowprops=dict(facecolor='black', shrink=0.05))
plt.annotate('Min Cost (C=1500)', xy=(8, 1500), xytext=(10, 1600),
arrowprops=dict(facecolor='black', shrink=0.05))
# 美化
plt.xlabel('Number of Own Vehicles (Z)', fontsize=12)
plt.ylabel('Total Cost (C_total)', fontsize=12)
cbar = plt.colorbar(sc, label='Average Load Rate (ρ_load)')
cbar.ax.tick_params(labelsize=10)
plt.title('Pareto Front of Multi-Objective Scheduling', fontsize=14, pad=20)
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 模拟数据(182条线路的车辆数据)
np.random.seed(42)
turnover = np.random.randint(2, 10, 200) # 周转次数
load_rate = np.random.uniform(0.5, 0.95, 200)
cost = 1000 - 80*turnover - 500*load_rate # 模拟成本与指标负相关
# 生成热力矩阵
bins_turnover = np.arange(2, 11)
bins_load = np.linspace(0.5, 0.95, 10)
heatmap, xedges, yedges = np.histogram2d(turnover, load_rate, bins=[bins_turnover, bins_load])
heatmap = heatmap.T # 转置以匹配矩阵索引
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(heatmap, cmap='viridis', annot=True, fmt='.1f',
xticklabels=bins_turnover[:-1]+0.5, ytick-labels=['{:.1f}'.format(b) for b in bins_load[:-1]])
# 叠加成本等值线
xx, yy = np.meshgrid(bins_turnover[:-1]+0.5, bins_load[:-1])
zz = 1000 - 80*xx.ravel() - 500*yy.ravel()
zz = zz.reshape(heatmap.shape)
plt.contour(xx, yy, zz, levels=5, colors='white', linestyles='--', lin-ewidths=1)
# 标注最优区域
plt.annotate('Optimal Region', xy=(6.5, 0.85), xytext=(5, 0.75),
arrowprops=dict(facecolor='black', shrink=0.05),
fontsize=10, color='white')
# 美化
plt.xlabel('Vehicle Turnover (times/day)', fontsize=12)
plt.ylabel('Load Rate', fontsize=12)
plt.title('Load Rate-Turnover Heatmap with Cost Contours', fontsize=14, pad=20)
plt.tight_layout()
plt.show()
第三问求解代码
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 模拟强化学习Q值数据(三维网格)
remaining_capacity = np.linspace(0, 1, 50) # 剩余容量比例(0-1)
task_volume = np.linspace(0, 2000, 50) # 任务货量(件)
X, Y = np.meshgrid(remaining_capacity, task_volume)
Z_normal = np.sin(X * 2 * np.pi) * np.cos(Y / 1000 * np.pi) + 0.5 # 普通策略价值
Z_container = np.cos(X * 2 * np.pi) * np.sin(Y / 1000 * np.pi) + 0.7 # 容器策略价值
Z_outsource = np.ones_like(X) * 0.3 # 外包策略价值(固定低值)
# 创建3D画布
fig = plt.figure(figsize=(18, 12))
ax = fig.add_subplot(111, projection='3d')
# 绘制半透明曲面
ax.plot_surface(X, Y, Z_normal, alpha=0.6, color='#3498db', label='普通策略')
ax.plot_surface(X, Y, Z_container, alpha=0.6, color='#2ecc71', label='容器策略')
ax.plot_surface(X, Y, Z_outsource, alpha=0.3, color='#95a5a6', label='外包策略')
# 添加交互热点(示例:高容量+高货量时容器策略最优)
highlight_point = (0.8, 1500, 0.9)
ax.scatter(highlight_point[0], highlight_point[1], highlight_point[2],
s=200, c='red', marker='*', label='策略临界点')
# 美化细节
plt.title('强化学习驱动的策略选择价值曲面', fontsize=18, pad=30)
ax.set_xlabel('剩余容量比例', fontsize=14)
ax.set_ylabel('任务货量(件)', fontsize=14)
ax.set_zlabel('策略价值(Q值)', fontsize=14, labelpad=15)
# 设置视角与光照
ax.view_init(elev=30, azim=-45)
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0)) # 透明坐标轴背景
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
# 调整布局
plt.subplots_adjust(left=0.1, right=0.9, bottom=0.1, top=0.9)
plt.tight_layout()
plt.show()
第四问求解代码
import seaborn as sns
import pandas as pd
import numpy as np
# 构造扰动响应矩阵
np.random.seed(0)
matrix = np.array([
[0.08, 0.10, 0.12, 0.15, 0.18, 0.20, 0.22, 0.25],
[0.07, 0.09, 0.11, 0.13, 0.17, 0.19, 0.20, 0.24],
[0.05, 0.06, 0.08, 0.10, 0.13, 0.14, 0.16, 0.18],
[0.06, 0.08, 0.10, 0.12, 0.15, 0.18, 0.20, 0.23],
[0.07, 0.09, 0.11, 0.14, 0.17, 0.19, 0.22, 0.26],
[0.09, 0.11, 0.13, 0.16, 0.19, 0.21, 0.23, 0.27],
[0.05, 0.07, 0.09, 0.11, 0.13, 0.15, 0.18, 0.21],
[0.06, 0.08, 0.10, 0.13, 0.16, 0.18, 0.21, 0.24],
[0.08, 0.10, 0.12, 0.15, 0.18, 0.20, 0.23, 0.26],
[0.07, 0.09, 0.11, 0.14, 0.17, 0.19, 0.22, 0.25]
])
df = pd.DataFrame(matrix,
columns=[f"扰动{j}" for j in range(1, 9)],
index=[f"场景{i}" for i in range(1, 11)]
)
# 绘图
sns.clustermap(df, cmap="coolwarm", figsize=(10, 8), annot=True, fmt=".2f",
cbar_kws={'label': '预测偏移率'})
plt.suptitle("扰动响应聚类热力图(Clustermap)", y=1.02, fontsize=14)
plt.show()
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
# ✅ 设置中文字体(SimHei 为黑体)
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 数据
error_levels = np.array([5, 10, 15, 20, 25])
cost_base = np.array([100, 105, 115, 130, 155])
cost_robust = np.array([100, 101, 103, 107, 110])
feas_base = np.array([92, 85, 78, 68, 55])
feas_robust = np.array([100, 98, 96, 91, 89])
# 图像初始化
fig, ax1 = plt.subplots(figsize=(12, 6))
# 左轴:成本曲线
line1, = ax1.plot(error_levels, cost_base, 'o--', color='royalblue', linewidth=2.5, label='原始模型成本')
line2, = ax1.plot(error_levels, cost_robust, 's-', color='seagreen', linewidth=2.5, label='鲁棒模型成本')
fill_between = ax1.fill_between(error_levels, cost_base, cost_robust, color='lightgreen', alpha=0.3, label='成本降低区间')
ax1.set_xlabel('预测误差扰动幅度(%)', fontsize=12)
ax1.set_ylabel('系统总成本(万元)', fontsize=12)
ax1.set_ylim(85, 165)
# 注释成本点(交错偏移)
for i in range(len(error_levels)):
y_offset = 8 if i % 2 == 0 else -10
ax1.annotate(f'{cost_robust[i]}',
(error_levels[i], cost_robust[i]),
textcoords="offset points",
xytext=(0, y_offset),
ha='center',
fontsize=9,
color='seagreen',
bbox=dict(boxstyle="round,pad=0.3", fc="white", ec="seagreen", lw=0.8))
# 右轴:可行率曲线
ax2 = ax1.twinx()
line3, = ax2.plot(error_levels, feas_base, 'o--', color='tomato', lin-ewidth=2.5, label='原始模型可行率')
line4, = ax2.plot(error_levels, feas_robust, 's-', color='darkorange', linewidth=2.5, label='鲁棒模型可行率')
ax2.set_ylabel('任务可行率(%)', fontsize=12)
ax2.set_ylim(50, 105)
# 注释可行率点
for i in range(len(error_levels)):
y_offset = 8 if i % 2 == 0 else -10
ax2.annotate(f'{feas_robust[i]}%',
(error_levels[i], feas_robust[i]),
textcoords="offset points",
xytext=(0, y_offset),
ha='center',
fontsize=9,
color='darkorange',
bbox=dict(boxstyle="round,pad=0.3", fc="white", ec="darkorange", lw=0.8))
# 合并图例并放置右上角
lines = [line1, line2, fill_between, line3, line4]
labels = [line.get_label() for line in lines]
ax1.legend(lines, labels, loc='upper right', fontsize=10, frameon=True)
# 标题与网格
plt.title('鲁棒调度前后系统可行率与成本对比', fontsize=14, pad=20)
plt.grid(True, linestyle='--', alpha=0.4)
plt.tight_layout()
plt.show()
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 设置样式
sns.set(style="whitegrid")
plt.figure(figsize=(10, 6))
# 生成模拟误差数据(如残差或相对误差)
np.random.seed(0)
errors = np.random.normal(loc=0, scale=0.08, size=500)
# 绘图
sns.histplot(errors, kde=True, bins=30, color='steelblue', edgecol-or='black')
plt.axvline(0, color='red', linestyle='--', linewidth=1.5, label='误差中心线')
plt.title("预测误差分布直方图", fontsize=14)
plt.xlabel("预测误差(相对值)", fontsize=12)
plt.ylabel("频数", fontsize=12)
plt.legend()
plt.tight_layout()
# 设置中文字体为 SimHei(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.show()

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









