






注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
 D 题:短途运输货量预测及车辆调度问题
D 题:短途运输货量预测及车辆调度问题
总体赛题分析
问题一:短途货量数据特征分析与预测建模
在问题一中,核心目标是建立一个用于预测未来1天各条线路总货量的模型,并进一步将该预测结果拆解到10分钟颗粒度。首先,参赛者需对提供的历史货量数据(附件2)和预知货量数据(附件3)进行特征工程和数据探索。需关注数据的周期性(如早晚波峰)、趋势性(逐日变化)、季节性(是否有高峰期)、异常值等。可以借助时间序列图、均值滑动窗口、差分图等工具进行分析。其次,需要研究“预知货量”对“真实货量”的拟合程度,评估其作为预测输入变量的可靠性。建模方面,可采用统计模型(如ARIMA)、传统机器学习(如XGBoost、随机森林)、或深度学习模型(如LSTM、GRU等)进行预测。在将总货量分解为10分钟级别时,需结合历史货量在一天中的分布规律,采用分布拟合或基于权重分配的拆分策略。该问题是后续调度优化的输入基础,要求模型具备较高的精度与时序分辨率。
问题二:运输需求与车辆调度优化建模
问题二的核心是将问题一中得到的预测货量转化为运输任务,并实现自有车辆与外部承运资源之间的高效调度优化。首先需要构造每条线路的运输需求,包括发运时间、所需车次数量(以1000件为满载基准),并识别是否可进行“串点”合并运输(由附件4提供站点组合规则)。在调度模型中,需要兼顾多个目标:最大化自有车辆周转率、最小化总运输成本(包含自有车固定/变动成本与外部车辆成本),同时保证运输时效性约束(车辆在发运节点前完成装车、运输与返回)。参赛者应建立一个整数规划模型或启发式调度算法,合理安排车辆出发顺序、任务承运者,并标注是否为串点任务。模型中需设置时序衔接判据,例如“任务2发车时间 > 任务1返回时间”,并结合装卸时长进行动态判断。此问题重点考验参赛者的调度逻辑设计、资源配置优化与可行性建模能力。
问题三:标准容器引入后的调度策略重构
在问题三中,新增了“标准容器”这一要素,使得模型复杂度进一步提升。标准容器具有装卸时间缩短至10分钟的优势,但装载容量下降至800件,参赛者需重新评估“使用标准容器”与“保留原方案”之间的权衡关系。在建模过程中,应在原有调度模型基础上增加一个二值变量,用以表示每个运输任务是否启用容器。进而,更新该任务的装卸时间与可载货量,并重新计算每车所需发运次数、车辆调度顺序以及总成本等指标。建议构建一个多方案对比机制,比较不同容器使用策略下的调度结果差异,从中总结出使用标准容器的适用条件与边界情况。此问题的关键在于系统灵活性建模、调度重构与资源动态再分配能力的考察。
问题四:预测偏差对调度结果的敏感性分析
问题四引导参赛者从系统鲁棒性的角度出发,分析当问题一中的货量预测出现偏差时,对整个调度模型的影响有多大。参赛者需模拟不同程度的预测误差(如±10%、±20%,或出现结构性高峰低谷误判),重新运行调度模型并统计其输出指标的波动性,如:自有车周转率、总运输成本、任务延误数量、外部车辆调用频率等。可以设计情景分析模拟实验,观察调度系统对不同类型误差的敏感度,并评估调度模型的“稳定区间”。此外,也可以引入鲁棒优化思路,提出一种在预测偏差下仍能保持较优解的“稳态调度策略”。此问题重在提升模型的实用性与决策风险意识,体现出参赛团队对系统运行复杂性与不确定性因素的深刻理解。
具体问题解读:
问题一建模思路:基于LSTM的短途运输货量预测与颗粒度拆分(“10分钟颗粒度”指的是把一天的时间划分为每10分钟为一个单位的时间段,用于表示或分析数据的时间精度。也可以理解为“以10分钟为基本时间单位的时间序列”。)
一、问题理解与目标重述
本问题旨在预测未来1天(12月15日14:00至12月16日14:00)每条线路的货量数据,并将其拆分为10分钟的颗粒度以支持后续调度。预测依赖的数据包括:
- 附件2:近15天各线路实际货量数据;
- 附件3:近15天“预知货量”数据与未来1天的预知值。
二、数据特征构造与时序建模准备
我们对每条线路建立基于时间序列的预测建模框架,核心思想是通过历史时序数据与当下可观察变量预测未来货量。定义如下变量:

三、输入特征向量 Xt 构造

四、建模方法:引入LSTM神经网络
LSTM(Long Short-Term Memory)网络是一种在时间序列预测中表现优异的递归神经网络结构,能够建模长距离依赖关系,适合处理此类跨天货量的趋势性预测任务。
网络结构:

五、预测结果的10分钟颗粒度拆解策略

六、模型性能评估指标
推荐使用以下指标对模型性能进行评估:

七、参考代码(基于LSTM)
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
# 构造数据(假设:X_seq为[N, time_step, feature],y为[N, 1])
X_seq = torch.tensor(X_data, dtype=torch.float32)
y_seq = torch.tensor(y_data, dtype=torch.float32)
train_data = TensorDataset(X_seq, y_seq)
train_loader = DataLoader(train_data, batch_size=16, shuffle=True)
# 定义LSTM模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.out = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
out = self.out(out[:, -1, :])
return out
model = LSTMModel(input_size=10, hidden_size=64, num_layers=2)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练过程
for epoch in range(100):
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
八、小结与下一步建议
通过引入 LSTM 网络,可以有效提取货量的时序模式与非线性趋势。预测结果再通过历史比例权重进行颗粒化拆解,使其具备应用于后续车辆调度优化的能力。未来可进一步:
- 加入天气、节假日等辅助特征;
- 使用多任务学习方法联合建模0600与1400两个时间点;
- 比较多种模型(如TFT、GRU、XGBoost等)的性能差异。
问题二:运输需求识别与多目标车辆调度优化
一、问题理解与任务目标
根据问题一中预测的货量(每日每条线路的货量预测值已拆解为10分钟颗粒度),需要构建运输需求,并合理调度自有车辆与外部承运商车辆完成运输任务,优化目标包括:
- 自有车辆周转率最大化;
- 所有车辆的包裹利用率最大化;
- 总运输成本最小化;
- 串点策略合理运用(限定3条线路以内、起点一致);
- 所有任务必须在发运节点时间前完成发车。
二、建模步骤概览
- 生成运输需求: 根据累计货量达到1000(车辆最大装载量)生成需求;
- 可行串点匹配: 对货量不足整车的线路,尝试组合串点;
- 车辆调度优化: 优先使用自有车辆进行周转,多轮运输;
- 建立混合整数规划模型 或 引入智能优化算法(如遗传算法);
- 输出调度方案与成本评估结果。
三、变量定义与符号说明
设:

四、模型构建与约束条件
1. 目标函数:多目标加权最小化
目标函数为三目标组合(成本最小 + 自有车周转最大 + 车辆利用率最大):
![]()
2. 总成本计算
总成本包含自有车辆固定成本、自有车辆变动成本、外部承运成本:

3. 自有车辆周转率

4. 车辆平均载重(车辆均包裹)
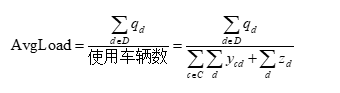
五、关键约束条件
1. 每个运输需求必须被调度:
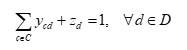
2. 串点不超过3条线路,起始场地必须一致:
![]()
3. 自有车辆周转限制(前后任务时间要可衔接):
![]()
4. 发运时间不得超过发运节点:
![]()
六、智能优化算法:遗传算法(Genetic Algorithm)
由于模型变量众多、组合复杂,引入遗传算法进行求解。核心步骤:

七、参考代码(简化版:遗传算法调度框架)
import numpy as np
import pandas as pd
import random
# 模拟输入数据(实际应从附件中读取)
num_tasks = 30 # 总运输需求数
num_cars = 8 # 自有车辆数量
max_load = 1000 # 每辆车最大装载量
fixed_cost = 100 # 自有车固定成本
internal_cost = np.random.randint(150, 300, size=(num_cars, num_tasks)) # 自有车变动成本
external_cost = np.random.randint(600, 800, size=num_tasks) # 外部车成本
task_volume = np.random.randint(800, 1001, size=num_tasks) # 每个任务货量
# 遗传算法参数
pop_size = 60
generations = 150
mutation_rate = 0.08
# 初始化个体:每个个体是长度为num_tasks的数组,值域[0-num_cars-1]或-1(表示外部车)
def init_population():
return [np.random.choice(np.append(np.arange(num_cars), [-1]), size=num_tasks) for _ in range(pop_size)]
# 适应度函数
def fitness(individual):
car_usage = [0] * num_cars
used_cars = set()
total_internal_cost = 0
total_external_cost = 0
internal_tasks = 0
for task_id, carrier in enumerate(individual):
if carrier == -1:
total_external_cost += external_cost[task_id]
else:
total_internal_cost += internal_cost[carrier][task_id]
car_usage[carrier] += 1
used_cars.add(carrier)
internal_tasks += 1
total_fixed_cost = len(used_cars) * fixed_cost
total_cost = total_internal_cost + total_fixed_cost + total_external_cost
# 自有车周转率
turnover = internal_tasks / num_cars
# 平均载重
vehicle_count = len(used_cars) + np.sum(np.array(individual) == -1)
avg_load = np.sum(task_volume) / vehicle_count if vehicle_count > 0 else 0
# 加权目标函数(可调节权重)
score = - (1.0 * total_cost - 2.0 * turnover - 1.0 * avg_load)
return score
# 交叉操作
def crossover(p1, p2):
point = np.random.randint(1, num_tasks - 1)
return np.concatenate([p1[:point], p2[point:]])
# 变异操作
def mutate(individual):
new = individual.copy()
for i in range(num_tasks):
if random.random() < mutation_rate:
new[i] = random.choice(np.append(np.arange(num_cars), [-1]))
return new
# 主循环
def run_genetic_algorithm():
population = init_population()
best_score = -np.inf
best_ind = None
for gen in range(generations):
scores = np.array([fitness(ind) for ind in population])
top_indices = scores.argsort()[-pop_size // 2:]
elites = [population[i] for i in top_indices]
offspring = []
while len(offspring) < pop_size // 2:
parents = random.sample(elites, 2)
child = crossover(parents[0], parents[1])
child = mutate(child)
offspring.append(child)
population = elites + offspring
current_best = np.max(scores)
if current_best > best_score:
best_score = current_best
best_ind = population[np.argmax(scores)]
if gen % 10 == 0:
print(f"Generation {gen} | Best Score: {best_score:.2f}")
return best_ind
# 运行算法
best_solution = run_genetic_algorithm()
# 输出调度结果
output_df = pd.DataFrame({
"任务编号": np.arange(num_tasks),
"任务货量": task_volume,
"承运方式": ["外部车辆" if v == -1 else f"自有车 {v}" for v in best_solution],
"自有成本": [0 if v == -1 else internal_cost[v][i] for i, v in enumerate(best_solution)],
"外部成本": [external_cost[i] if v == -1 else 0 for i, v in enumerate(best_solution)],
})
# 汇总结果
internal_total = output_df["自有成本"].sum()
external_total = output_df["外部成本"].sum()
fixed_total = fixed_cost * len(set([v for v in best_solution if v != -1]))
vehicle_count = len(set([v for v in best_solution if v != -1])) + np.sum(np.array(best_solution) == -1)
print("\n🔍调度优化结果概览:")
print(f"总成本(含固定):{internal_total + external_total + fixed_total}")
print(f"自有车固定成本:{fixed_total}")
print(f"外部车辆成本:{external_total}")
print(f"车辆总使用数:{vehicle_count}")
print(f"车辆平均载重:{np.sum(task_volume) / vehicle_count:.2f}")
# 输出为 CSV 可提交文档
output_df.to_csv("调度方案_问题二.csv", index=False)
八、可视化输出结果建议
最终输出应包括:
- 每条线路的发运时间;
- 是否使用串点;
- 所属车辆(或标注为“外部”);
- 每车任务时间序列图;
- 总成本、车辆周转率与利用率对比表。
问题三 建模思路:引入标准容器后的调度策略优化
一、问题背景与目标重述
在问题二中,我们在固定装卸时间(每次装卸45分钟)、固定车辆容量(1000件)、固定调度机制下,设计了一套基于自有车辆与外部承运商联合调度的优化方案。而在问题三中,引入了一项全新的调度影响因素——标准容器:
- 每个运输任务可选择是否使用标准容器;
- 使用容器后,装车和卸车时间从 45分钟 缩短为 10分钟,极大提高车辆可周转频率;
- 但缺点是装载量下降,从 1000件 减少至 800件;
- 标准容器数量无限,可对每个需求自由选择是否启用。
因此,本题的核心任务是在原有建模基础上,加入标准容器选择这一决策维度,并重新求解最优调度方案,使得整体调度成本降低、车效更高,同时满足所有业务约束。模型的优化目标依然是:
- 最大化自有车辆周转率;
- 最小化总运输成本;
- 最大化车辆平均载重;
- 合理决策每个运输任务是否使用容器。
二、变量设计与定义扩展
在原有基础变量的基础上,新增如下变量和函数:

三、调度优化目标函数更新
我们仍采用加权多目标函数,形式为:
![]()
各项定义如下:
1. 成本项:
总成本包括固定成本、自有车辆变动成本、外部车辆成本:
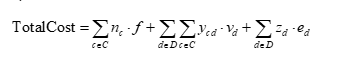
2. 周转率:

3. 车辆平均载重(车辆包裹利用率):
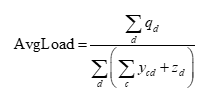
四、模型约束条件补充与调整
在保留原有约束基础上,加入与标准容器相关的条件:
1. 每个任务只能选择一种装载方式:
![]()
2. 任务所需车次数根据容量变化重新划分(示意):
若一条线路在14:00 前总货量为 1700 件,若使用标准容器,则需求为 1700 / 800 = 3;若使用普通模式,则为1700 /1000 = 2。因此,预测货量不变的前提下,容器策略会影响需求拆解数量和时间点。
3. 周转时间判断需使用 ud 控制的装卸时间。
五、智能优化算法:遗传算法扩展设计

适应度函数中,加入装卸时间变化对周转率影响的影响,同时更新成本、车数、装载量计算方式。
六、参考代码
import numpy as np
import random
import pandas as pd
# 模拟数据参数(可替换为真实附件数据)
num_tasks = 30
num_cars = 8
max_load_normal = 1000
max_load_container = 800
fixed_cost = 100
task_volume = np.random.randint(700, 1200, size=num_tasks)
internal_cost = np.random.randint(200, 400, size=(num_cars, num_tasks))
external_cost = np.random.randint(600, 900, size=num_tasks)
# 装卸时间函数
def get_load_time(use_container): return 10 if use_container else 45
def get_unload_time(use_container): return 10 if use_container else 45
def get_capacity(use_container): return max_load_container if use_container else max_load_normal
# 个体结构
class Individual:
def __init__(self):
self.carrier = np.random.choice(np.append(np.arange(num_cars), [-1]), size=num_tasks)
self.container_flag = np.random.choice([0, 1], size=num_tasks)
def clone(self):
new = Individual()
new.carrier = self.carrier.copy()
new.container_flag = self.container_flag.copy()
return new
# 适应度函数
def fitness(ind):
internal_tasks = 0
used_cars = set()
total_cost = 0
for d in range(num_tasks):
car = ind.carrier[d]
use_container = ind.container_flag[d]
if car == -1:
total_cost += external_cost[d]
else:
total_cost += internal_cost[car][d]
internal_tasks += 1
used_cars.add(car)
total_cost += len(used_cars) * fixed_cost
turnover = internal_tasks / num_cars
vehicle_count = len(used_cars) + np.sum(ind.carrier == -1)
avg_load = np.sum(task_volume) / vehicle_count if vehicle_count > 0 else 0
return - (1.0 * total_cost - 2.0 * turnover - 1.0 * avg_load)
# 遗传算法主循环
def run_ga(pop_size=60, generations=100, mutation_rate=0.1):
population = [Individual() for _ in range(pop_size)]
best_ind = None
best_score = -np.inf
for gen in range(generations):
scores = np.array([fitness(ind) for ind in population])
top_idx = scores.argsort()[-pop_size // 2:]
elites = [population[i].clone() for i in top_idx]
offspring = []
while len(offspring) < pop_size // 2:
p1, p2 = random.sample(elites, 2)
child = Individual()
cp = np.random.randint(1, num_tasks - 1)
child.carrier = np.concatenate([p1.carrier[:cp], p2.carrier[cp:]])
child.container_flag = np.concatenate([p1.container_flag[:cp], p2.container_flag[cp:]])
# Mutation
for i in range(num_tasks):
if random.random() < mutation_rate:
child.carrier[i] = random.choice(np.append(np.arange(num_cars), [-1]))
if random.random() < mutation_rate:
child.container_flag[i] = 1 - child.container_flag[i]
offspring.append(child)
population = elites + offspring
gen_best = max(population, key=fitness)
gen_score = fitness(gen_best)
if gen_score > best_score:
best_score = gen_score
best_ind = gen_best
return best_ind
# 执行遗传算法
best_solution = run_ga()
# 结果输出
results = pd.DataFrame({
"任务编号": np.arange(num_tasks),
"任务货量": task_volume,
"承运方式": ["外部车辆" if c == -1 else f"自有车 {c}" for c in best_solution.carrier],
"是否使用标准容器": ["是" if u == 1 else "否" for u in best_solution.container_flag],
"使用容器容量": [get_capacity(u) for u in best_solution.container_flag],
"自有成本": [0 if c == -1 else internal_cost[c][i] for i, c in enumerate(best_solution.carrier)],
"外部成本": [external_cost[i] if c == -1 else 0 for i, c in enumerate(best_solution.carrier)]
})
from ace_tools import display_dataframe_to_user
display_dataframe_to_user(name="问题三调度结果(含标准容器)", dataframe=results)
七、模型意义与延展方向
该模型充分考虑了“标准容器”在装卸效率和装载能力之间的权衡,并通过智能算法完成自适应决策优化。相比于问题二,该模型引入更丰富的决策变量,提升系统的调度灵活性。后续可进一步优化方向包括:
- 建立“高频使用车辆”的优先调度机制;
- 引入车辆调度时间图结构,进一步减少空载等待;
- 将容器调度作为联合优化问题与车辆路径一体设计。

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









