








步骤 1 # 预训练
步骤 1 # 预训练
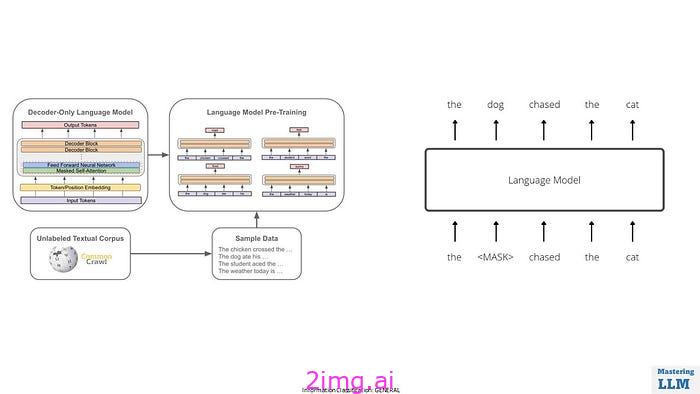
在预训练阶段,该模型被训练为互联网规模数据上的下一个单词预测器。
在预训练阶段
- 从互联网上收集大量多样化的数据集。此数据集包含来自各种来源的文本,以确保模型能够学习广泛的语言模式。
- 清理和预处理数据以消除噪音、格式问题和不相关的信息。
- 将清理后的文本数据标记为更小的单元,例如单词或子词片段(例如,字节对编码或WordPiece)。
- 对于 GPT-3 这样的 LLM,Transformer 架构因其在处理序列数据方面的有效性而被广泛使用。
- 大型语言模型 (LLM) 的预训练是通过使用海量数据集训练模型预测文本序列中的下一个单词来使其能够理解和生成类似人类的语言。
推出面试准备新课程
我们推出了新课程“大型语言模型(LLM)面试问答”系列。
该计划旨在弥补全球人工智能行业的就业差距。它包括来自 FAANG 和财富 500 强等顶级公司的 100 多个问题和答案以及100 多个自我评估问题。
该课程提供定期更新、自我评估问题、社区支持和全面的课程,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









