







RAG 或检索增强生成,使 LLM 能够从一个或多个数据源检索信息,并使用这些信息来回答用户查询。设置基本的 RAG 系统相对简单,但开发一个既强大又可靠的系统却面临许多挑战和陷阱,尤其是在优化计算效率时。
在本篇博文中,我们将探讨开发 RAG 系统时常见的陷阱,并介绍旨在提高检索质量、最大限度地减少幻觉和处理复杂查询的先进技术。在阅读完本文后,您将更深入地了解构建 RAG 系统所涉及的复杂性,并了解如何开始解决这些问题。
从基础到高级 RAG
下面是大多数人使用的 RAG 基本流程图。它显示了查询 -> 检索 -> 答案的基本流程
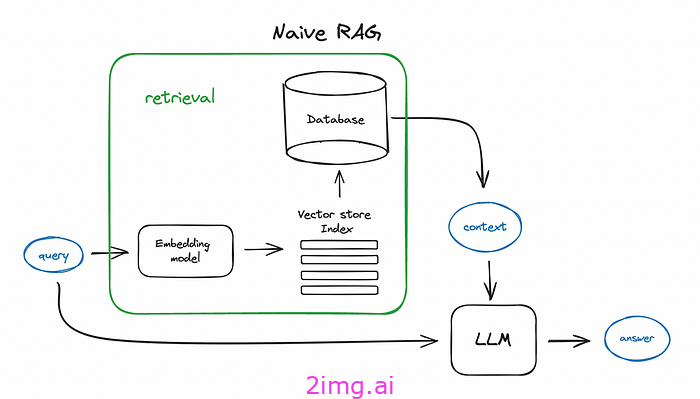
基本 RAG 流程。图表来源
上面我们看到查询 -> 检索 -> 回答的基本流程包含许多步骤。具体来说,它涉及通过嵌入模型将查询转换为嵌入,然后查找与数据源现有数据库的相似性,选择最相关的文档,最后将其反馈给 LLM 以回答初始查询。我们可以将其写成
查询 -> 查询嵌入 -> 相似性搜索 -> 检索 -> 上下文 -> 回答
上述流程分为 5 个阶段,每个阶段都有其失败点,例如:
- 查询:用户可能没有写出好的查询
- 查询嵌入:查询模型没有创建良好的代表性嵌入
- 相似性搜索:相似性搜索遗漏了文档源中最相关的信息,或者文档源没有相关信息
- 检索:检索到的大部分信息不相关或缺乏上下文
- 上下文:回答查询时可能会使用我们过去的知识,或者不能正确使用从检索到的上下文中获取的信息
因此,为了创建一个强大而可靠的 RAG 系统,我们必须在每个阶段进行干预,如上图中的箭头所示。这就是我们所说的高级 RAG 系统:
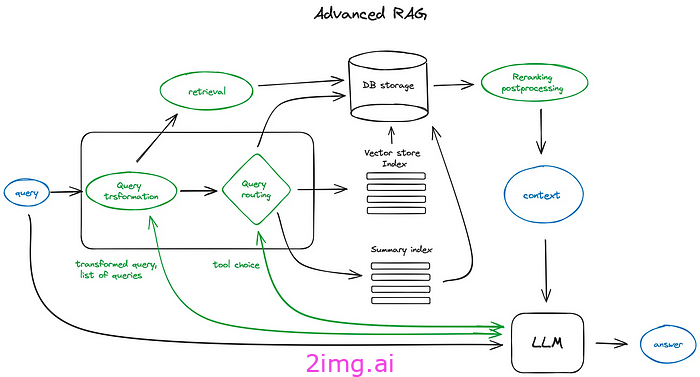
高级 RAG 流程。图表来源
不要害怕看这个!每个新添加的组件都可以非常简单自然地解释。
下面我们将详细介绍上面添加的每个新绿色组件及其动机和好处。
查询转换
很多时候
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









