







介绍:
计算机视觉和自然语言处理领域正在迅速发展,对针对特定下游任务进行微调的专用模型的需求日益增长。然而,拥有不同的微调模型有多个缺点:
1. 对于每个任务,必须存储和部署单独的模型(可以通过应用 LoRA 等方法进行微调来解决此问题)。2
. 独立微调的模型无法从相关任务的信息中获益,这限制了它们在域内和域外任务中的泛化。然而,多任务学习需要访问每个特定任务的数据集,而整合这些数据集可能很复杂。如果我们无法访问所有下游任务的数据集,但可以使用微调模型,该怎么办?想象一下,您需要一个针对一组特定任务进行微调的大型语言模型 (LLM)。您无需为下游任务收集大量数据集并进行资源密集型的微调过程,而是可以找到针对每个任务进行微调的 LLM,并合并这些模型以创建所需的模型。请注意,在拥有约 50 万个经过微调的模型的大型 Hugging Face 存储库中找到此类模型并不困难。合并多个模型最近引起了广泛关注,主要是因为它需要轻量级计算并且不需要训练数据。
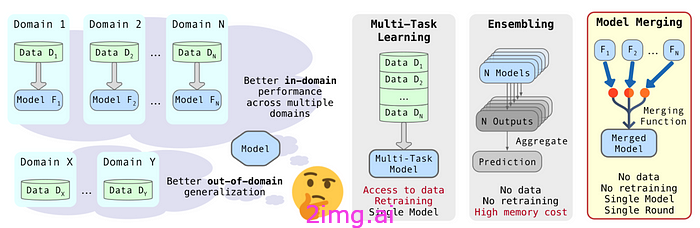
图 1 模型集成将多个模型的输出组合在一起以提高准确性,但需要更多的计算资源。多任务学习同时在多个任务上训练一个模型,需要访问所有数据集和高计算能力。然而,模型合并将预先训练的模型融合为一个,以最少的计算和不增加额外训练成本的方式利用它们的优势,提供了一种高效的解决方案(图片来自论文)。
随着人们对合并的关注度不断提高,WEBUI 和 MergeKit 等公共库已经开发出来以促进这一过程。WebUI 可以使用不同的合并技术合并经过微调的模型(例如稳定扩散)。MergeKit 是一个开源的集中式库,提供不同的合并方法。它通过高效实现适用于任何硬件的合并技术来促进模型合并。
在这里,我们将合并方法分为三大类:1. 合并具有相同架构和初始化的模型;2. 合并具有相同架构但初始化不同的模型;3. 合并具有不同架构的模型。每个类别都涉及不同的技术来有效地组合模型,下面将对此进行解释。
1. 合并具有相同架构和初始化的模型:
1.a 无需数据合并:
本节中的模型合并方法均基于线性模式连接(LMC)。LMC 建议,对于具有相同架构和初始化的模型,其检查点之间的损失可以通过低损失的线性路径连接。这意味着可以使用线性插值组合这些模型。
为了微调模型,可以应用各种配置,例如不同的学习率、随机种子和数据增强技术,从而产生不同的模型参数。模型汤
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2519
2519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









