







 本文介绍了如何通过nvidia-smi监控RTX2060显卡状态,逐步调整batch-size来找出最佳训练参数。作者分享了增大batch-size的好处与缺点,并强调了选择合适batch-size对模型收敛和性能的影响。
本文介绍了如何通过nvidia-smi监控RTX2060显卡状态,逐步调整batch-size来找出最佳训练参数。作者分享了增大batch-size的好处与缺点,并强调了选择合适batch-size对模型收敛和性能的影响。
目录
查看服务器最大承受的batch-size
先介绍一下nvidia-smi命令页面参数都是啥意思

更详细的参考这位博主的:Nvidia-smi简介及常用指令及其参数说明_小C的博客-CSDN博客_nvidia
实时检测显卡状态的窗口:
watch -n 0.1 -d nvidia-smi效果如下图:
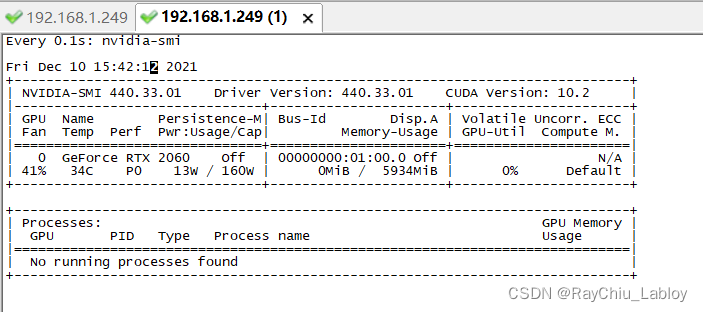
我这里是RTX 2060 6G显存。
先定一个比较大的batch值训练并观察显卡动态信息

我这里先尝试batch为64,开始训练,观察显卡动态信息:
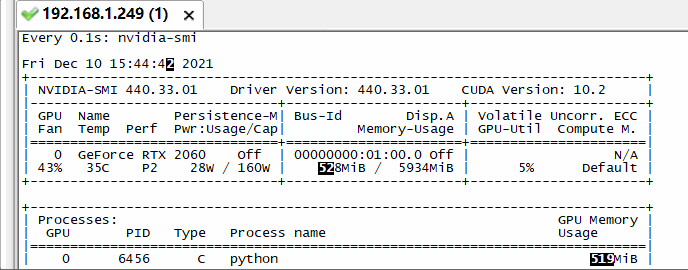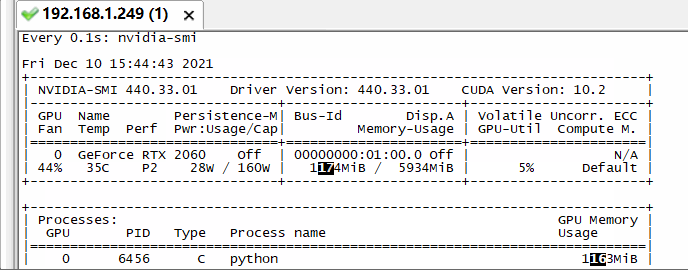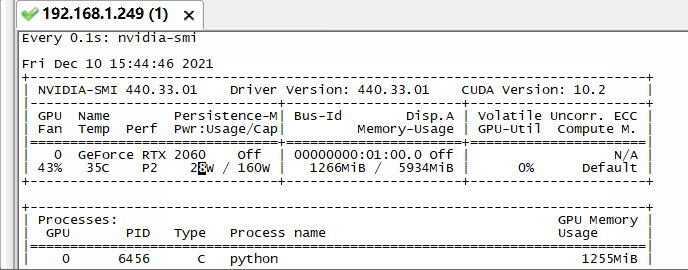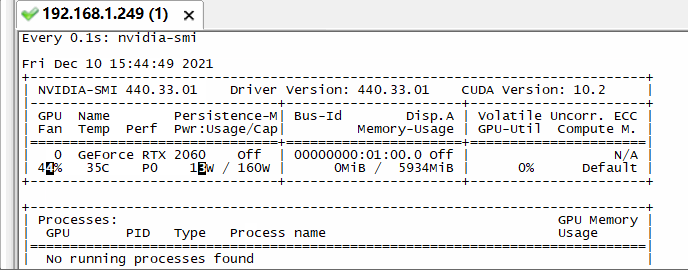
发现突然显存就满了,然后最后归零后提示没有进程了,再看训练页面:
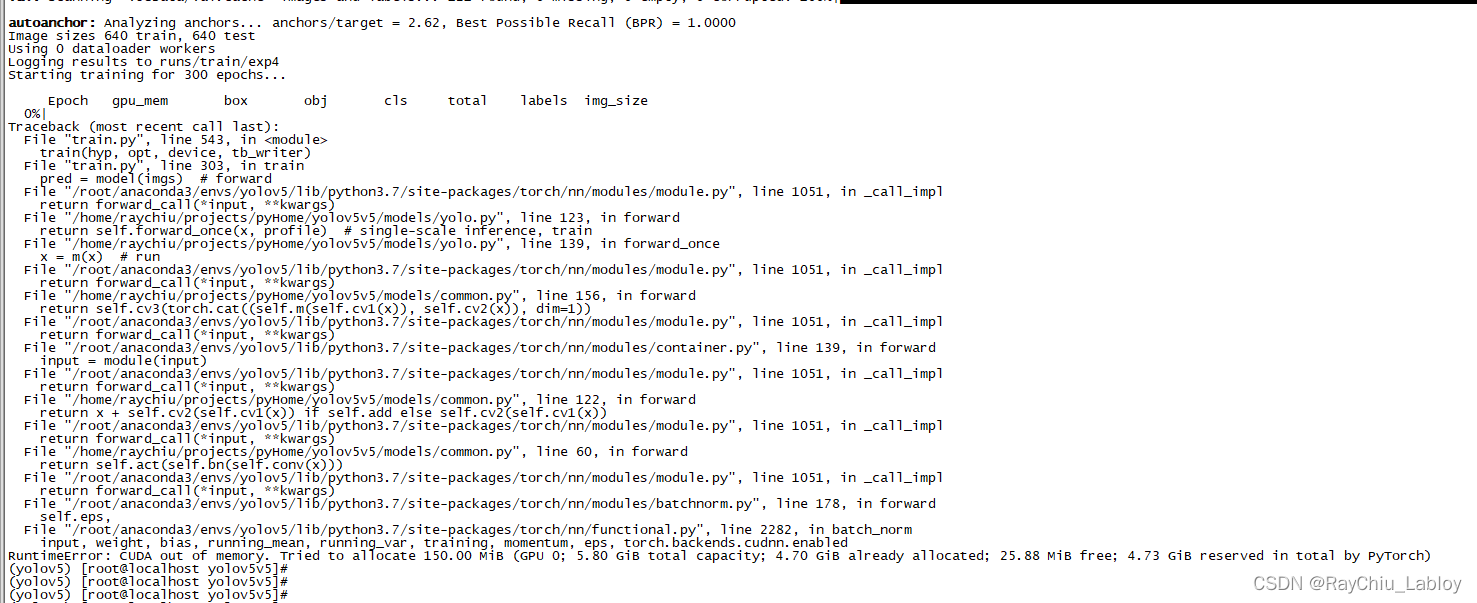
OOM,芭比Q了
然后我们再逐次降低batch值再次测试
我这里由64降到32再到16,最后到8才跑起来...
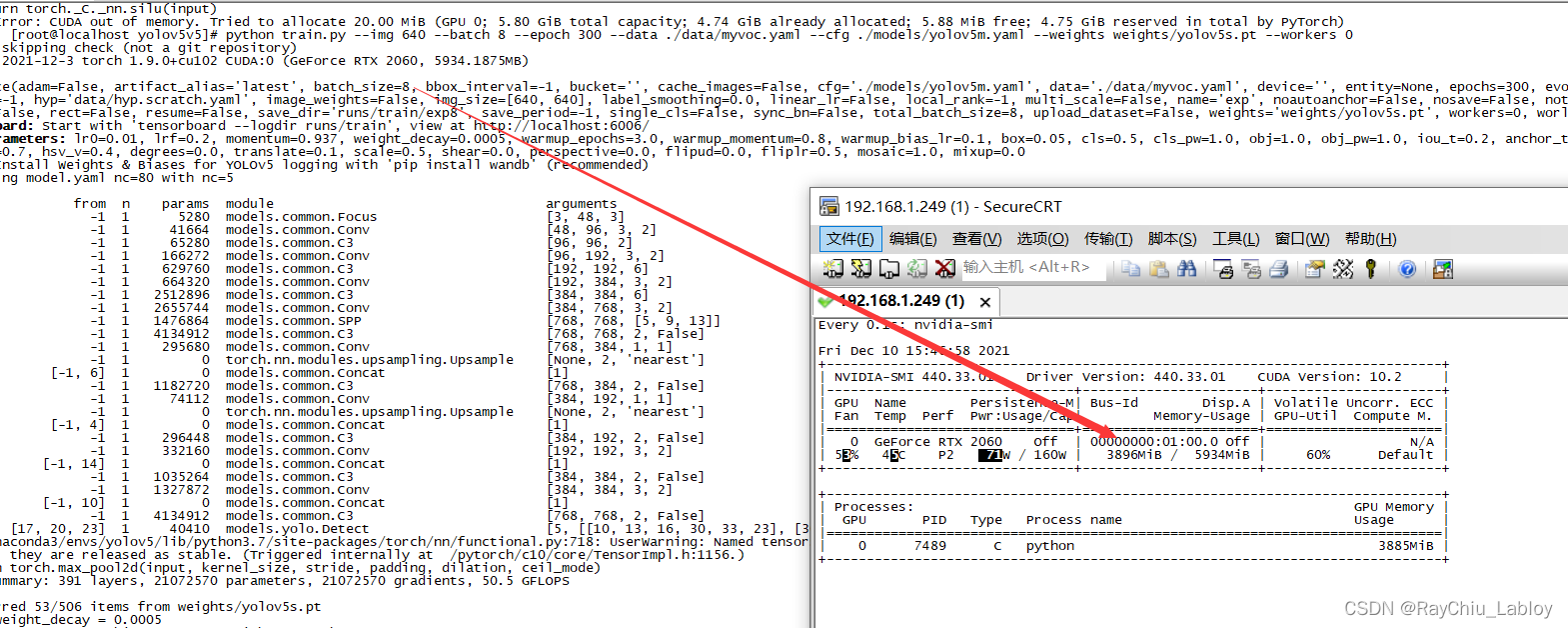
最终确定我的显卡最大batch-size是8
如何确定训练时batch-size大小?
我们平时做深度学习训练模型的时候有时候不确定batch size该定多大?有没有公式可以计算呢?至少我目前没听说过有啥公式。其实大家都差不多一个操作,就是调参的过程,在显卡能力范围内选一个适中的值,过大过小都不一定好,引用大家总结的经验,其实和自己训练时的感觉差不多:
增大batch-size好处:
1)内存的利用率提高了,大矩阵乘法的并行化效率提高。
2)跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快。
3)一定范围内,batchsize越大,其确定的下降方向就越准,引起训练震荡越小,前期收敛很快
过大batch-size缺点
1)迭代次数减少导致想要达到相同的精度,时间开销太大,参数的修正更加缓慢(我的理解是前后期收敛会慢下来,同样的迭代次数其实达不到小batch-size的精度)。
2)batchsize增大到一定的程度,其确定的下降方向已经基本不再变化。
总结
1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5)由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
6)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
7)具体的batch size的选取和训练集的样本数目相关。
因此,batch的size设置的不能太大也不能太小,因此实际工程中最常用的就是mini-batch,一般size设置为几十或者几百。
但是对于二阶优化算法,减小batch换来的收敛速度提升远不如引入大量噪声导致的性能下降,因此在使用二阶优化算法时,往往要采用大batch。此时往往batch设置成几千甚至一两万才能发挥出最佳性能。
另外GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优


















 2710
2710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









