







 ReLU(修正线性单元)是深度学习中常用的激活函数,因其计算简单、能缓解梯度消失而受到青睐。然而,ReLU存在神经元死亡问题,对此有LeakyReLU和ELU等变种作为解决方案。LeakyReLU允许负输入有一定信息通过,而ELU则结合了sigmoid的平滑和ReLU的非饱和性,改善了训练效果。
ReLU(修正线性单元)是深度学习中常用的激活函数,因其计算简单、能缓解梯度消失而受到青睐。然而,ReLU存在神经元死亡问题,对此有LeakyReLU和ELU等变种作为解决方案。LeakyReLU允许负输入有一定信息通过,而ELU则结合了sigmoid的平滑和ReLU的非饱和性,改善了训练效果。
线性整流函数ReLU
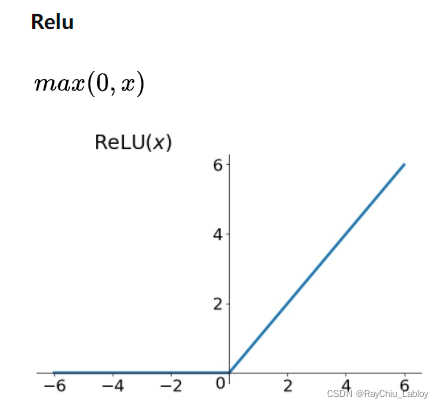
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元, 是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
数学表达式:
f(x) = max(0, x)
或者写出这样:
![]()
以上式子中的x是神经网络线性变换后的输出值,ReLU将线性变换的结果转为了非线性值,这种思路参考了生物学中的神经网络机制,这种机制特点是当输入为负时,全部置零,而输入为正时则保持不变,这个特性称为单侧抑制。在隐藏层中,这个特征会为隐藏层的输出带来一定的稀疏性。同时由于它在输入为正时,输出保持不变,梯度为1:
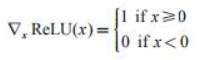
- 优点一:计算简单效率极高。相比于其他激活函数如sigmoid、tanh,导数更加好求,反向传播就是不断的更新参数的过程,因为其导数不复杂形式简单。
- 优点二:抑制梯度消失。对于深层网络,其他激活函数如sigmoid、tanh函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失。),这种现象称为饱和,从而无法完成深层网络的训练。
而ReLU就不会有饱和倾向(这里只针对右端,左端导数为零,一旦掉进去依然会梯度消失),不会有特别小的梯度出现。详细请参照:为什么sigmoid会造成梯度消失?_outsider-CSDN博客_sigmoid 梯度消失
-
优点三:缓解过拟合。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
缺点也是相对存在的,ReLU这种单侧抑制机制过于粗暴简单,在某些情况下可能会导致某个神经元“死亡”,也就是上面优点二强调的抑制梯度消失是右端体现出来的,左端导数为0,那么在进行反向传播时,其相应的梯度始终为0,导致无法进行有效的更新。为了避免这种情况,有几种ReLU的变种也被广泛使用。
Leaky ReLU
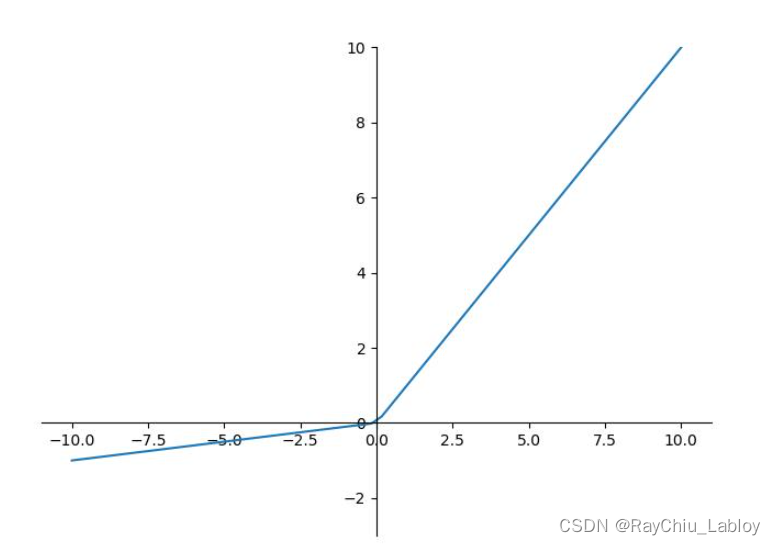
LeakyReLU不同于ReLU在输入为负时完全进行抑制,它在输入为负时,可以允许一定量的信息通过,具体的做法是在输入为负时,输出为![]() ,数学表达式为:
,数学表达式为:
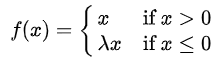
其中![]() 是一个大于零的超参数,通常取值为0.2、0.01。这样就可以避免ReLU出现神经元“死亡”现象。LeakyReLU的梯度如式:
是一个大于零的超参数,通常取值为0.2、0.01。这样就可以避免ReLU出现神经元“死亡”现象。LeakyReLU的梯度如式:
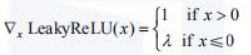
集大成者ELU
理想的激活函数应满足两个条件:
- 输出的分布是零均值的,可以加快训练速度(参考深度学习图像预处理中为什么使用零均值化(zero-mean)_会意的博客-CSDN博客_什么是零均值)。
- 激活函数是单侧饱和的,可以更好的收敛。
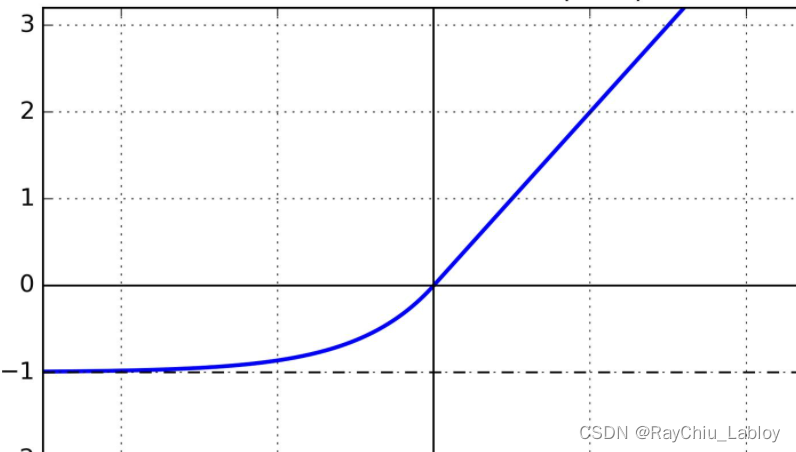
LeakyReLU相对接近于满足第1个条件,不满足第2个条件;而ReLU满足第2个条件,不满足第1个条件。两个条件都满足的激活函数为ELU(Exponential Linear Unit),数学表达式为:

输入大于0部分的梯度为1,输入小于0的部分无限趋近于-α。
ELU融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性,但是左侧这种非线性优化也带来了损失计算速度的缺点。
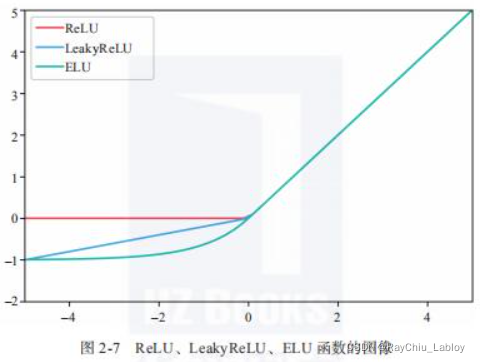
理论上来说选择激活函数的顺序是 ELU>LeakyReLU>ReLU>tanh>sigmoid


















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









