







from:http://cs.stanford.edu/people/karpathy/deepimagesent/
Deep Visual-Semantic Alignments for Generating Image Descriptions
Abstract
We present a model that generates natural language descriptions of images and their regions. Our approach leverages datasets of images and their sentence descriptions to learn about the inter-modal correspondences between language and visual data. Our alignment model is based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. We then describe a Multimodal Recurrent Neural Network architecture that uses the inferred alignments to learn to generate novel descriptions of image regions. We demonstrate that our alignment model produces state of the art results in retrieval experiments on Flickr8K, Flickr30K and MSCOCO datasets. We then show that the generated descriptions significantly outperform retrieval baselines on both full images and on a new dataset of region-level annotations.
CVPR 2015 Paper
Deep Visual-Semantic Alignments for Generating Image DescriptionsAndrej Karpathy, Li Fei-Fei
Code
See our code release on Github, which allows you to train Multimodal Recurrent Neural Networks that describe images with sentences. You may also want to download the dataset JSON and VGG CNN features for Flickr8K (50MB), Flickr30K (200MB), or COCO(750MB). You can also download the JSON blobs for all three datasets (but without the VGG CNN features) here (35MB). See our Github repo for more instructions.Update: NeuralTalk has now been deprecated, in favor of the more recent release of NeuralTalk2.
Retrieval Demo
Our full retrival results for a test set of 1,000 COCO images can be found in this interactive retrieval web demo.Region Annotations
Our COCO region annotations test set can be found here as json. These consist of 9000 noun phrases collected on 200 images from COCO. Every image has a total of 45 region annotations from 9 distinct AMT workers.Multimodal Recurrent Neural Network
Our Multimodal Recurrent Neural Architecture generates sentence descriptions from images. Below are a few examples of generated sentences:
"man in black shirt is playing guitar."

"construction worker in orange safety vest is working on road."

"two young girls are playing with lego toy."

"boy is doing backflip on wakeboard."

"girl in pink dress is jumping in air."

"black and white dog jumps over bar."

"young girl in pink shirt is swinging on swing."

"man in blue wetsuit is surfing on wave."

"little girl is eating piece of cake."

"baseball player is throwing ball in game."

"woman is holding bunch of bananas."

"black cat is sitting on top of suitcase."
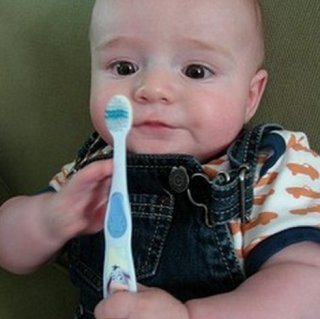
"a young boy is holding a baseball bat."

"a cat is sitting on a couch with a remote control."

"a woman holding a teddy bear in front of a mirror."

"a horse is standing in the middle of a road."
See web demo with many more captioning results here
Visual-Semantic Alignments
Our alignment model learns to associate images and snippets of text. Below are a few examples of inferred alignments. For each image, the model retrieves the most compatible sentence and grounds its pieces in the image. We show the grounding as a line to the center of the corresponding bounding box. Each box has a single but arbitrary color.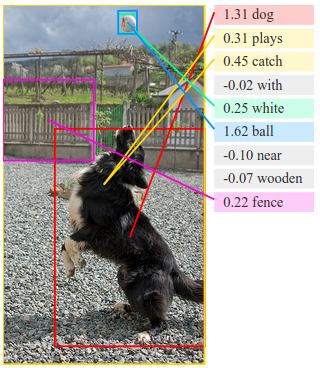
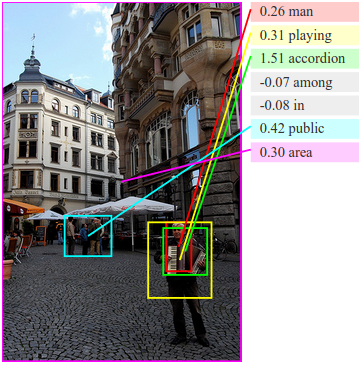

See many more examples here.















 2587
2587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









