







行人检测 读书笔记 综述(1)
朱文佳-基于机器学习的行人检测关键技术研究
本文是博主对上海交通大学的朱文佳的硕士毕业论文的学习笔记,如果不当或理解错误之处,敬请指导,不胜感激。
绪论
1.1 典型应用
- 智能监控,可用于社会安全事件预防与分析等
- 智能车辆,智能车辆的辅助驾驶
- 人机接口,提高人机交互的效果
1.2 研究现状(2008)
整体趋势:
1.训练集越来越大
2.检测速度从10秒每帧到一秒多帧
3.精度从50%提升至90%
1.3 研究难点
- 人的差异性,服饰的差异性
- 动作的多样性
- 背景的复杂性
- 建筑物等对行人的遮挡,人对人的遮挡
- 视角的变化
- 光照的变化
- 尺度不同,同一图片,同样大小的人,尺度不同
1.4 文章组织
- 绪论,背景
- 综述基于机器学习的行人检测的主要研究方向,及代表性算法,分析各自特点
- 介绍分析boosted cascade
- 将booseted cascade 与hog特征结合起来
综述
2.1 引言
算法分类
1. 基于整体特征的算法:将人看成一个整体,用矩形框表示行人,首先对其进行特征提取如小波特征、hog特征等,然后用分类器,如svm等进行分类,其优点是框架简单,易于实现,单在处理遮挡等问题时不够灵活。可用解决1.3中1,3,6
2. 基于多部位的方法:将人分为多个部位,然后根据相互约束关系来得到最终结果。问题在于如何定义部位及整合检测信息。可用于解决1.3中2,4
3. 基于多视角的方法。将不同视角的的行人,分开训练,减小类内变化,简化训练难度。问题在于如何自动区别不同视角,如何利用不同视角的相似性减小计算量。可用于解决1.3中的5
2.2 基于整体特征的方法
2.2.1 小波特征
提出:Oren 1997年,小波提取特征,用svm分类
负样本的定义:bootstrap。首先随机选取真的负样本,然后将训练之后分类错误的负样本,加入训练。
2.2.2 边缘模板
提出: Gavrila 1999年
首先作者标注了1000个人的边缘模板,首先利用聚类,得到一个模板树。
然后,搜索图中的轮廓,如果匹配度达到一个阈值,就判断为人,使用的方法为chamfer距离。
其运行速度为每秒1-5帧,但是该算法依赖于边缘的提取,如果边缘不是那么明显,可能会出现漏检
2.2.3 hog 特征
提出:Dalal 2005年
hog=histogram of gradient 梯度分布直方图

计算过程:
将输入图片分为若干块,每块在分为若干格子,对每个格子统计其中所有像素的梯度值在各个方向的分布,得到特征向量,再把一个块内所有格子的特征向量串联起来,得到该块的特征向量,然后进一步把所有块的特征向量串联起来,作为一个样本特征向量。
能够很好地刻画边缘特征,适用于图像匹配和物体检测
2.2.4 edgelet 特征
提出 Bo wu
利用小边来描述人体某个部位的整体,Bo wu 定义了80多万个上图中的edgelet,经过boosting,筛选出上千个最利于识别人体的edgelet。如果图上的边缘与最后的edgelet越相似,得到的相应越高(利用一个函数),分类结果越像人。
其特点有:
1. 不需要像边缘模板一样二值化,只用sobel算子,计算边缘,受关照等影响较小
2. 同时考虑了边缘的强度和方向(判断相似的函数中有体现)
3. 每个edgelet仅负责一小块区域,计算量小,更灵活
4. edgelet由一定的规则自动生成(比如1/4圆弧),然后由机器学习算法自动筛选,减少了人工干预
在Mit数据集上,该算法的效果远远超过了小波算法。
2.2.5 shapelet 特征
提出:sabzmeydani 2007年
与edgelet不同的是,shapelet利用图中的曲线来生成一段段的人体边缘
流程为:
1.提取底层特征

2.用boosting生成shapelet
作者在底层特征上定义了0度、45度、90度、135度四个方向的边缘,然后进行筛选,下图可以看出edgelet与shapelet的区别、
其中第二排是shapelet
3.训练好的shapelet在使用boosting,训练出最强分类器
该算法效果显著,超越了以往所有的算法
2.3基于多部位的方法
2.3.1 自适应组合分类器
提出:Mohan 2001年
方法:
1. 将人体分为 头肩 下半身 左肩 右肩4个部分,每部分与2.2.1中的小波算法基本一致
2. 将4个部分的输出作为输入,将部位检测效果整合起来,输出分类结果
注意,考虑到人体的非刚性,四个部位分类器必须在一定的范围和尺度内进行搜索
2.3.2 基于贝叶斯推断的组合算法
提出:Bo Wu
方法:
1. 将人体分为头肩、躯干、腿三个部分,分别训练分类器
2. 与mohan不同的是,其整合方法是使用贝叶斯概率的方法来分析哪里有行人
Bo Wu 的实验表明,基于多部位的方法只有在出现遮挡时才会有优势
2.3.3 隐式形状模型
提出:Leibe
以上两种方法需要对人体部位进行手工设定,leibe的implicit shape model 把人体看成许许多多的图片块构成。
1. 建立图片块字典
2. 利用difference of gaussian 提取兴趣点
3. 计算图片块与兴趣点的位置等关系
4. 检测兴趣点,搜素相应的图片块,进行投票,当票数超过一定值,便认为是人
2.4 CBT 多视角
特点:检测速度快,不需要人为划分视角
方法:
用树的方法,先选择一部分特征,依据样本对特征的相应,进行聚类,然后重复整个过程
如图
1. 第一级选出3个特征,根据这这3个特征进行聚类
2. 分成两个子集 继续训练
(其特征提取方法本文并未提及)
3 基于boosted cascade的物体检测
提出:viola
简单来说boosted cascade就是先利用adaboost之类的boost方法将弱分类器,变为强分类器,用不同的特征来合成不同的强分类器,然后用这些强分类器来排除不是行人的大量负样本,逐步分类,如下图:
图中第1层的分类器,是由一定量的特征做成的强分类器,(至于组成强分类的弱分类器类型这里没有提到,在后面作者有提及)其分类效果略差,目的器排除大量的负样本,以节省时间。
至于什么是adaboost,看下链接:
http://blog.csdn.net/bea_tree/article/details/50460634#t10
另外还有对于物体检测很重要的就是特征的选取,这里作者介绍的是viola提出的积分图片与矩形特征,它表征了灰度的变化。
如图:

计算方法为将图片分为若干像素块后,用图中黑色区域的像素灰度平均值减去白色区域内的像素灰度平均值。
为了方便计算上面提到的差值,viola,提出了积分图,就是遍历一遍像素,然后将位于遍历点左前方的所有像素的值之和计算赋值,如图:
如果计算d区,那么其值便为:4所在的和值-2所在的和值-3所在的和值+1所在的和值.
4 作者对boosted cascade的改进
作者主要在特征选取,adaboost及弱分分类器三方面进行了改进
1. 特征的选取上作者结合了haar 与 shog。其中shog 是hog的简化(simple)版,其思想为,因为在弱分类器中使用,将hog图片分割的步骤去掉,直接在整个图片进行梯度分布。据作者介绍其结果比单独的haar好,且与haar+hog效果相似。
2. 在adaboost改进方面,不再单独输出分类结果,而是输出了正样本的可信度。据作者介绍,这样的改动可以减少特征使用数量,减少训练时间。
3. 在弱分类器方面,作者采用将shog特征转化为一维特征,然后采用查表的方法,作者并未在论文中具体实现,但据记效果较好。
总结
全文前半部分适合入门阅读,了解综述。
行人检测 读书笔记 综述(2)2007
贾慧星 张毓晋- 车辆辅助驾驶系统中基于计算机视觉的行人检测研究综述 2007-自动化学报
本文主要介绍了感兴趣区分隔和目标识别两模块的常用分析方法。
1 ROIs分隔
ROIs=regions of interest
其分隔方法主要有基于运动、距离、图像特征、摄像机参数等,在应用中可以相互结合。
如下图:
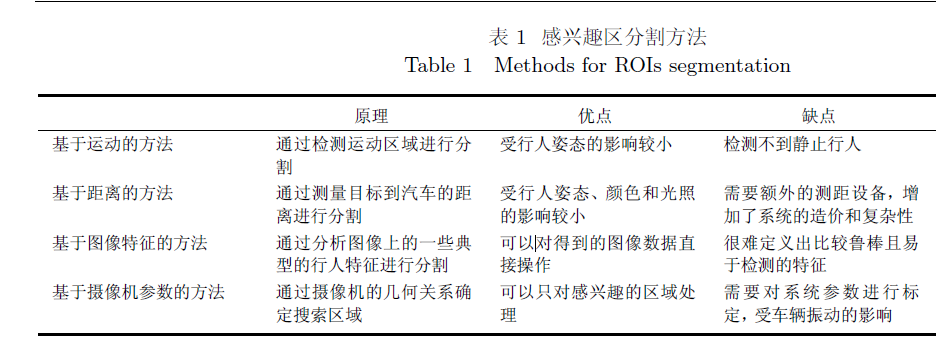
注:1、基于距离的方法有根据雷达或者立体视觉等方法
2、基于图像特征中的特征主要有:边缘、熵、红外图中的热图
2 目标识别
主要有基于运动的识别和形状的识别方法两种,应用中可以相互结合。
作者将其总结如下表:

其中基于形状所计入的方法与上一遍硕士论文中的记载相似
3 典型系统的性能
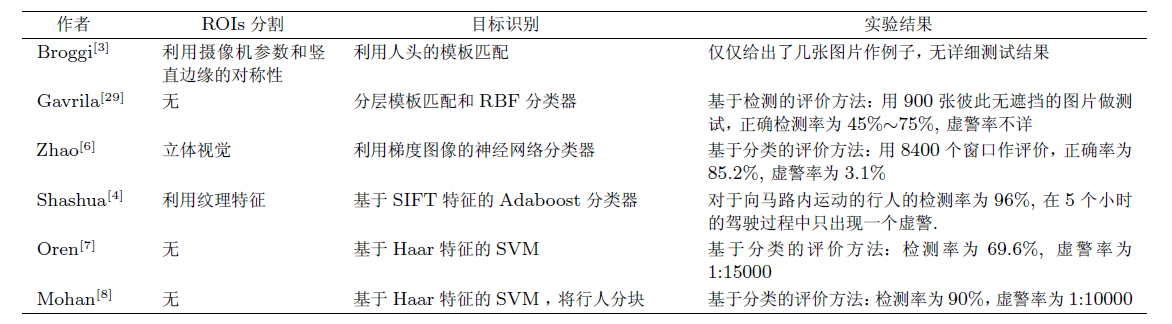
总结
原文还有设计评价指标等,未在本文阐述。
其中,目标识别中,分为基于运动和基于形状的方法。如果能对其识别的特征进行综合阐述将更好。
行人检测 读书笔记 综述(3)2007
杜友田等 基于视觉的人的运动识别综述 2007 电子学报
看过前两篇文章之后前面的引言可以省略了
1 人运动的类别
Bobick 人的运动分类
- 动作 movement 例如动一动手指
- 行为 activity 例如完成的手势
- 行为 action 例如多人交互
2 人运动的表示方法
首先,作者阐述了衡量运动表示的标准:紧凑性(minimalism)、完备性(completeness)、连续性(continuity)、唯一性(uniqueness)
其次,关于人运动吧表示方法:
- 基于表观(appearance)的表示方法:采用图像上的颜色、灰度等信息直接分析
1)网格特征(mesh feature),先将图像划分为若干网格,将人从图像中提取,看每个网格中人体的像素的比例,以此描述人体运动,研究者Yamato,T.Nishimura。方法简单,精度低。
2)利用人的轮廓或者区域信息。kale的步态识别问题:提取轮廓->计算每一行的轮廓宽度作为特征向量。Veeraraghavan利用轮廓上的标记点来分析人的运动。
3)利用人的运动信息,如光流,目标轨迹以及速度等。Pasarrou等人采用时空轨迹(spatio-tempral trajectory)来表达人的行为,用一阶马尔科夫过程对其建模。
- 基于人体模型的表示方法
基于人体模型的表示方法=将人体及其姿态参数化,主要有三种:线图模型,2-D模型和立体模型,前两者使用较多(2007年之前)。这类方法,特征空间维度高,对图像分辨率要求较高。栗子:feng和Perona采用2-d模型建模,将人体模型分为10个矩形,每个矩形有5个自由度,采用当前帧和下一帧中的模型参数联合表示人体姿态;Arie等人采用3D模型,将人体分为9个圆柱和球体,其特征向量由其角度和角速度表示,姿态由上肢、下肢、躯干最终确定,具体计算时投影到2d平面。
3 人运动的识别方法
3.1 基于模板的方法
将运动图像转化为一个或一组静态的模板,将待识别样本与一直模板进行匹配:Bobick和Davis将图像序列转化为运动能量图像(MEI)和运动历史图像(MHI),前者反应运动范围和强度,后者反应时间变化,通过计算马氏距离(mahalanobis distance)来衡量其余模板的相似性。
另外,由于同一模式的运动持续时间不同,所以在模板匹配时需要对其进行规整,动态时间规整dynamic time warping 是一种很好的非线性规整方法。
3.2 基于概率网格的方法
基于概率网格的方法是当前(2007)最主要的人的运动识别的方法。
主要种类:
- 隐马尔科夫模型 Hidden markov Models, HMMs
- 动态贝叶斯网络 Dynamic Bayesian Networks,DBNs
前者是后者的特殊形式
后来又出现了条件随机场(Conditional random field)及隐马尔科夫的变体:
Brand等人 coupled hidden markov model 耦合隐马尔科夫模型
luhr nguye 分层隐马尔科夫模型 hierarchical hidden markov models
Duong 将时间融入 提出switching hidden-semi markov model(S-HSMM)
动态贝叶斯网络对于动态过程的建模和分析、多信息融合、复杂动态系统的分析识别更为有效和灵活,相比隐马尔科夫可分析动态复杂系统,降低复杂度
3.3 基于文法技术(syntactic technique)的方法
文法技术多用于文本分析和语音识别等领域,在运动识别中主要用于静态图片的纹理识别
主要优势在于对复杂结构的理解和先验信息的利用
4 存在问题
*更本质的表达方式:
1. 三维重建,复杂度高,假设多
2. 动态瞬间和间隔,表达行为的速度,方向,及加速度
3. 特征向量维数的高低,可采用多分辨率方法,有高有低
*连续运动的实时识别
1. 如何判断运动的起点和终点
2. 如何学习长运动序列中的心行为:半监督
*算法评价
缺少标准的测试数据集
*如何根据外部环境自主学习
行人检测 读书笔记 综述(4)2008
许言午等-行人检测系统研究新进展及关键技术展望-电子学报
本文中的行人检测系统简写为pds,即pedestrian detection system
1 早期工作回顾
1.1 技术方面的早期进展
早期PDS大多都直接借鉴与静态摄像头的静态视觉监控技术,包括图像处理的图像分割、边缘提取、光流、运动检测等技术 及模式识别中的一些简单分类方法。
以图像处理技术为基础的代表性工作有:
1. Gavrila 基于模板匹配
2. Lipton 运动区域的残余光流
3. Heisele 利用行人退步的运动特征
算法方面有径向基函数及神经网络等算法
总结:1、借助传感器 2、直接套用一般物体检测算法以及静态摄像头监控技术
2 2003-2008工作进展
2.1 技术进展
2.1.1 特征提取
2.1.1.1 特征表示
pds主要使用的特征包括1物理特征和2抽象特征,前者包括1.1外观特征如行人的形状、轮廓、纹理等静态特征,还有1.2动态特征,主要描述行人运动时的变化和规律。抽象特征典型的代表有haar特征。
早期的工作一般只是用一种外观特征或一种运动特征,其中外观特征主要有原始灰度和轮廓,也有少量使用了颜色,一般只使用一种特征的pds都难以获得较好的检测性能
近年来新特征:
a. 新的外观特征
1. Amnon等提出了基于人体的9个关键部位及其相对位置关系构成的13个关键特征
2. Havasi 提出了基于人腿的三次对称特征
b. 新的运动特征:Ran等提出了人腿形态周期特征
c.新的抽象特征:Lowe等提出了SIFT特征,具有尺度不变的良好特性,这一特征也被Amnon引入到PDS中用于形状特征的表示
d.多特征综合的表示方法,Viola2003提出结合运用外观与运动特征的特征联合表示方法,采用串联的组合分类装置
e.使用头、腿等局部特征来作为全局特征的补充
2.1.1.2 特征的选择方法
Viola 引入Adaboost
基于协同进化
2.1.1.3 特征降维方法
Munder Gavrila PCA
2.1.2 分类机制
2.1.2.1 单个支持向量机
理论基础好,其他领域得到较好效果,但是分类速度慢,无法满足使用需求
2.1.2.2 基于组合的分类机制
a.简单串联,分级
b.简单并联,投票
c.串并联结合及树状分类
2.1.3 传感器融合
早期:光学摄像头,红外摄像头
近年:专用雷达,多传感器融合
各种传感器,各有优缺点;
1. 光学与雷达传感器融合
2. 普通光学摄像头和红外摄像头融合
3. 多类传感器分层融合
2.1.4 其他技术
- 立体视觉:Brotti基于双红外立体视觉的pds ;Huang体育双光学摄像头,使用二次分隔技术的pds
- 跟踪技术,利用跟踪技术来加快行人的检测,解决间断性遮挡等问题
- 无线通信技术 将gps与pds得到的信息融合,进一步增强汽车队周围环境的感知能力
2.2 存在问题
- 均衡各方面指标:如高检测率,低误报率,高检测速度
- 特殊场景:关照突然变化,逆光,雨雪天气,抖动等
- 新的传感器加入如何同步融合
- 提高实时自学能力
行人检测 读书笔记 综述(5)2012
苏志松等-行人检测技术综述-电子学报 2012
文章对2005到2011这段时间内行人检测技术中最核心的两个问题:特征提取,分类器与定位的研究现状进行综述
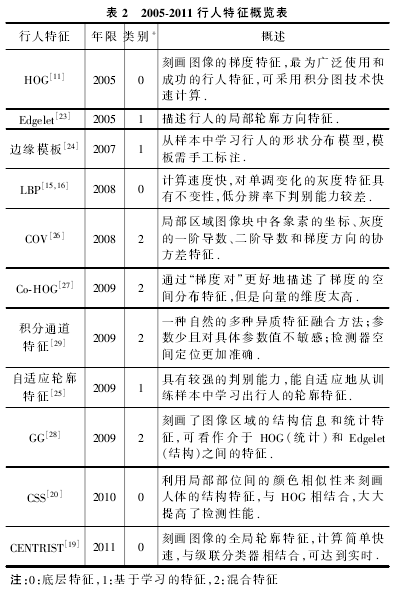
1 特征提取
作者将特征分为以下三类
底层特征:颜色、纹理、梯度等
基于学习的特征:通过机器学习的方法从大量的行人样本中学到的特征
混合特征:多种底层特征的融合,或者底层特征的高阶统计表示
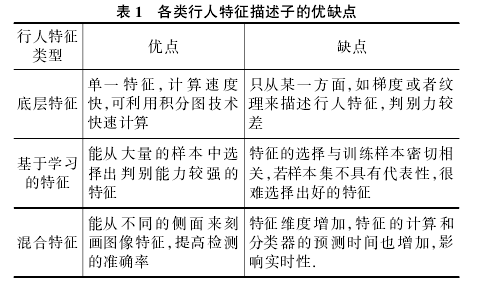
作者总结了2005-2011的行人特征概览表
如下图:
其中
LBP=local binary pattern 局部二值模式
最早由Ojala等提出用于纹理分类的特征提取方法
Cov:Tuzel利用特征的协方差来表示行人的局部特征
Go-Hog: Watanabe 共生梯度方向直方图特征 co-occurrence Histograms ofOriented Gradients
GGP(疑似表中GG应为GGP)=Granularity-tunable Gradients Partition 用来定义霍夫空间中线段的空间位置和角度的不确定性
积分通道:提出者Dollar
自适应轮廓特征:Gao 利用adaboost算法在方向粒度空间中进行特征选择,定义了’生长‘,’合并‘,’切割‘三种操作
CSS:提出者Walk
CENTRIST:census transform histogram
2 分类与定位
分类:判断当前检测窗口是否有行人
定位:行人在窗口的具体位置
方法:滑动窗口法,超越滑动窗口法
a. 滑动窗口法
a.1 整体法
主要分类器:svm,boosting,多示例学习
分述之:
svm:oren最早,maji基于直方图交叉核支持向量机 Histogram Intersection Kernel ssvm
boost:最早viola:haar+adaboost+级联分类器=第一个实时人脸检测,chen改进级联结构,每级中引入meta stage,每级输出构建分类器,Tuzel利用logitboost,Kim提出多分类增强算法MCBoost(multiple classifier boost)对图像和视觉特征进行协同聚类
多示例学习:lin等和babenko等提出,自动对齐行人的局部特征,对形变进行建模
a.2 部位法
Felzenszwalb提出形变部位模型(deformable part model)
Pedersoli等由粗到细的快速形变部位模型,现在低分辨率下检测,保留下来的再在高分辨率下检测
部位检测法中parikh的研究表明,部位法中部位检测器对检测性能的影响大于部位之间的几何关系对检测性能的影响
b 超越滑动窗口法
基于bag-of-wards,BOW词袋的发展,一般包含三个步骤:视觉词典构建-基于词典的图片表示-分类器学习
分为以下三种
b.1 高效子窗口搜索法efficient subwindow search ESS
b.2 隐式形状模型,通过局部特征检测算子寻找关键点(中心点),在关键点周围用聚类等方式建立空间分布模式,最后投票
b.3 跳跃窗口法,与隐式形状模型类似,不同是不是对行人中心点进行投票
经验细节
训练样本:
- 样本场景应多样,提高泛化能力
-
最好能收集固定场景下的正样本和负样本
预处理
-
在实用性要求高的场景中,可预先利用先验信息预先确定行人可能出现的区域
- 视频监控系统中,背景信息相对固定,可采用减背景法获取运动目标区域,将其作为候选区域
-
车辆辅助驾驶中,可使仅扫描路面信息
后处理
-
对检测结果进行筛选,降低误检率
行人检测 综述 (6)
由于课程作业,总结下近期国内关于行人检测的文献,虽然是2013 2014年写的,但是综述的内容还都是经典的东西。作为浏览回顾就行。
许腾,黄铁军,田永鸿 . 车载视觉系统中的行人检测技术综述[J]. 中国图象图形学报,2013,18( 4) : 359 -367.
本文对 2005 年以来该技术中最重要的两个环节———感兴趣区域分割以及目标识别的研究现状进行综述。
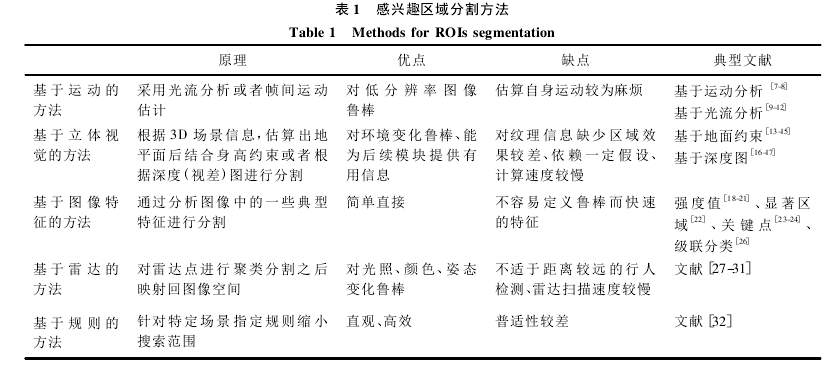
1 ROIs ( regions of interest) 分隔
ROIs的分隔方法主要有这五类:1. 基于运动 2. 基于立体视觉 3. 基于图像特征 4. 基于雷达 5基于规则,如下表
2 目标识别
主要总结了2005-2012年间目标识别方法

2.1 特征提取
2.1.1 对原有特征的改进
原文中对原有特征的改进主要讲了对hog的改进,hog看下文
http://blog.csdn.net/liulina603/article/details/8291093
有人将其中的块大小可变,有人使用积分图 (http://blog.csdn.net/bea_tree/article/details/51106359#t19),有人取消了cell,有人构造图像金字塔,还有人利用gpu进行加速计算。
2.1.2 新特征
主要集中在利用局部梯度、轮廓、纹理信息以及多种底层特征组合方面。
例如共生梯度方向直方图特征( CoHOG)、二阶梯度方向直方图、Edgelet 、自适应的轮廓特征( ACF) 、积分通道特征( integral channel features) 、 CSS( 颜色通道自相似) 、中心对称的金字塔 LBP
2.1.3 非可视光谱数据上的使用
主要就是对原有特征转变为在红外线、立体视觉或者其他非可视光谱
2.2 分类器构造
主要是对svm和boosting的改造
Maji 等人提出了直方图交叉核( HIK)的一种近似算法,Felzenszwalb 等人利用形变部件模型( DPM) 方法检测人体、汽车等对象。
Kim 等人提出使用多分类器 Boosting 算法。lin等人基于多实例学习( MIL) 的 Boosting 框架。Babenko 利用多姿态学习( MPL) 的方式对训练样本自动按照姿态进行分类。
2.3 搜索框架
滑动窗口在目前的搜索框架中十分流行采用非极大抑制( NMS) 或MeanShift 的方法进行合并,从而得到检测结果。研究者借鉴了在对象分类中十分流行的“词袋”( BOW) 模型,在图像中进行全局最优搜索。目前此类算法主要有隐式形状模型( ISM) 和高效子窗口搜索法( ESS) 。
3作者展望
- 立体视觉
- 多传感器
- 新数据集
- 自动结合上下文
张春凤,宋加涛,王万良 . 行人检测技术研究综述[J]. 电视技术,2014,38( 3) .
这篇文章主要介绍了各种行人检测的方法,总体将其分为基于全局特征、基于局部特征和基于立体视觉的方法。另外文章总结了目前的几种数据库
1 行人检测方法
1.1 基于全局特征
首先附上关于HOG haar 和lbp三种特征比较好的文章 http://www.open-open.com/lib/view/open1440832074794.html
1.1.1 haar
Papageorgiou 和 Poggio最早提出 Harr 小波的概念;Viola 等引进了积分图的概念,加快了 Harr 特征的提取速度,并将该方法应用于行人检测,结合人体的运动和外观模式构建行人检测系统,取得了较好的检测效果,为行人检测技术的发展奠定了基础。
1.1.2 hog
Dalal 和 Triggs在 2005 年提出梯度方向直方图( Histogram of Oriented Gradients,HOG) 的概念,并将其用于行人检测, 在包含视角、光照和背景等变化的 INRIA 行人数据库上,也取得了大约 90%的检测成功率。HOG
是目前使用最为广泛的行人特征描述子。Zhu 等人提出积分直方图的概念,加速了 HOG 特征的计算,Qu 等人提出无背景情况下的 HOG 特征的概念,既消除了通常情况下背景因素对目标 HOG 特征的影响,又加速了 HOG 特征提取的速度; Wang 等人将 HOG特征与局部二值模式( Local Binary Pattern,LBP) 相结合,用于存在部分遮挡情况下的行人检测,使用线性支持向量机( Linear Support Vector Machine,SVM) 作为分类器,在INRIA 行人库上取得了 97% 的检测率,但是它的高运算复杂度也限制了实时应用。
1.1.3 edgelet
B. Wu 等人提出了“小边”( Edgelet) 特征的概念,即一些短的直线或者曲线片段,并将其应用于复杂场景的单幅图像的行人检测,在CAVIAR 数据库上取得了大约92%的检测率。缺点是由于每个 Edgelet 特征需要手动标定,所以比较耗时费力,而且对于一些本身较复杂的曲线,很难通过手工标定的方法来得到完全符合人体曲线的“小边”特征。
1.1.4 Shapelet
针对上述 Edgelet 特征存在的缺点,Sabzmeydani在2007 年提出了一种可以利用机器学习的方法自动得到的特征,即 Shapelet 特征。该算法首先从训练样本提取图片不同方向的梯度信息,然后利用 AdaBoost 算法进行训练,从而得到 Shapelet 特征。Yao 等利用 Shapelet特征训练得到一个全身检测器,该算法优于基于 Haar -like 特征的部分检测器; 他们进一步将上述两种检测器相结合构成一个行人检测系统,在 INRIA 数据集上取得了95% 的行人检率,检测效果优于单独使用其中任何一个检测器的情况。
1.1.5 基于轮廓模板的方法
在这个系列第一篇文章中就提到了这种方法,其需要大量的模板,标记较为繁琐。
1.1.6 基于运动特征的方法
其中较具代表性的算法包括:
1) Viola 等人针对摄像机静止的情况提出在不同图像上计算 Haar - like 特征,然后将运动信息与图像的灰度信息相结合构建行人检测系统。且适用于雨雪天气等恶劣气候条件下低分辨率场景的行人检测,但对于行人被遮挡的情况检测效果较差;
2) Dalal等针对摄像机运动的情况,提出将基于外观的梯度描述子和基于运动的差分光流描述子相结合来构建行人检测器,但该方法只对单个窗口的检测比较有效,对于整幅图像检测效果则很差。
1.2 基于局部特征
该类方法的基本思想是把人体分成几个组成部分,然后对图像中每部分分别检测,最后将检测结果按照一定的约束关系进行整合,最终判断是否存在行人。目前已有一些较有效的算法: Mohan 等将人体分为头肩部、腿部以及左手臂和右手臂4 个部分,然后使用 Harr 小波特征训练 SVM 检测器。Mikolajczyk 等将人体分成正面的人脸/头部、侧面的人脸/头部、正面和背面的头肩
部、侧面的头肩部以及腿部,然后对每个部分采用 SIFT( Scale - Invariant Feature Transform) 特征进行描述,Vinay D. Shet等提出了一种基于双网格逻辑推理的行人检测方法,将人体分为头、上身和腿部三个部分,在 USC 数据库上获得了92%左右的检测成功率,对存在不同程度遮挡的行人检测率也达到了 90% 以上。该类方法的优点是:1) 降低了人体某一部分被遮挡时对行人检测结果的影响;2) 对人体各部分分而治之的思想,降低了整体检测的难度而且各个部分之间的几何约束关系也对最终检测的精度有很大的帮助。
1.3 基于立体视觉的方法
该类方法是指通过 2 个或 2 个以上的摄像机进行图像采集,然后分析图像中目标的三维信息以识别出行人。可以利用三维信息估计路面参数用来筛选出感兴趣区域( ROI) ,并利于这些信息对所获得区域进行分类,构建了一个检测率较高的行人检测系统。也可以对左右视角的多个图像进行 ROI 提取,并其用于模式分类,降低了目标检测的误报率。也可以利用车载立体摄像机,将图像亮度信息和三维密集立体信息相结合,构建了一个直立行人检测系统。该类方法的优点是充分利用场景中目标图像的深度信息进行行人区域的分割,速度较快。
2 数据库总结
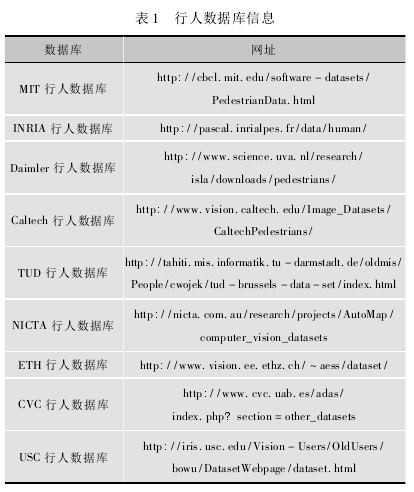
1) MIT 行人数据库是较早公开的行人数据库,太简单。
2) INRIA 行人数据库是目前使用较多的静态行人数据库更加符合实际场景。
3) Daimer 行人数据库的图像来源于车载摄像机,图片均是灰度图像。测试集是一段大约27 min的视频,其中包含完整的以及被部分遮挡的行人。
4) Caltech 行人数据库是目前规模较大的行人数据库,库中的图像来源于车载摄像机,与现实生活中图像的实际遮挡频率一致,其中包含质量不太好的图像。
5) TUD 行人数据库提供图像对以便计算光流信息,该数据库主要用于评估运动信息在行人检测中的作用,常用于行人检测及跟踪研究中。
6) NICTA 行人数据库是目前规模较大的静态图像行人数据库,包含25 551 张单人的图像和5 207 张高分辨率非行人图像,但不包含运动信息,已经划分训练集和测试集。
7) ETH 行人数据库是基于双目视觉的行人数据库,采用一对车载摄像头拍摄获得,给出了标定信息和行人标注信息,同时采用置信度传播方法获取深度信息。
8) CVC 行人数据库目前包含 3 个数据集该数据库主要用于车辆辅助驾驶中的行人检测研究。
9) USC 行人数据库的图像大部分来源于监控视频,是一个比较小的行人数据库,该数据库主要用于存在遮挡和多视角情况下的行人检测研究。
行人检测 深度学习篇
总体来说大部分浏览下就行。
樊恒,徐俊等.基于深度学习的人体行为识别[J].武汉大学学报,2016,41(4):492-497.
0 引言
目前研究行为识别的方法一般分为基于模型方法和基于相似性度量的方法,前者首先建立某种准则,然后从运动图像序列中提取目标的外形、运动等特征,根据所获得的特征信息,通过人工或半监督的方法来定义正常行为的数学模型。而基于相似度量的方法考虑到人体行为难定义、易发现的特点,避免显示定义人体行为的数学模型。其基本原理是自动从运动图像序列数据中学习各种人体行为,根据学习结果判断测试视频中的行为类型。
本文提出了一种基于深度信念网络(deep belief networks)的人体行为识别方法。
1 行为识别整体流程
流程图如下:
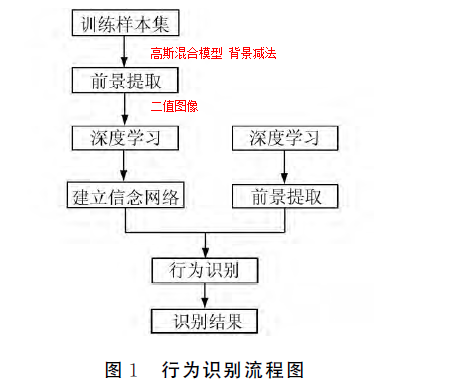
左侧分支为模型训练,右侧模型为识别过程。
2 前景提取
目前,目标检测方法主要有背景减法、光流法以及时间差分法等。为了实现检测的自适应性和实时性,本文选择基于高斯混合模型的背景减法,该方法实现简单、运算速度快,同时能够适应背景变化。(时间差分法一般较难提取出完整的运动目标,在运动目标内部容易产生空洞。光流法的计算相对复杂,抗噪能力较差。)具体数学运算,博客里不再详述,下图是效果:

(背景要不要这么单纯~~)
3 行为识别过程
行为识别过程中用到的深度学习相关内容这里不再详述,后面会有单独的博客的讨论。可先借鉴这篇http://blog.csdn.net/zouxy09/article/details/8781396
深度学习常用的模型有自动编码器、稀疏编码、深度信念网络等,本文选择DBNs模型。
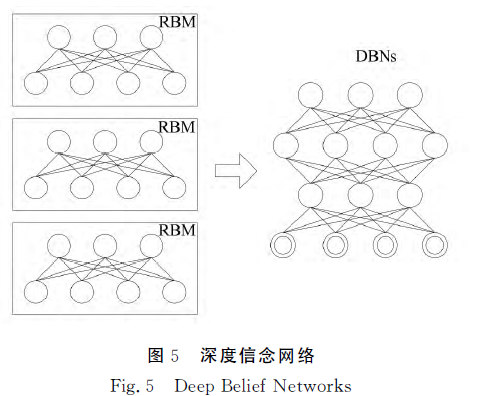
在深度神经网络中,任意两个相邻的隐含层构成一个受限玻尔兹曼机(Restricted Boltzmann Machine RBM),深度信念网络是一个包含多个隐含层的概率模型,每一层从前一个隐含层获取高度相关的关联,可以看作多个RBM 的累加,每个低层的RBM 输出结果作为输入数据用于训练下一个RBM,通过贪婪学习得到一组RBM,这一组RBM 可以构成一个DSNs,如下图
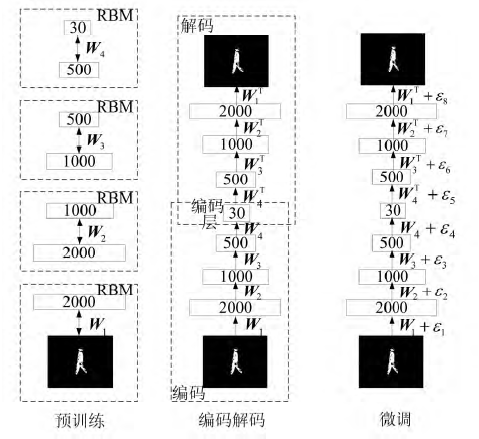
本文选择贪婪的逐层训练算法。在贪婪学习的过程中,采用了wake-sleep算法思想。学习过程如下:
4 实验分析
本文对比了不同的隐含层数,隐含层单元数及迭代次数与训练误差的关系。
同时与其他文献对比得到的结果显示较好。
芮挺等 基于深度卷积神经网络的行人检测 计算机工程与应用 2015
通过本文可以熟悉普通卷积神经网络应用的过程
0 引言
与hog+svm或adaboost对比,得到的更好的结果
1 卷积神经网络结构与特点
卷积神经网络的讲解,下面这篇文章讲的比较好
http://www.36dsj.com/archives/24006
2 行人检测卷积神经网络结构
经典卷积神经网络不能有效完成行人检测任务,网络深度、卷积核大小、最终提取特征维数,是影响结果的主要因素。因此需要针对行人检测问题的具体特点,对卷积神经网络的结构进行重新的设计。主要考虑一下问题:
1. 卷积核的影响。卷积核是卷积神经网络模型中最具特性的部分,可以理解为生物视觉中感受野的模型化表示。它的性质直接决定了特征提取的好坏、网络收敛的速度等。卷积核的大小决定了感受野的大小,感受野过大,提取的特征超出卷积核的表达范围,而感受野过小,则无法提取有效的局部特征。因此,卷积核大小对整个网络的性能有着至关重要的影响。
2. 通过增加网络的层数,其特征信息表达能力逐步增强,但层数过多也会致使网络结构过于复杂,训练时间增加,易出现过拟合现象
3. 分类器输入特征维数的影响
基于上述分析,对行人检测卷积神经网络进行了重新设计,并通过实验对上述思想及网络结构参数进行了验证。最终确定深度卷积神经网络结构共分7 层,卷积核大小为9x9,隐含层输出特征维数为360 维左右。
3 实验对比总结
还是老样子,实验结果很好,方法很好……
张 阳 基于深信度网络分类算法的行人检测方法[J] 计算机应用研究 2016,33(02)
0 引言
通过搭建带 T 分布函数显层节点的受限波兹曼机输入端改进深信度网络的输入方式,将行人特征提取信息通过输入端的显层结构转换为分类器可以识别的伯努利分布方式; 搭建多隐层受限波兹曼机中间层结构,实现隐层结构间的数传递,保留关键信息。最后,利用 BP 神经网络搭建分类结构的输出端,实现分类误差信息反向传播并对分类结构的参数进行微调,不断优化分类器结构。
1 改进的深信度网络分类算法
1.1 带 T 分布函数显层节点的 RBM
由于利用深信度网络实现特征分类时,输入一般为二值向量信息,而行人检测领域中,行人特征值信息的数值属性为连续整数或实数值。所以,直接使用 DBN 算法实现行人特征分类和识别势必会造成信息数据的丢失而影响分类效果。本文对深信度网络深度学习算法进行改进,通过引入带 T 分布函数显层节点的输入层使其能够更好地处理行人特征信息,进而通过网络预训练和网络微调实现信息分类和行人识别。
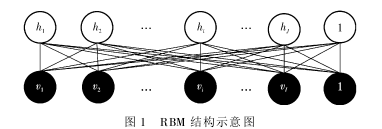
如上图 所示,显层结构 v 和隐层结构 h 共同构建一个 RBM结构,通过比较显层结构单元与隐层结构单元之间的关联差异性,可调整各单元权值。由于本文采用的行人特征近似服从 T分布函数(LABH 算法提取行人特征,该特征的累积概率分布近似满足 T 分布),本文搭建一种新的带 T 分布函数显层节点的 RBM,在显层结构和隐层结构之间实现将 T 分布函数转换成伯努利分布的功能。在带 T 分布函数显层节点的 RBM 中,显层结构服从 T 分布,隐层结构服从伯努利分布,其能量函数表达式如下:
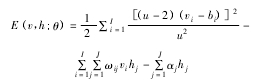
u为 T 分布函数的自由度,用于控制分布形态变化,
uu−2
为 T 分布函数的方差值.
和传统的 RBM 类似,带 T 分布函数显层节点的 RBM 的联合分布与能量函数的关系表达式为:
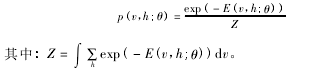
带 T 分布函数显层节点的 RBM 中,显层和隐层节点对应的条件概率可表示为
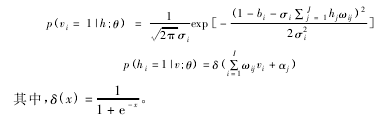
1.2 深信度网络搭建及预训练
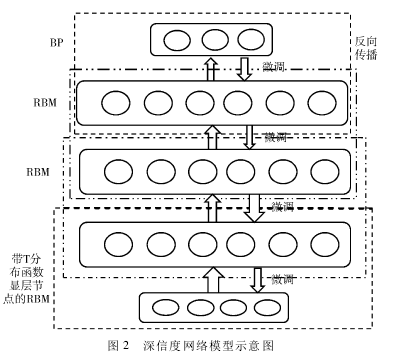
本文搭建的深信度网络由一层带 T 分布函数显层节点的RBM、多层传统的隐层 RBM 和一层 BP 网络构成。其中,带 T分布函数显层节点的 RBM 为数据输入层,将行人特征信息转换为深信度网可以识别的伯努利数据,数据经过转换后,在多层 RBM 中经过提取和抽象,保留关键信息并剔除冗余信息,最后一层 BP 网络是系统的输出层,经多层 RBM 转换后的信息进入 BP 层,利用 BP 网络的反向传播能力,对输出结构进行监督,反向微调整个深信度网络模型参数,达到优化模型分类效果的目的。本文搭建的深信度网络模型示意图如下图 所示。该示意图由一层带 T 分布函数显层节点的 RBM、两层隐层RBM 和一层 BP 网络构成,数据由底部的带 T 分布函数显层节点的 RBM 输入,由顶部 BP 网络输出,顶部 BP 网络有反向转播和微调整个深信度网络模型的能力,从而优化模型结构。
1.3 微调
深信度网络微调阶段的实现过程分两个步骤: a) 利用 BP 网络的向前传播性能,将连接 BP 网络的RBM 处理后的信息经进一步处理后,将分类结果输出; b) 反向传播,通过比较 BP 网络输出结果与真实结果,得出两者之间的误差值,将其反向传播至输入端,利用共轭梯度法优化分类模型的参数。
2 基于深信度网络的行人特征分类
2.1 预处理
本文使用 LABH 算法提取行人特征,该特征的累积概率分布近似满足 T 分布。将行人样本库进行如下处理: a) 利用 LABH 算法提取行人特征; b) 确定 T 分布的自由度参数取值,拟合行人特征分布; c) 根据行人特征分布区间计算特征项的权重值。
2.2 行人特征分类器

3 性能评价
其结构特征对性能影响
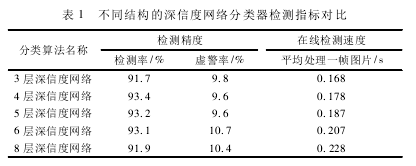
现有的深信度网络分类器多采用高斯( 显层) —伯努利( 隐层) RBM 实现语音、图像等数据的分类识别。本节通过实验对传统的高斯( 显层) —伯努利( 隐层) RBM 和本文提出的带 T 分布( 显层) —伯努利( 隐层) 的 RBM 检测结果加以对比,并对本文所提出算法的检测性能进行分析和评估。
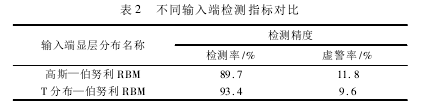
对各分类的比较
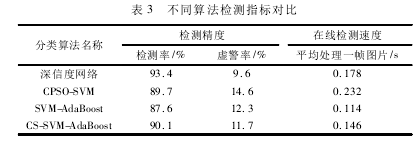















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









