







首先接触过那么多优化的方法,但是,究竟何为“优化”?
可以参考知乎某答:最优化问题的简洁介绍是什么?
简单来说,优化分为两步:
1. 构造目标函数
构造一个合适的目标函数,使得这个目标函数取到极值的解就是你所要求的东西; (构造目标函数)
即构造出::
obj = loss + λΩ
注意:使用因子来衡量二者的重要程度,这是权重或者系数的本质意义吧
再通俗直白地说,目标即使得模型能够自动选择分类效果好,并且尽量简单的参数:
目标函数= 模型分类正确率 + r * 模型复杂度
2. 确定最优化方法
找到一个能让这个目标函数取到极值的解的方法。(最优化方法)
即使用求得下面式子的参数w。
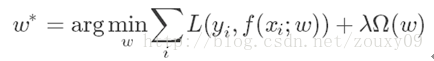
为了达到目的,模型的训练往往首先给参数赋上随机初值,然后用各种下降法来寻找能让分类错误率更小的参数设置,梯度下降、牛顿法、共轭梯度法和Levenberg—Marquard法都是常见的方法。
随着研究的深入,问题也越来越多,比如下降法往往只能保证找到目标函数的局部最小值,找不到全局最小值,怎么办呢?答案是不一味下降、也适当爬爬山,说不定能跳出小水沟(局部极小值)找到真正的深井(全局极小值),这种算法叫模拟退火。也可以增大搜索范围,让一群蚂蚁(蚁群算法)或者鸟儿(粒子群算法)一齐搜索,或者让参数巧妙地随机改变(遗传算法)。
。。。















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









