







多元线性回归的表达式理解
之前对于线性表达式w和x哪个在前和在后一致产生了疑问。查阅下面的资料终于搞清楚了。f(x)是有两种表达形式的,其结果都可以表示两个向量在做内积运算,得到的是一个数值,因此是无所谓w和x谁在前谁在后,只是习惯写成下面这样。
(
x
1
,
x
2
,
.
.
.
,
x
d
,
1
)
(x_1,x_2,...,x_d,1)
(x1,x2,...,xd,1)表示的是某一个样本对应的数据在各个特征向量对应的值。
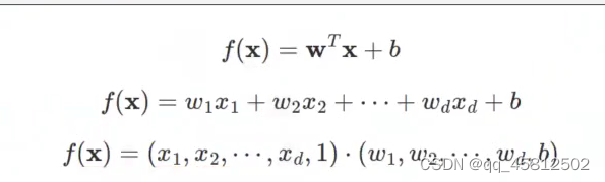
上面这个是单个样本,此时的f(x)是一个确定的值而不是一个向量。当我们引入多个样本时,
x
(
1
)
,
x
(
2
)
x^{(1)},x^{(2)}
x(1),x(2)就是分别对应第一个样本和第二个样本,引入矩阵X(样本数,2)。并且让特征矩阵在前,权重向量在后,这样保证了线性回归得到的y值输出来的也是一个列向量(样本数,1)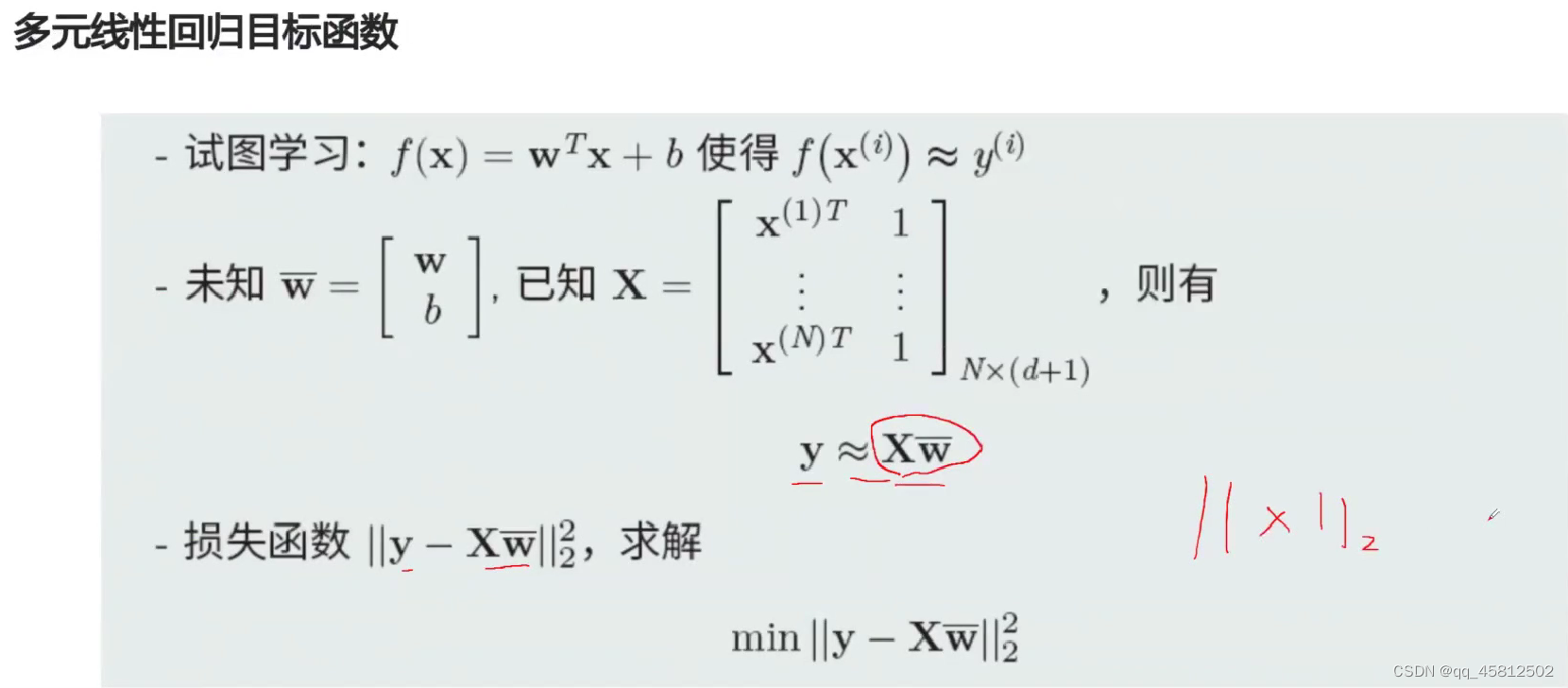
二次型

Hessian 矩阵(二阶导)
xgboost里面就用到了海森矩阵。

梯度计算
找极值最常见的一种方法就是找到导数值为0的点,这个点对应的值就为极值点。虽然求导(求梯度)操作很简单,但是想要找到对应的零点不是一件简单的事(函数太复杂)。因此一般的机器学习算法不是采用的这种优化方法。

梯度下降
-
优化方法更多的是采用这种无约束优化迭代法,例如梯度下降,牛顿迭代法,动量法…他们的大致思想都是一样的,区别就在于下降时的方法选取。
-
机器学习和深度学习大部分模型都是采用的梯度下降方法来进行优化的,神经网络的反向传播就是基于梯度下降这一方法来实现的。

- 梯度下降是基于泰勒展开式的一个假设:就是认为一阶泰勒展开,已经能够比较好地估计x附近的值。
- 从泰勒公式上也可以来看, δ \delta δ就是移动的大小,也就是跟学习率差不多(步长),当这个值很大的话,就会导致更高阶的泰勒展开值会变大,这样一阶泰勒展开就不能很好地近似表示移动后的值了。因此学习率要小一点便于收敛。

梯度下降举例
梯度,就是每个变量的偏导数组合成的向量。
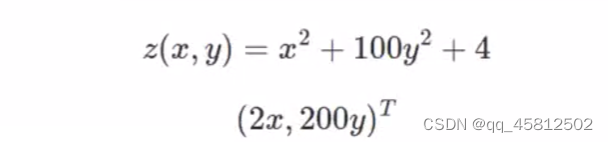
下降迭代的终止条件就是梯度值对应的范式小于给定的阈值,可以是第一范式也可以是第二范式。(原来的理解是应该是写导函数而不是写范式,但是考虑到在较复杂的函数时计算可能会很复杂)

神经网络训练batch的技巧
batch越大,得到的梯度值越接近于整体的梯度值,因此模型训练越稳定。batch越小,模型训练时波动更大,但是也会更加容易跳出局部最优解。
训练测试时,一般都是选择先使用较小的batch来进行训练,这样波动更大有利于更快地找到一些局部最优点,最后的时候batch更大更有利于收敛到最优点值。
















 4410
4410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









