









SuperPoint:Self-Supervised Interest Point Detection and Description 论文阅读
简介
- 监督学习从图像中提取点的方法被广泛研究
- 物体检测
- 人体关节位置检测
- 等等
特征点的语义信息不明确,难以进行人工标注,如何进行网络训练?
文中的思路为
- 自动标注得到伪真实值
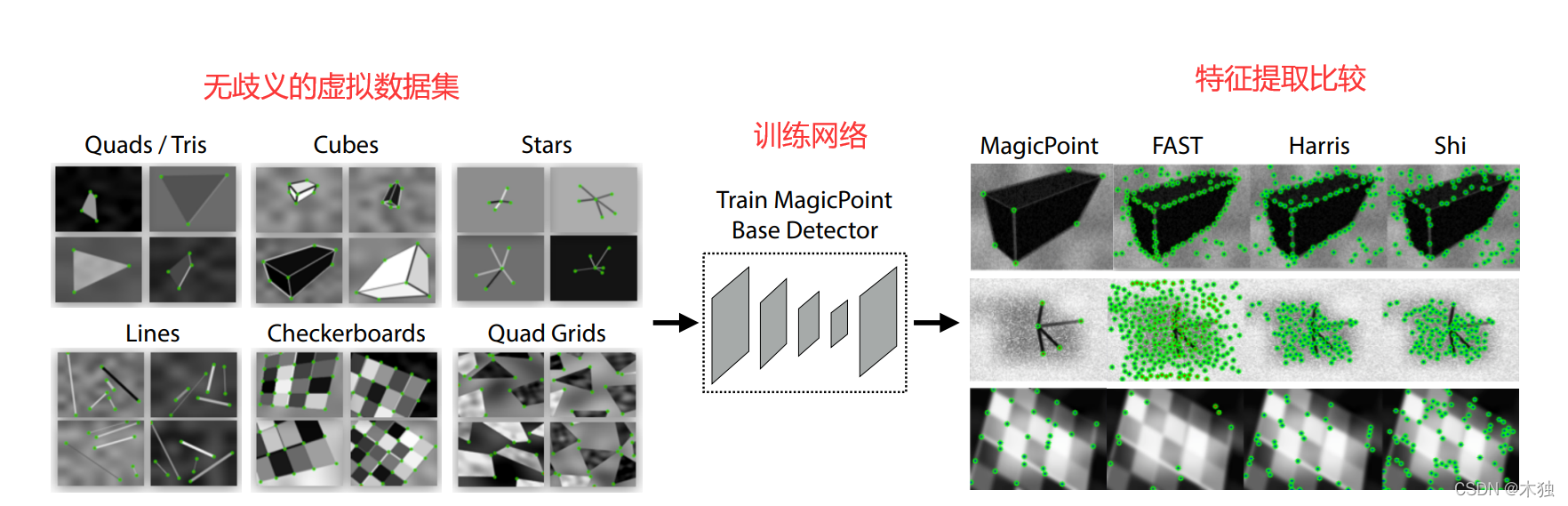
- 生成特征点位置无歧义的虚拟数据集
- 训练得到特征提取网络MagicPoint
- 对图片进行旋转、缩放等变换并利用MagicPoint进行提取,集合所有提取得到的特征点位置作为伪真实值(添加了旋转不变性和尺度不变性)
- 转换为成熟的监督学习,设计网络进行学习
总结如下图:
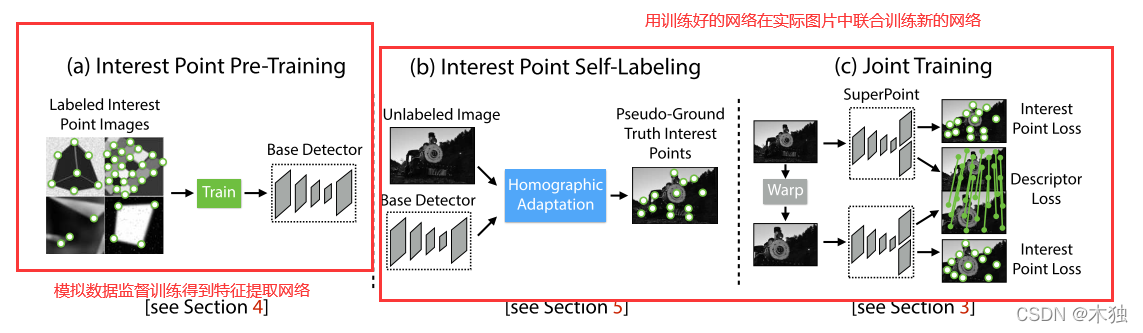
因此,总结创新点如下:
- 提出了一种自监督训练提取特征点和描述子的方法
- 提出了一种生成伪真实特征点标签方法
- 针对全图进行而非基于patch
这篇文章最突出的点在于不再是用网络逼近拟合现有的传统特征点了,而更接近数据驱动自己找到的特征点。但并没有完全实现直接从数据中学到而是利用了虚拟数据集中的训练结果。
方法
网络结构
整体网络架构如下图:
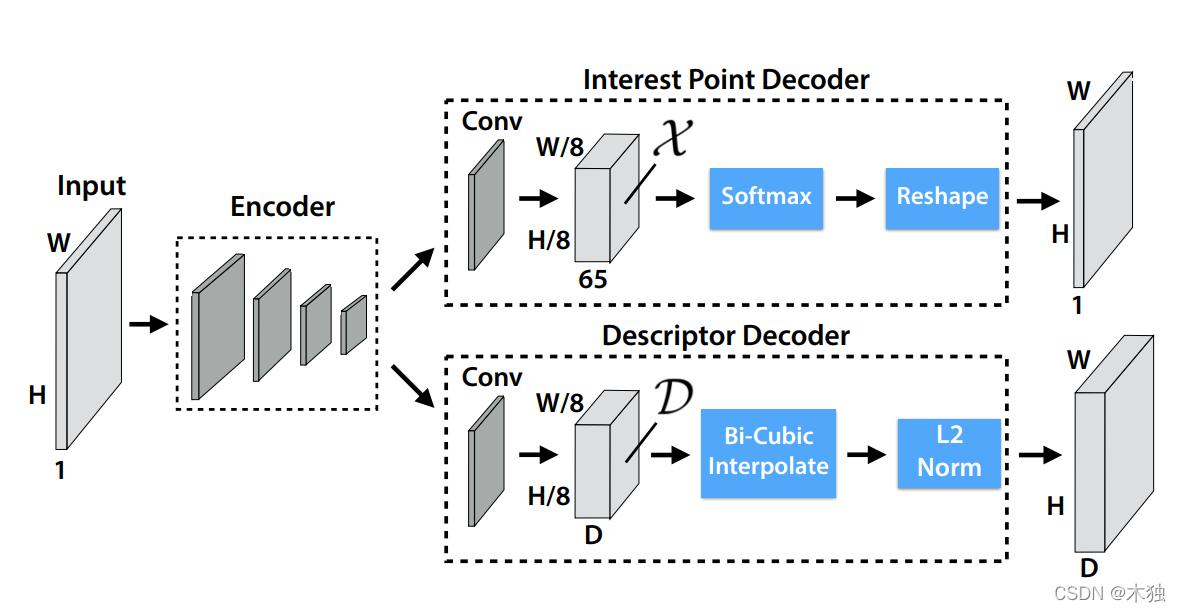
包括三个部分
- 共享特征提取编码网络
- VGG风格网络,结构为
- H × W × 64 → H × W × 64 → H / 2 × W / 2 × 64 → H / 2 × W / 2 × 64 → H / 4 × W / 4 × 128 → H / 4 × W / 4 × 128 → H / 8 × W / 8 × 128 → H / 8 × W / 8 × 128 H\times W \times 64 \to H\times W \times 64 \to H/2\times W/2 \times 64 \to H/2\times W/2 \times 64 \to H/4\times W/4 \times 128 \to H/4 \times W/4 \times 128 \to H/8\times W/8 \times 128 \to H/8\times W/8 \times 128 H×W×64→H×W×64→H/2×W/2×64→H/2×W/2×64→H/4×W/4×128→H/4×W/4×128→H/8×W/8×128→H/8×W/8×128
- 特征点提取解码网络
- 网络结构
- 输入 H / 8 × W / 8 × 128 H/8\times W/8 \times 128 H/8×W/8×128 特征
- 卷积得到 H / 8 × W / 8 × 65 H/8\times W/8 \times 65 H/8×W/8×65
- channel-wise softmax 变换,并去掉第 65层得到 H / 8 × W / 8 × 64 H/8\times W/8 \times 64 H/8×W/8×64
- reshape 操作将 H / 8 × W / 8 × 64 H/8\times W/8 \times 64 H/8×W/8×64 大小矩阵转换为 H × W × 1 H\times W \times 1 H×W×1 代表最终得分
- 为什么要构建65层,需要额外的一行特征?
- 如果只有64层,那么经过softmax之后,所有的得分之和就会等于1,这意味着这个小区域即使是完全空白也将获得平均得分 1/64
- 因此65行存在的意义在于当这个小区域没有特征时,这一行数据非常大,使得整体经过softmax之后前64行的得分很小,从而使得该区域被标记为没有特征点的区域。
- 网络结构
- 描述子解码网络
- 网络结构
- 输入 H / 8 × W / 8 × 128 H/8\times W/8 \times 128 H/8×W/8×128 特征
- 卷积得到 H / 8 × W / 8 × D H/8\times W/8 \times D H/8×W/8×D描述子
- 双线性插值 H × W × D H\times W \times D H×W×D
- L2-normalizes 归一化
- 网络结构
误差函数
L ( X , X ′ , D , D ′ ; Y , Y ′ , S ) = L p ( X , Y ) + L p ( X ′ , Y ′ ) + λ L d ( D , D ′ , S ) L(X,X^{'},D,D^{'};Y,Y^{'},S)=L_p(X,Y)+L_p(X^{'},Y^{'}) + \lambda L_d(D,D^{'},S) L(X,X′,D,D′;Y,Y′,S)=Lp(X,Y)+Lp(X′,Y′)+λLd(D,D′,S)
- 两张图片中特征点提取误差
- 特征点匹配误差
特征点检测误差
L
p
(
X
,
Y
)
=
1
H
c
W
c
∑
h
=
1
,
w
=
1
H
c
,
W
c
l
p
(
x
h
w
,
y
h
w
)
L_p(X,Y) = \frac{1}{H_c W_c}\sum_{h=1,w=1}^{H_c,W_c}l_p(x_{hw},y_{hw})
Lp(X,Y)=HcWc1h=1,w=1∑Hc,Wclp(xhw,yhw)
其中,
l
p
(
x
h
w
;
y
)
=
−
log
(
exp
(
x
h
w
y
)
∑
k
=
1
65
exp
(
x
h
w
k
)
)
l_p(x_{hw};y)=-\log \left(\frac{\exp (x_{hwy})}{\sum_{k=1}^{65} \exp (x_{hwk})}\right)
lp(xhw;y)=−log(∑k=165exp(xhwk)exp(xhwy))
描述符匹配误差
L d ( D , D ′ , S ) = 1 ( H c W c ) 2 ∑ h = 1 , w = 1 H c , W c ∑ h ′ = 1 , w ′ = 1 H c , W c l d ( d h w , d h ′ w ′ ′ ; s h w h ′ w ′ ) L_d(D,D^{'},S)=\frac{1}{(H_c W_c)^2} \sum_{h=1,w=1}^{H_c,W_c} \sum_{h^{'}=1,w^{'}=1}^{H_c,W_c}l_d(d_{hw},d^{'}_{h^{'}w^{'}};s_{hwh^{'}w^{'}}) Ld(D,D′,S)=(HcWc)21h=1,w=1∑Hc,Wch′=1,w′=1∑Hc,Wcld(dhw,dh′w′′;shwh′w′)
其中,
l
d
(
d
,
d
′
;
s
)
=
λ
s
∗
s
∗
max
(
0
,
m
p
−
d
T
d
′
)
+
(
1
−
s
)
∗
max
(
0
,
d
T
d
′
−
m
n
)
l_d(d,d^{'};s) = \lambda_s *s* \max (0, m_p - d^T d^{'}) + (1 - s)*\max(0,d^T d^{'} - m_n)
ld(d,d′;s)=λs∗s∗max(0,mp−dTd′)+(1−s)∗max(0,dTd′−mn)
- 由于 d , d ′ d,d^{'} d,d′是归一化之后的,所以 d T d ′ d^Td^{'} dTd′仅当二者重合时取最大值。
- 当s取 1时,只有第一项,两者的误差越小, d T d ′ d^Td^{'} dTd′越大越好,因此此时代表的是匹配点,正样本
- 当s取 0时,只有第二项,两者的误差越大, d T d ′ d^Td^{'} dTd′越小越好,此时代表的是非匹配点,负样本
- λ s \lambda_s λs为匹配过程中,正负样本的平衡系数,需要提高正样本的权重
MagicPoint 训练过程
单应变换
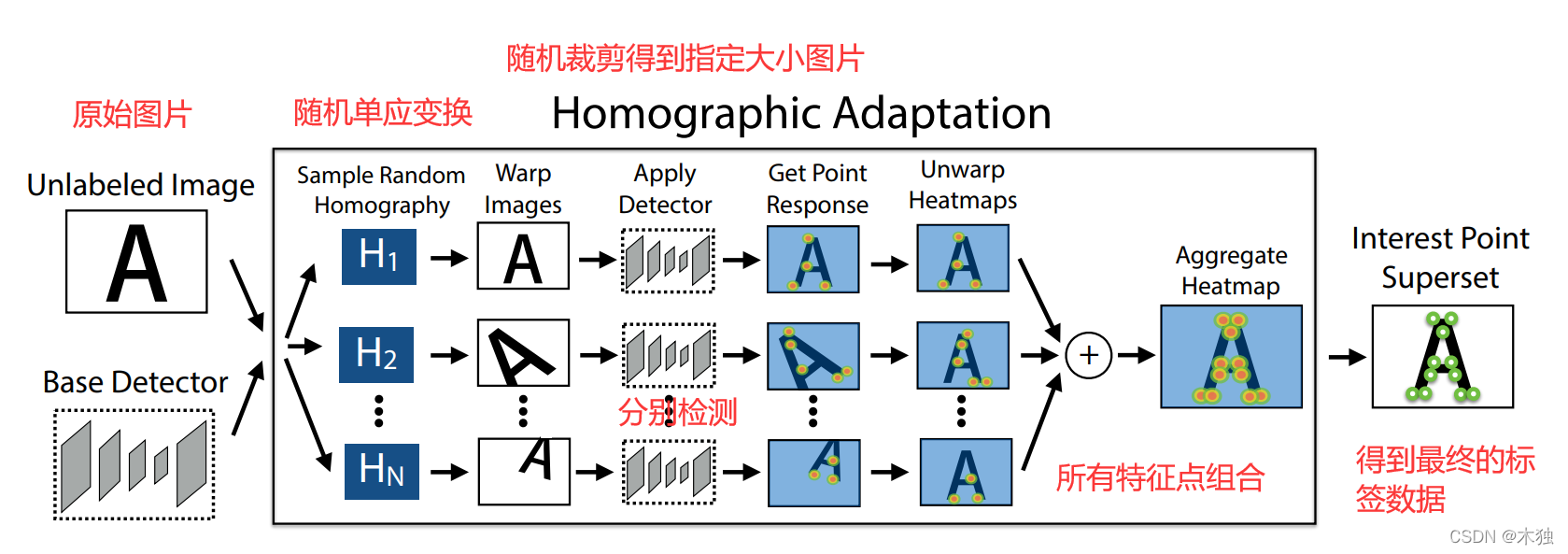
其中随机单应变换步骤如下:
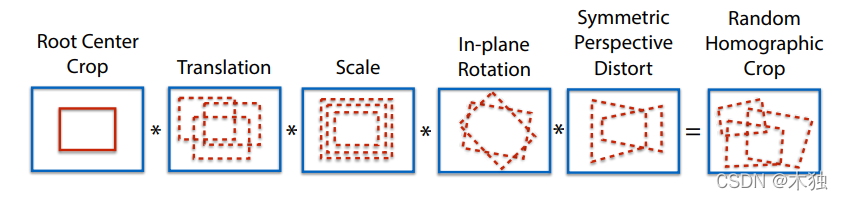
实验
运行时间
- 13ms / 70Hz (GPU)
HPatches 数据集验证
重复率
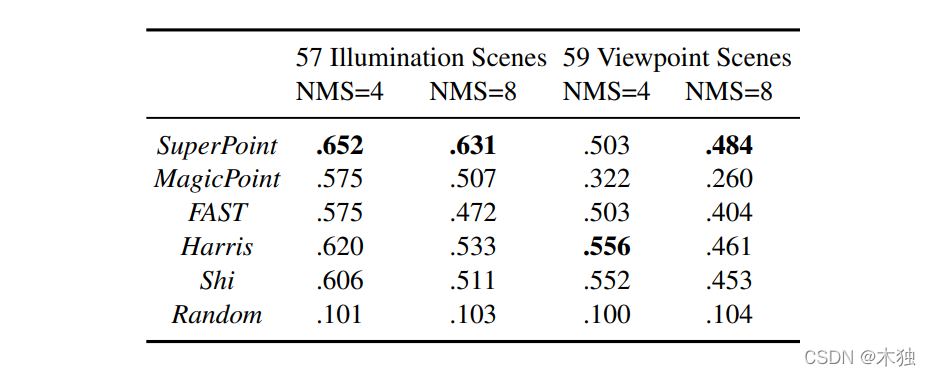
特征点提取的重复率比传统的要好很多
单应变换估计
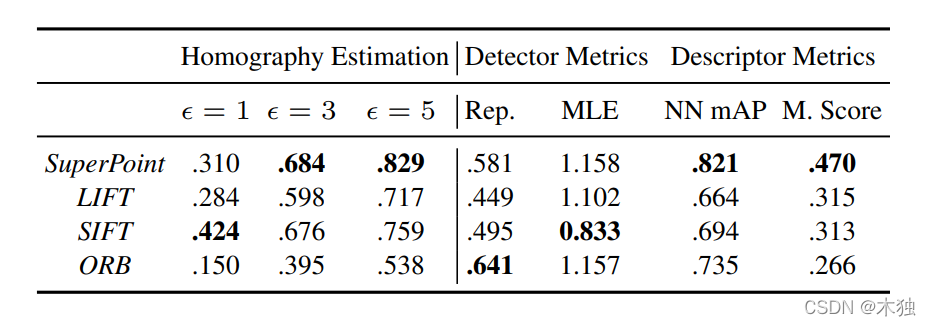
在误差范围限制比较宽松时准确率更高
这里匹配效果比起传统的并没有好很多,个人认为是描述子学习的效果不足
总结
意义:将特征点检测任务从拟合现有传统特征点提取,往更加纯粹的数据驱动靠近了一步
效果:特征点检测重复率较高,但是描述子匹配效果一般














 1851
1851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









