







一.原始GAN的优化问题
虽然生成对抗网络在理论上非常巧妙,但是我们发现在训练GAN的过程中会出现很多问题,其中最大的问题来源于训练的不稳定性。在理论上,我们应该优先尽可能地把判别器训练好,但实际操作上会发现,当判别器训练得越好,生成器反而越难优化。也就是所谓的GAN训练崩溃问题。
流形
想知道问题的来龙去脉,我们首先先了解一些理论知识。从理论和经验上来说,真实数据的分布通常是一个低维度流形(manifold)。流形指的是数据虽然分布在高维度空间里,但实际上数据并不具备高维度特性,而是存在于一个嵌入在高维度的低维度空间里。如下图所示:

上面的数据本质上存在于一个二维平面,只是以卷曲的形式存在于三维空间中。
而生成器要做的事情就是把一个低维度的空间Z映射到与真实数据相同的高维度空间上,而我们希望做的事情是能够把我们生成的这个低维度流形尽可能地逼近真实数据的流形。
但从理论上来说:如果真实数据与生成数据在空间上完全不相交的话,可以得到一个判别器来完美划分真实数据与生成数据。如果生成数据分布与真实数据分布在低维度上没有一部分能够完美地全维度重合的话,或者它们的交集在高维度上测度为0,那么依然会存在完美的判别器来将不同的数据完美划分。
在实际工程中,生成数据和真实数据在空间中完美重合的概率是非常低的,所以我们几乎是一定可以找到一个完美的判别器将生成数据和真实数据加以划分。所以在训练中网络的反向传播梯度更新几乎等于零,难以学习到任何东西。
总而言之就是JS散度和KL散度不能很好的计算表达生成数据和真实数据之间的距离。我们的判别器会训练得很好,导致了生成器的梯度消失问题。如下图所示:
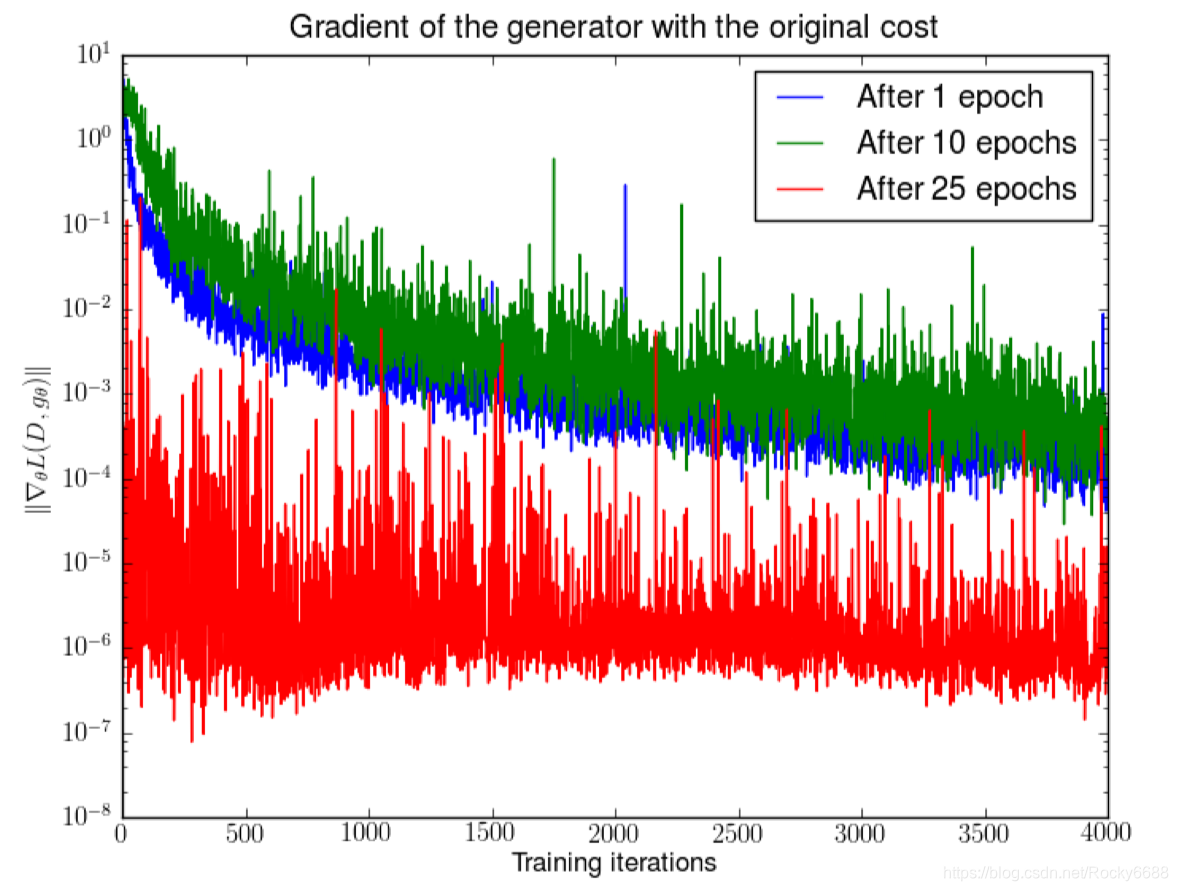
上图是DCGAN训练1个、10个和25个epoch,可以看到梯度快速下降,最好的情况在4000次迭代以后也下降了5个数量级。
有几个比较常用的通用方法避免梯度消失问题:
- 对生成器换一个不同的梯度函数。这个方法的缺点是可能会导致网络更新不稳定的情况。
- 对判别器的输入加入一个随机噪声。在实践中我们发现,当生成数据分布与真实数据分布很接近的时候,加入了随机噪声可以使得两者的低维度流形能够有更多的几率产生重合,使得JS散度的计算值下降,从而有效优化我们的网络参数。这个方法的缺点是如果生成数据和真实数据本身相似度距离较远的话,添加噪声的方法可能就无效了。
而下面介绍的Wasserstein距离则有效解决了梯度消失和训练不稳定的问题。
二 .WGAN登场
Wasserstein距离,也称作EM距离(Earth-Mover distance)。也可以叫做推土机距离,如果我们把生成数据分布和真实数据分布看作两个“土堆”的话,该距离相当于推土机把其中一堆土搬到另一堆的最小成本。
我们假设一个二维空间,假设真实数据的分布是X轴为0,Y轴为随机变量的分布,而生成数据的分布为X轴为 θ \theta θ,Y轴也为随机变量的分布,其中 θ \theta θ为生成数据分布的一个变量。
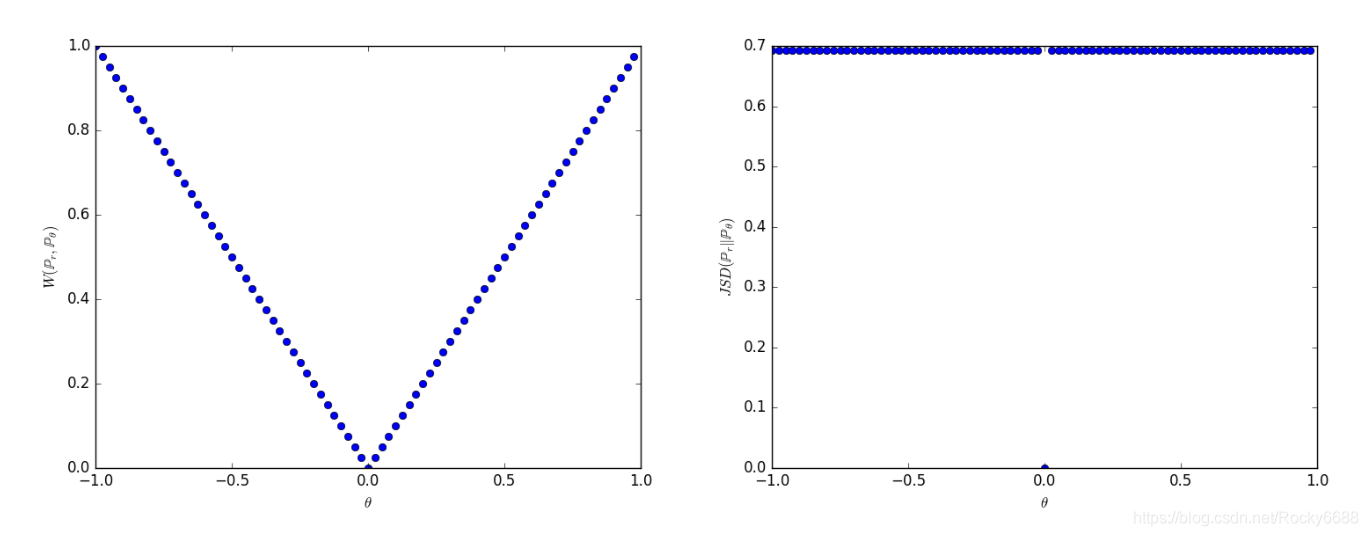
如上图所示,我们发现在 θ \theta θ逼近0的时候,只有W距离公式在减小,而JS散度是一个固定的值,根本无法产生有用的梯度来优化网络。
如果生成器G满足Lipschitz条件的话,那么可以推导出W距离处处连续且处处可导。Lipschitz条件是指函数的导数始终小于某个固定的常数K。当K=1时称为1-Lipschitz,也就是说导数始终小于1。
综合上述的各个方面,Wasserstein距离定义如下:
L = E x ∼ p d a t a ( x ) [ f w ( x ) ] − E x ∼ p g ( x ) [ f w ( x ) ] L={\rm E}_{x\sim{p_{data}}(x)}[f_w(x)] - {\rm E}_{x\sim{p_g}(x)}[f_w(x)] L=Ex∼pdata(x)[fw(x)]−Ex∼pg(x)[fw(x)]
为什么实现公式中的参数化条件 { f w } \{f_w\} {fw},在网络中使用的小技巧是权值裁剪(Weight Clippling),该方法是将权值的范围严格限制在[-c,c]之间,在网络更新权值且权值在范围外的时候,我们会将其裁剪为c或者-c。这样可以保证裁剪后的网络可以使得函数 f ( x ) f(x) f(x)满足Lipschitz条件。
通过最小化Wasserstein距离,得到了WGAN的Loss:
- WGAN生成器Loss: − E x ∼ p g ( x ) [ f w ( x ) ] - {\rm E}_{x\sim{p_g}(x)}[f_w(x)] −Ex∼pg(x)[fw(x)]
- WGAN判别器Loss: L = − E x ∼ p d a t a ( x ) [ f w ( x ) ] + E x ∼ p g ( x ) [ f w ( x ) ] L=-{\rm E}_{x\sim{p_{data}}(x)}[f_w(x)] + {\rm E}_{x\sim{p_g}(x)}[f_w(x)] L=−Ex∼pdata(x)[fw(x)]+Ex∼pg(x)[fw(x)]
WGAN与原始GAN的区别在于:
- 两者最大的差别在于WGAN的代价函数中并不存在log,其他与原始GAN基本保持一致。
- 对于判别器D,由于WGAN的目标在于测量生成数据分布与真实数据分布之间的距离,而非原始GAN的是与否的二分类问题,所以去掉了最后输出层的Sigmoid激活函数。
- 在更新权重的时候,我们需要加上权值裁剪使得网络参数能够保持在一定的范围内,从而满足Lipschitz条件。
- 将Adam等梯度下降方法改为使用RMSProp方法,这个是WGAN的作者经过大量实验得出的结论,使用Adam等方法会导致训练的不稳定,而RMSProp可以有效避免不稳定问题的发生。
我们再用一个图来直观的对比一下WGAN和原始GAN的区别:
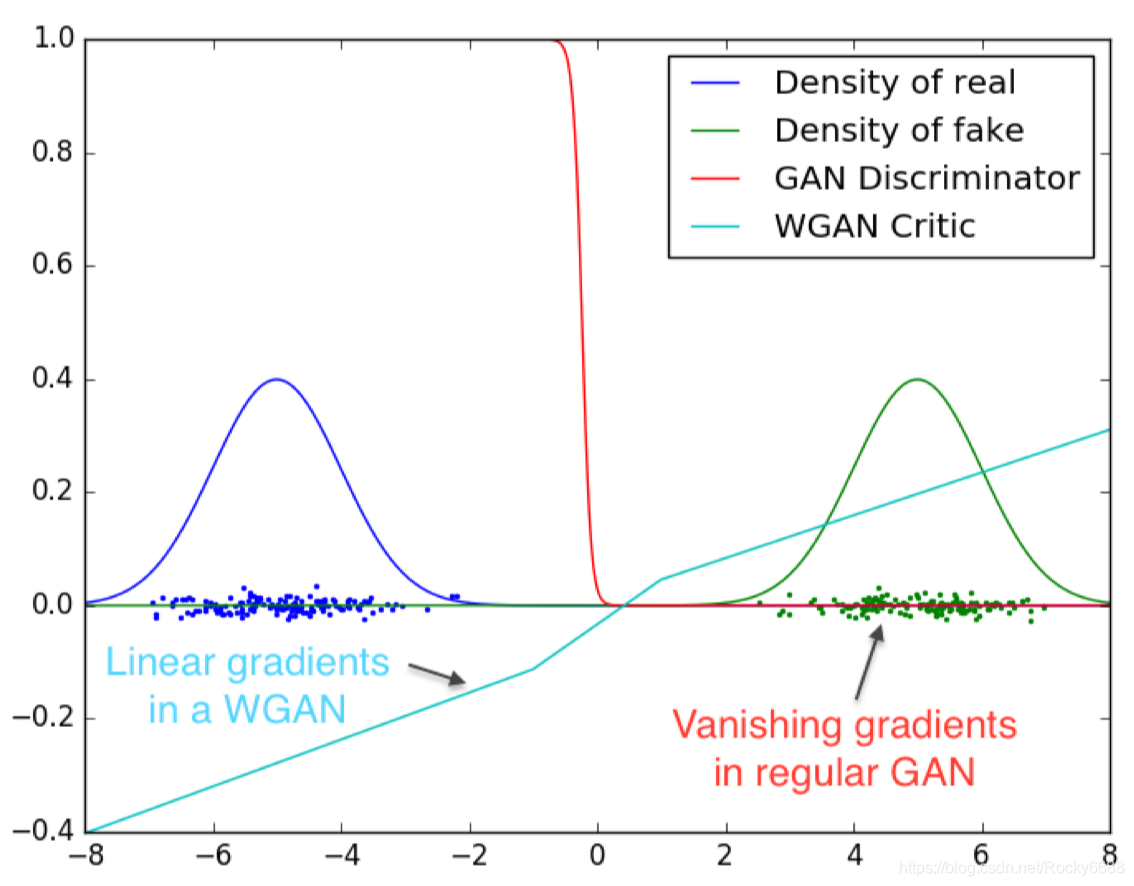
网络要做的事情就是通过判别器的梯度来优化网络参数,让生成器数据分布尽可能地靠近真实数据分布,而我们可以很明显地看到原始GAN在两个分布各自的区域所对应的梯度几乎是零,也就是所谓的梯度消失,非常难以对网络进行优化迭代,而WGAN对应的梯度则几乎是线性的,可以很好地达到真实数据分布与生成数据分布重合的目的。
实验结果
- 随着W距离的降低图像的生成质量也越来越高。随着生成器的迭代次数上升,一开始W距离快速下降,然后慢慢地趋于稳定。
- WGAN具有比原始GAN更稳定的生成能力,在最优架构的情况下可能还无法体现优势,但一旦网络中存在问题的话,使用WGAN能够在一定程度上避免图像质量的急剧下降。
- WGAN可以解决模式崩溃的问题。
三.WGAN-GP:带有梯度惩罚的WGAN
WGAN理论中一个非常重要的条件是需要满足1-Lipschitz条件,而对应使用的方法是权值裁剪,希望把整个网络的权值能够框定在一个大小范围内。但是权值裁剪会导致很多问题,比如:
-
权值裁剪限制了网络的表现能力。由于网络权值被限制在了固定的范围内,神经网络很难再模拟出那些复杂的函数,而只能产生一些比较简单的函数。
如上图所示,第一排为WGAN的结果,第二排为WGAN-GP的结果。可以看出WGAN已经失去了很多数据分布的高阶矩特性,而WGAN-GP则能有效降低这个问题。 -
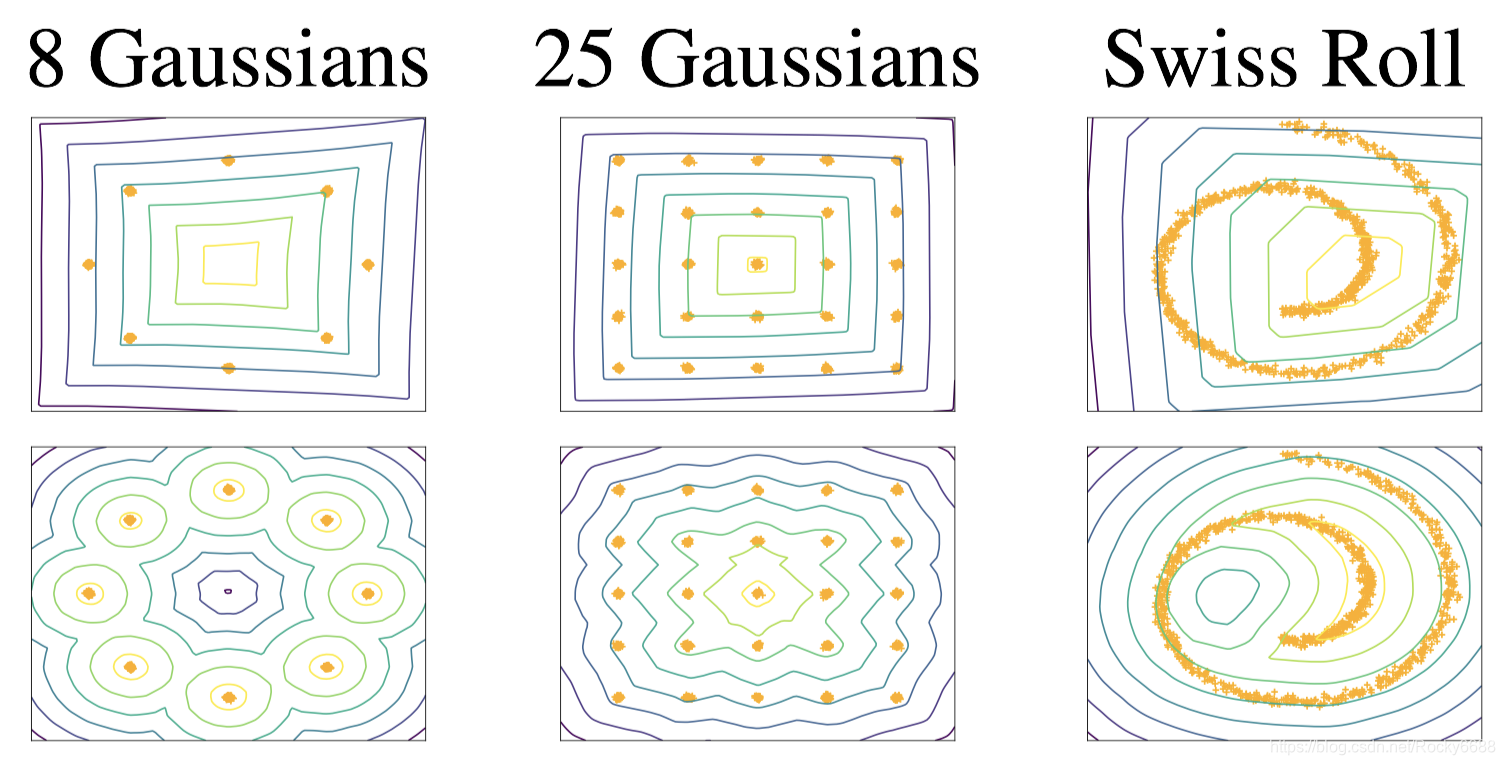
梯度爆炸和梯度消失。WGAN的权值裁剪需要我们自己设计权值限制的大小,也许不恰当的设计就会导致梯度爆炸或者梯度消失。在下图中,我们使用了Swiss Roll数据集,并分别将裁剪的权值大小设置为[10-1 ,10-2 ,10-3],并与WGAN-GP的结果做比较。WGAN的三种选择均产生了梯度爆炸或消失的情况,而WGAN-GP则始终能够保持稳定的梯度。下图也表现了在权值裁剪的时候,非常多的权值都会固定在边界上,这也是导致网络出现问题的原因,而WGAN-GP则能很好地让权值正常分布。
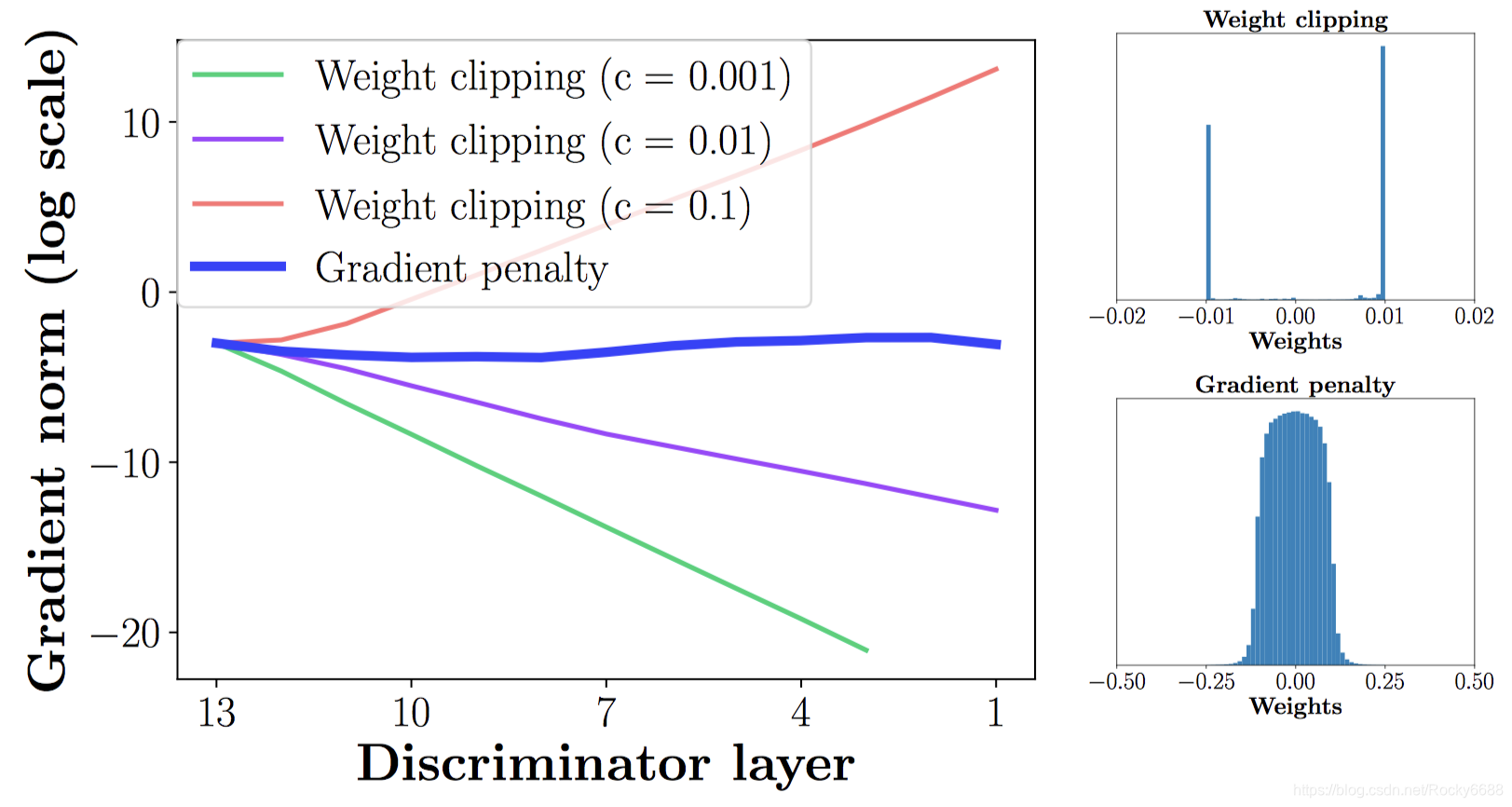
上面提到的梯度惩罚(gradient penalty) 来替代权值裁剪,从实验结果来看确实比原来的方案更稳定,在图像生成方面成像质量也更高。公式就是在原WGAN的基础上添加Lgp 。
L
=
L
o
r
i
g
i
n
+
L
g
p
L = L_{origin} + L_{gp}
L=Lorigin+Lgp
L o r i g i n = − E x ∼ p d a t a ( x ) [ D ( x ) ] + E x ∼ p g ( x ) [ D ( x ) ] L_{origin} = -{\rm E}_{x\sim{p_{data}}(x)}[D(x)] + {\rm E}_{x\sim{p_g}(x)}[D(x)] Lorigin=−Ex∼pdata(x)[D(x)]+Ex∼pg(x)[D(x)]
L g p = λ E x ∼ p x ( x ) [ ∥ ∇ x ( D ( x ) ) ∥ 2 − 1 ] 2 L_{gp} = \lambda{\rm E}_{x\sim{p_x}(x)}[\lVert\nabla_x(D(x))\rVert_2-1]^2 Lgp=λEx∼px(x)[∥∇x(D(x))∥2−1]2
L = − E x ∼ p d a t a ( x ) [ D ( x ) ] + E x ∼ p g ( x ) [ D ( x ) ] + λ E x ∼ p x ( x ) [ ∥ ∇ x ( D ( x ) ) ∥ 2 − 1 ] 2 L=-{\rm E}_{x\sim{p_{data}}(x)}[D(x)] + {\rm E}_{x\sim{p_g}(x)}[D(x)]+\lambda{\rm E}_{x\sim{p_x}(x)}[\lVert\nabla_x(D(x))\rVert_2-1]^2 L=−Ex∼pdata(x)[D(x)]+Ex∼pg(x)[D(x)]+λEx∼px(x)[∥∇x(D(x))∥2−1]2
上述公式中的采样分布 x ∼ p x ( x ) x\sim{p_x}(x) x∼px(x),它的范围是真实数据分布与生成数据分布中间的分布,具体的实现方法是在真实数据分布Pr 和生成数据分布Pg 各进行一次采样,然后在这两个点的连线上再做一次随机采样,就是我们希望的惩罚项采样。
对于上式中的惩罚系数 λ \lambda λ在论文中的默认值是10,在实验中能保证不错的效果。
由于上式是对每一个梯度进行惩罚,所以不适合使用BN,因为它会引入同个batch中不同样本的相互依赖关系。如果需要的话,可以选择层归一化(Layer Normalization)。
WGAB-GP重新使用了Adam方法,不存在WGAN中使用Adam方法稳定性不高的问题。

上图是WGAN-GP的研究者对四种GAN做的对比实验,可以看到DCGAN和LSGAN在大多数条件限制下都已经无法很好地生成图像。WGAN虽然能保持相对稳定的生成,但最后几组实验中生成图像已经有些模糊,难以辨认,但是WGAN-GP在所有条件下都保证了高质量的图像生成。


















 4134
4134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











