






目录
2.1、Beyond element-wise reconstruction error with VAE/GAN
一、背景
深度架构允许广泛的判别模型扩展到大型和多样化的数据集,然而,生成模型仍然存在图像和声音等复杂数据分布的问题。在这项工作中,本文表明,目前使用的相似性度量对学习良好的生成模型造成了障碍,可以通过使用学习的相似性度量来改进生成模型。
当学习模型如变分自编码器(VAE)时,核心是选择相似性度量,因为它通过重建误差目标提供训练信号的主要部分。对于这个任务,像平方误差这样的元素度量是默认值。元素度量很简单,但不太适合图像数据,因为它们不能模拟人类视觉感知的属性。例如,一个小的图像转换可能会导致一个大的像素级错误,而人类几乎不会注意到这种变化。因此,作者赞成使用图像的高级和足够不变的表示来测量图像相似性。作者希望学习任务的函数,而不是手工设计一个合适的度量来适应elementwise度量的问题。
问题是如何学习这种相似性度量?作者发现,通过联合训练一个VAE和一个生成对抗网络(GAN),可以使用GAN鉴别器来衡量样本相似性。
本文将VAE解码器和GAN生成器合二为一,让它们共享参数并共同训练它们。为了实现VAE训练目标,将典型的基于元素的重建度量替换为基于特征的判别器。
网络结构如下图所示:
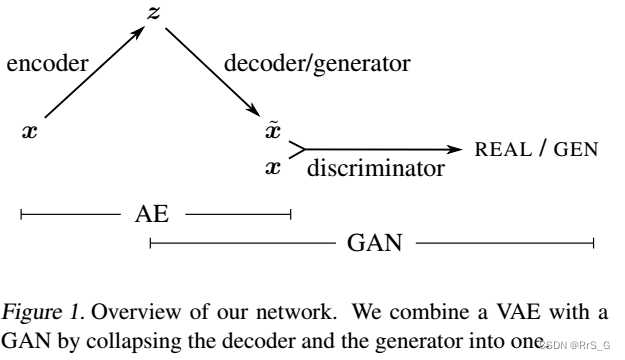
二、具有学习相似性的自动编码
本节介绍了结合VAE和GAN的方法,称之为VAE/GAN。正如下面将描述的,本文提出的混合动力是一种改进VAE的方法,因此它依赖于一个更有意义的、具有特征的度量来测量训练期间的重建质量。
2.1、Beyond element-wise reconstruction error with VAE/GAN
GAN的一个吸引人的特性是,它的鉴别器网络需要隐含地学习图像的丰富相似性度量,从而将它们从“非图像”中辨别出来。因此,作者建议利用这一观察,以便将鉴别器学习到的图像的性质转化为一个更抽象的重建误差的VAE。最终的结果将是一种结合GAN作为高质量生成模型的优势和VAE作为一种将数据编码器生成到潜在空间z的方法的方法。
由于元素的重建误差不足以满足图像和其他具有不变性的信号,作者建议用GAN鉴别器中表示的重建误差替换VAE中的重建误差项。为了实现这一点,让表示鉴别器的第l层的隐藏表示。本文引入一个具有均值
和恒等协方差的
高斯观测模型:
(6)
其中为x的解码器的样本。可以用下式替换VAE中的重建误差:
(7)
总损失为:
(8)
第一项和第三项损失原文有,这里不再赘述。
值得注意的是,本文优化了关于的VAE,作者认为这是一个风格误差,除了重建误差,可以解释为内容误差。此外,因为Dec和Gen都是从z映射到x的,所以作者在二者之间共享参数(换句话说,使用Dec而不是Gen)。
在实践中,作者在这个模型的开发和训练过程中观察到了细节中的问题。因此,作者在本节提供了一些实际的考虑因素。训练过程概述见图2。
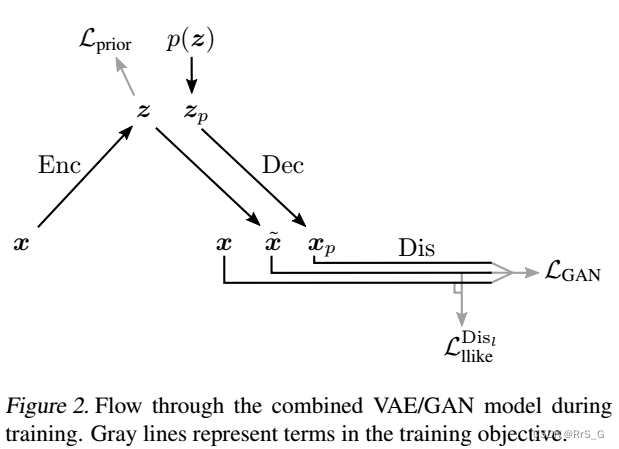
将误差信号限制到相关网络
利用公式8中的损失函数,同时训练VAE和GAN。这是可能的,因为没有更新所有的网络参数。特别地,Dis不应该试图最小化,因为这会将辨别器崩溃为0。作者也观察到较好的结果,不反向传播误差信号从
到Enc。
加权VAE vs GAN
当Dec接收到来自和
的误差信号时,作者使用一个参数γ来权衡重构和愚弄鉴别器的能力。这也可以解释为对风格和内容的加权。而不是将γ应用到整个模型(Eq. 8),只在更新Dec的参数时执行加权:
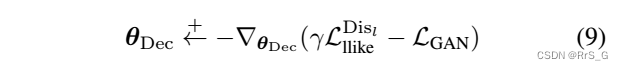
基于p(z)和q(z|x)的样本判别
当使用来自q(zlx)(即编码器Enc)的样本时,除了在GAN目标中的先验p(z)外,作者观察到更好的结果:
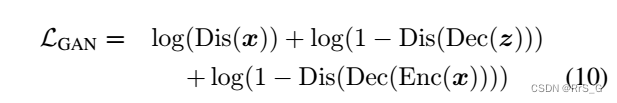
注意,潜空间的正则化应该使p(z)或q(z|x)的样本集相似。然而,对于任何给定的例子x,负样本Dec(Enc(x))比Dec(z)更可能与x相似。在根据
进行更新时,作者怀疑具有相似的正样本和负样本可以获得更有用的学习信号。
具体算法如下:


















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









