









HRNet
具体实现参考:

1.提出High-Resolution网络---用其他scale信息来增强当前scale信息,不同于hourglass网络,只是为了将底层和高层信息融合起来
每次下采样视为一个stage,每个stage间不断的通过exchange unit进行信息传递,每个stage的特征图都是由其他stage组合得到的。
exchange unit:higher stage通过conv下采样,lower stage通过上采样+$1×1$卷积,当前stage直接卷积,三者resolution一致后进行逐像素相加得到该阶段的特征图,实现多scale的信息整合
优点:高分辨率始终存在,而不是从低分辨率中恢复,信息表达能力更强,可以提高对小目标的检测性能
2.heatmap:只取最后exchange unit的最高分辨率输出进行预测(尽管多个stage有多个resolution输出,但只用最大的进行预测)
HRNetV2将最后所有stage输出concat为一各,然后进行卷积再预测,性能得到提升
3.backbone:每个stage都是由residual unit和exchange unit组成,前者用于特征提取,后者用于信息交换。------具体还没弄明白
优于SENet:既有通道注意力,也有空间注意力 ,SENet只是其特例,只包含通道注意力机制。
优于ResNet,Hourglass,SENet
具体结构(可以了解)
图例:
虚线表示,输入输出channel一致,不需要任何操作,不存在conv就是None
graph LR
subgraph pre["pre stage"]
input32["input(32)"]
input64["input(64)"]
end
subgraph cur["cur stage"]
output16["output(16)"]
output64["output(64)"]
output128["output(128)"]
output256["output(256)"]
end
conv0["conv(32,16)"]
input32-->conv0-->output16
input64.->output64
conv1["conv(64,128)"]
input64-->conv1-->output128
conv2["conv(64,64)"]
conv3["conv(64,256)"]
input64-->conv2-->conv3-->output256该网络的详细结构如下:(4×8=32倍降采样,起始4×的特征提取,4个stage的8×降采样)
HRNet由初步特征提取+4个stage组成
初步特征提取:两个卷积组成,步长都为2。inplanse=3,planes=64
第一个stage:inplanse=64,planes=256
一个layer:
4个Bottleneck。
第二个stage:inplanse=256,planes=[32,64]
transition layer:[256]转换成[32,64]两个branch
一个module:
两个branch:
第一个branch:4个BasicBlock,planes=32
第二个branch:4个BasicBlock,planes=64
一个fuse layers:
第一个branch:第二个branch的输出经过conv(64,32,stride=1)+upsample(2×),planes=32
第二个branch:第一个branch的输出经过conv(32,64,stride=2),planes=64
第三个stage:inplanse=[32,64],planes=[32,64,128],具体转化方法看上图示例
transition layer:[32,64]转换成[32,64,128]三个branch
4个module:每个module都一样
3个branch
第一个branch:4个BasicBlock,planes=32
第二个branch:4个BasicBlock,planes=64
第三个branch:4个BasicBlock,planes=128
一个fuse layers:
1st branch:
2nd branch的output经过conv(64,32,1)+upsample(2×),planes=32
3rd branch的output经过conv(128,32,1)+upsample(4×),planes=32
2nd branch:
1st branch的output经过conv(32,64,2),planes=64
3rd branch的output经过conv(128,64,1)+upsample(2×),planes=64
3nd branch:
1st branch的output经过conv(32,32,2)+conv(32,128,2),planes=128
2nd branch的output经过conv(64,128,2),planes=128
第四个stage:inplanse=[32,64,128],planes=[32,64,128,256]
transition layer:[32,64,128]生成[32,64,128,256]
3个module:每个module都一样
4个branch
1st branch:4个BasicBlock,planes=32
2nd branch:4个BasicBlock,planes=64
3rt branch:4个BasicBlock,planes=128
4th branch:4个BasicBlock,planes=256
一个fuse layers:
1st branch:
2nd branch的ouput经过conv(64,32,1)+upsample(2×),planes=32
3rd branch的output经过conv(128,32,1)+upsample(4×),planes=32
4th branch的output经过conv(256,32,1)+upsample(8×),planes=32
2nd branch:
1st branch的output经过conv(32,64,2),planes=64
3rd branch的output经过conv(128,64,1)+upsample(2×),planes=64
4th branch的output经过conv(256,64,1)+upsample(4×),planes=64
3rt branch:
1st branch的output经过conv(32,32,2)+conv(32,128,2),planes=128
2nd branch的output经过conv(64,128,2),planes=128
4th branch的output经过conv(256,128,1)+upsample(2×),planes=128
4th branch:
1st branch的output经过conv(32,32,2)+conv(32,32,2)+conv(32,256,2),planes=256
2nd branch的output经过conv(64,64,2)+conv(64,256,2),planes=256
3rd branch的output经过conv(128,256,2),planes=256
HigherHRNet

1.使用associative embedding(关联嵌入)进行分组
2.backbone为HRNet
多尺度信息始终保留,且更加efficient
3.提高对小人物的检测:
对1/4特征图和1/4heatmap反卷积到1/2以提高对小人物的检测,传统的缩小gt heatmap高斯核的平方差会导致训练困难且性能变差
Deconvolution Module:反卷积+4个Residual Blocks对反卷积结果进行refine。输入是上一个stage的feature map+对应的heatmap。
4.Multi-Resolution Supervision:多尺度监督训练
为每个尺度建立一个GT heatmap,每个尺度都计算一个均方差loss,然后把所有尺度下的loss相加作为最终的loss,进行训练。可以有效提高各个尺度关节预测的准确性。
tag只对1/4尺度训练,因为作者发现其他尺度下,无法收敛且效果不好。
5.Heatmap Aggregation for Inference推理阶段的热图整合:
将所有尺度下的预测heatmap和tag通过双线性差值法恢复到原图尺度,然后pixel-wise相加求平均。这样可以使得部分在low-resolution中丢失的关节点在high-resolution中恢复。---提高对小人物的检测效果
关联嵌入
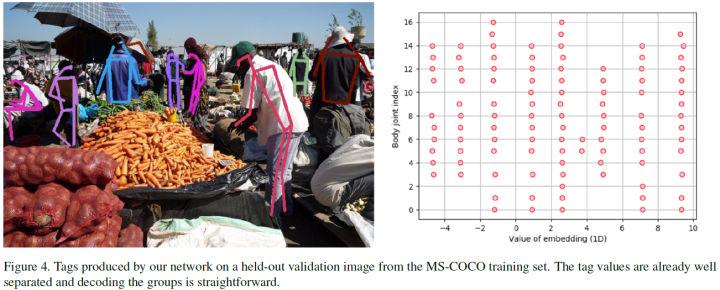
重点在于associate embedding的tag图和loss计算
tag图每个位置的值定义为embedding
1.AE层:增加用于对每个关键点分组的一层,如果k个关节点则有k个tag图
实现关节点+group的端到端训练
2.loss解析:
预测一个tag图,和heatmaps大小一致,位置对应
关节点GT+tag计算出所有关节点embedding的均值h
每个关节embedding与h计算均方差+不同个体h之间的(均方差)高斯下降函数,作为loss
最小化该loss可以使得个体内每个关节tag图的embedding值趋于一致,不同个体的embedding相差较远,实现分组
实例分割的运用
loss计算时,不计算所有pixel,只是在每个实例(GT)中随机选择一部分位置,由这些位置的tag(Pre)进行loss计算,同pose estimate一致。
猜测是因为随机采样位置计算loss,导致不能很好地的对每个pixel都进行良好的学习,导致mAP很差
注意:tag的embedding并非事先固定好的标签,只要一个个体内的embedding一致即可,也就是说,每个个体对应的embedding是学习出来的
backbone:Stacked(4个) Hourglass+heatmap/tag
hourglass结构,可以充分考虑全局信息
关键点分组的一层,如果k个关节点则有k个tag图
实现关节点+group的端到端训练
HourglassNet
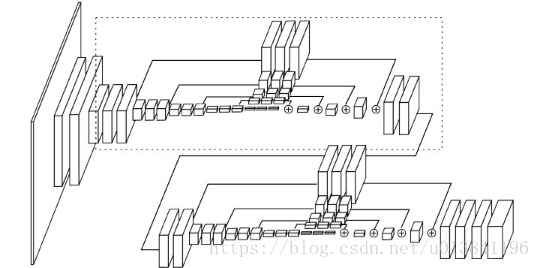
多个Hourglass拼接,可以更加充分的提取全局信息,对于关节检测这种需要考虑全局信息的任务很有意义
用于其他pose estimation结构中使得性能得到提升,尤其提高了那些难识别的关节
仍然使用了intermediate supervision,在multi-scale中中间监督很有必要
与U-Net对比
U-Net是用的concat连接+1x1卷积
Hourglass使用elem-sum逐像素添加;同时是多个hourglass的拼接,而不是单个网络。















 3011
3011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











