







一、介绍
Hallo是由复旦大学、百度公司、苏黎世联邦理工学院和南京大学的研究人员共同提出的一个AI对口型肖像图像动画技术,可基于语音音频输入来驱动生成逼真且动态的肖像图像视频。
该框架采用了基于扩散的生成模型和分层音频驱动视觉合成模块,提高了音频与视觉输出之间的同步精度。Hallo的网络架构整合了UNet去噪器、时间对齐技术和参考网络,以增强动画的质量和真实感,不仅提升了图像和视频的质量,还显著增强了唇动同步的精度,并增加了动作的多样性。
二、部署过程
环境配置基础要求:
系统:Ubuntu22.04系统,
显卡:RTX3090,
显存:24G
1.基础环境
-
查看系统是否有Miniconda3的虚拟环境
conda -V如果输入命令没有显示Conda版本号,则需要安装。

2.更新系统命令
输入下列命令将系统更新及系统缺失命令下载
apt-get update apt-get upgrade apt-get install -y vim wget unzip lsof net-tools openssh-server git git-lfs gcc cmake build-essential
3.下载模型
输入下列命令对hallo模型进行下载
git clone https://gitclone.com/github.com/fudan-generative-vision/hallo.git

4.创建虚拟Python环境
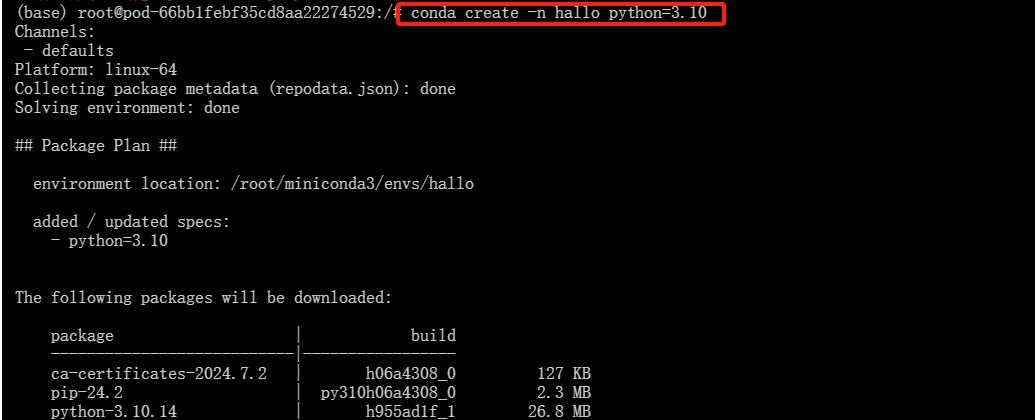
- 创建一个名为"hallo"的虚拟镜像,python版本为3.10
conda create -n hallo python=3.10
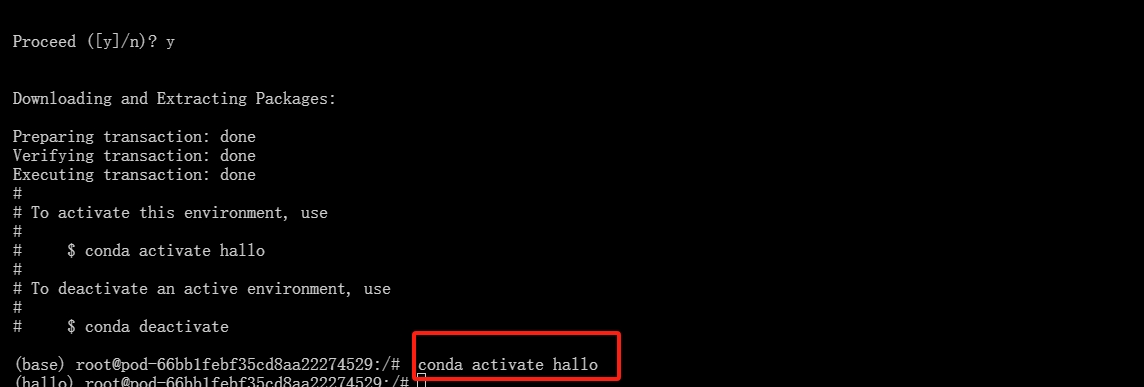
- 进入"hallo"虚拟环境
conda activate hallo
5.安装cuda118
使用下列命令下载cuda安装包:
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
运行cuda:
sh cuda_11.8.0_520.61.05_linux.run
编辑配置文件:
(1)进入文件
vim ~/.bashrc
(2)在 .bashrc添加:
export PATH="/usr/local/cuda-11.8/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH"
(3)保存并加载环境变量
source ~/.bashrc
6.下载模型依赖包
输入下列命令:
pip install -r requirements.txt
pip install .
下载ffmpeg:
apt-get install ffmpeg
(使用基础命令时已经下载过)

7.添加模型文件
输入下列命令:
git lfs install
git clone https://hf-mirror.com/fudan-generative-ai/hallo pretrained_models

8.运行推理
使用下列命令运行项目呈现模型的成功界面
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav


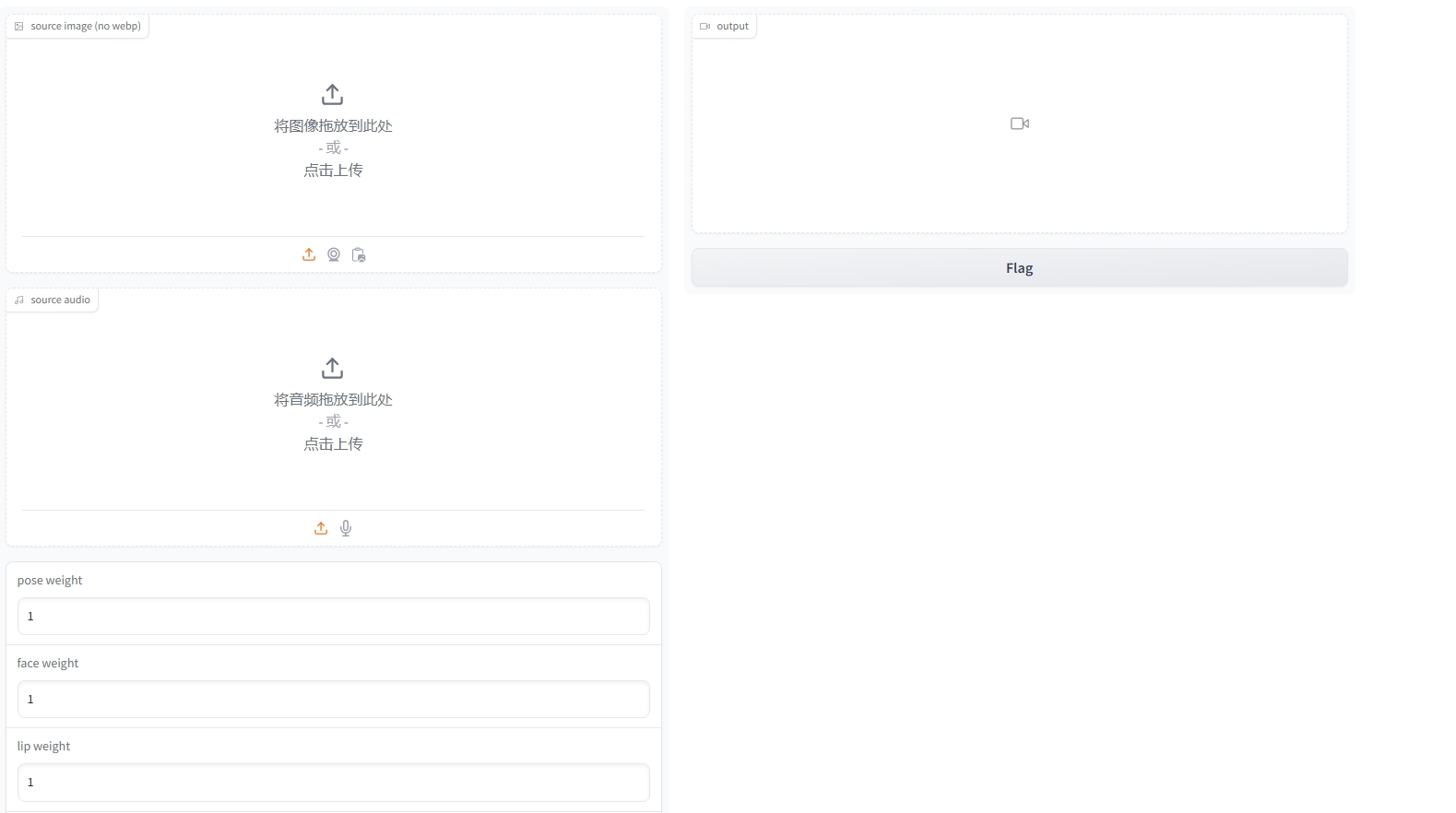
三、Web界面演示
输入下列命令启动界面:
conda activate hallo cd hallo export GRADIO_SERVER_NAME=0.0.0.0 export GRADIO_SERVER_PORT=8080 python scripts/app.py


















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









