







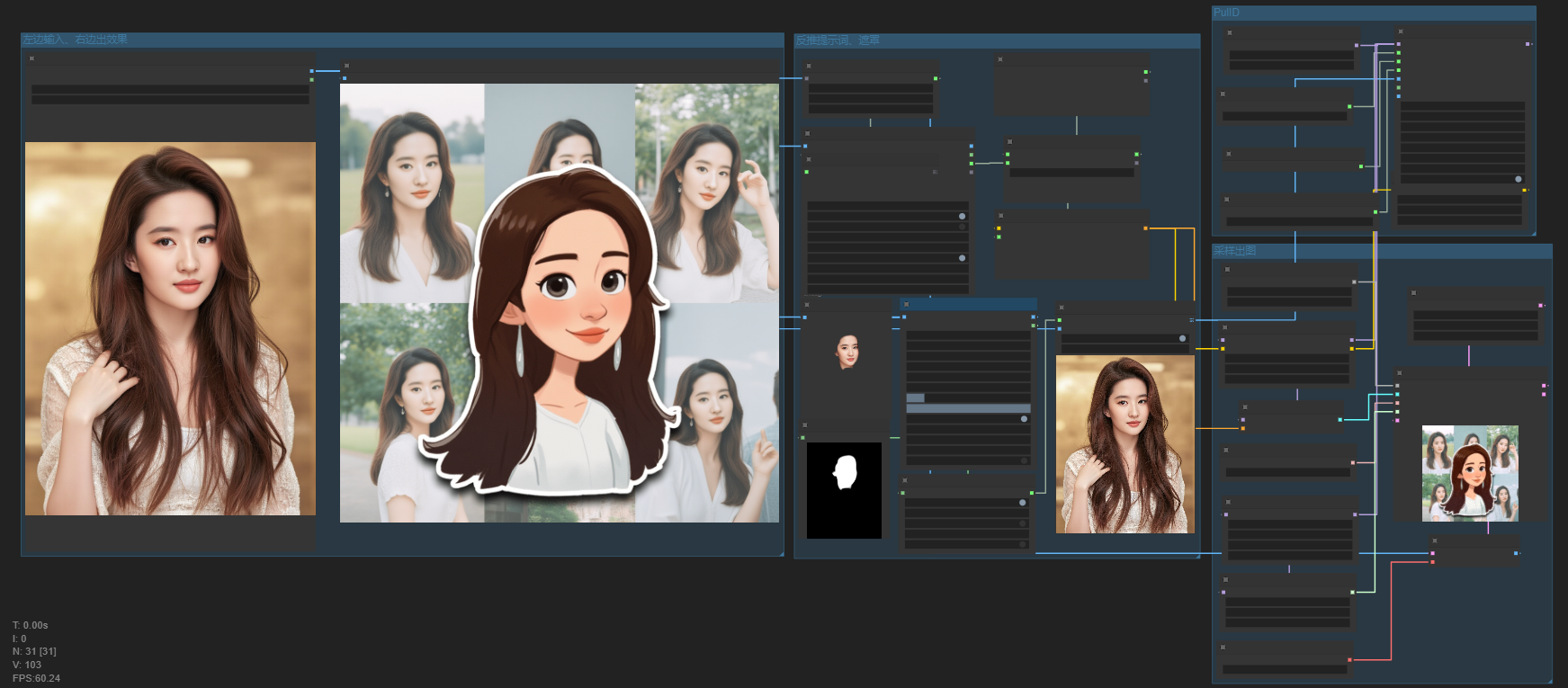
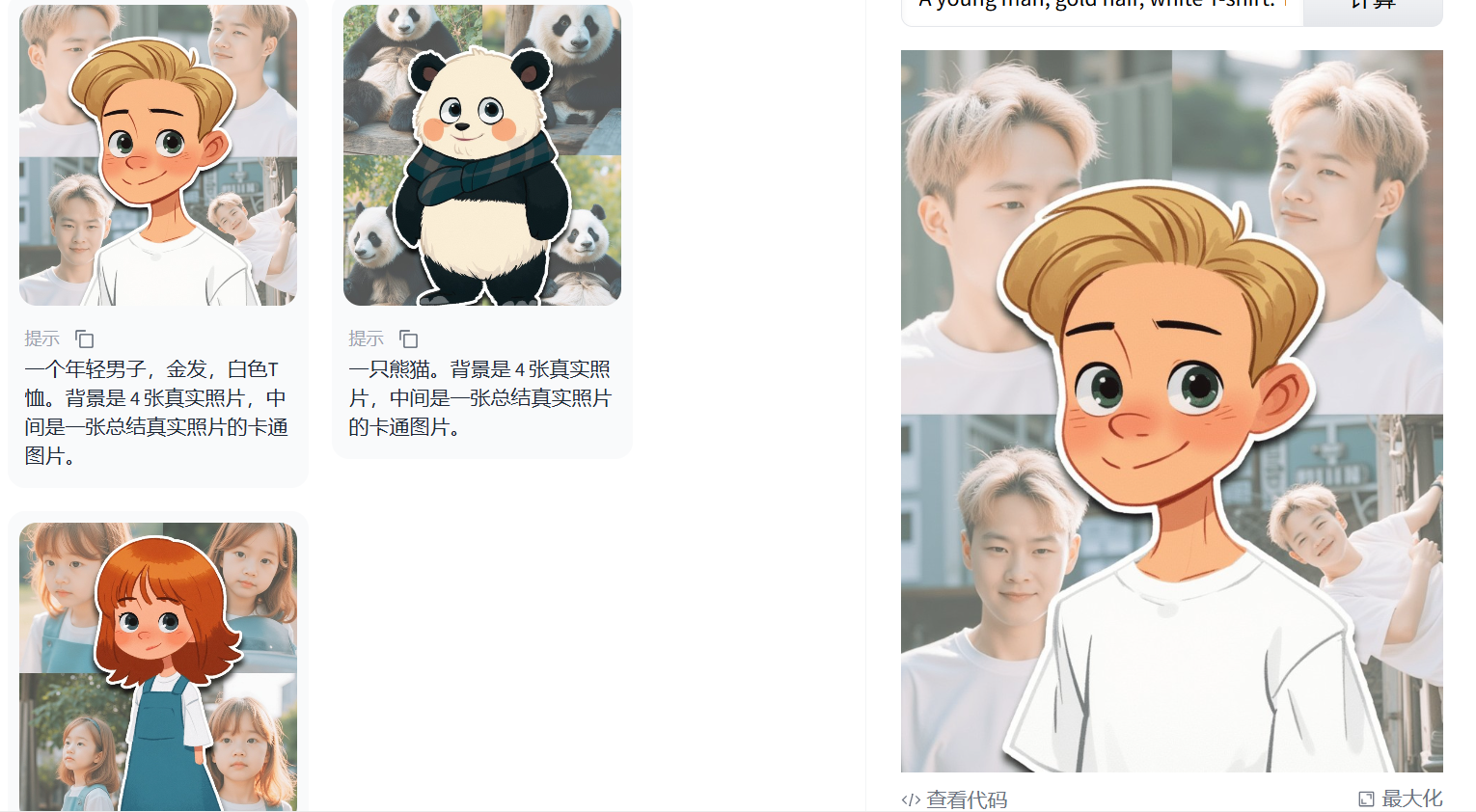
前两天发现一个比较有意思的工作流,通过一张图片可以实现创意贴纸的效果,先来看看效果图:



怎么做的呢,首先是通过Florence2进行提示词反推,然后SegmentAnything Ultra V2进行遮罩提取,通过PulID进行特征处理后结合Flux的创意贴纸lora进行出图。可以先看看工作流:
PuLlD-Flux插件安装
所需核心插件:字节跳动开源的插件“pulid-flux”

安装完成之后需要下载对应的模型:
1.Pulid_flux_v0.9.1模型
下载我们需要的Flux模型
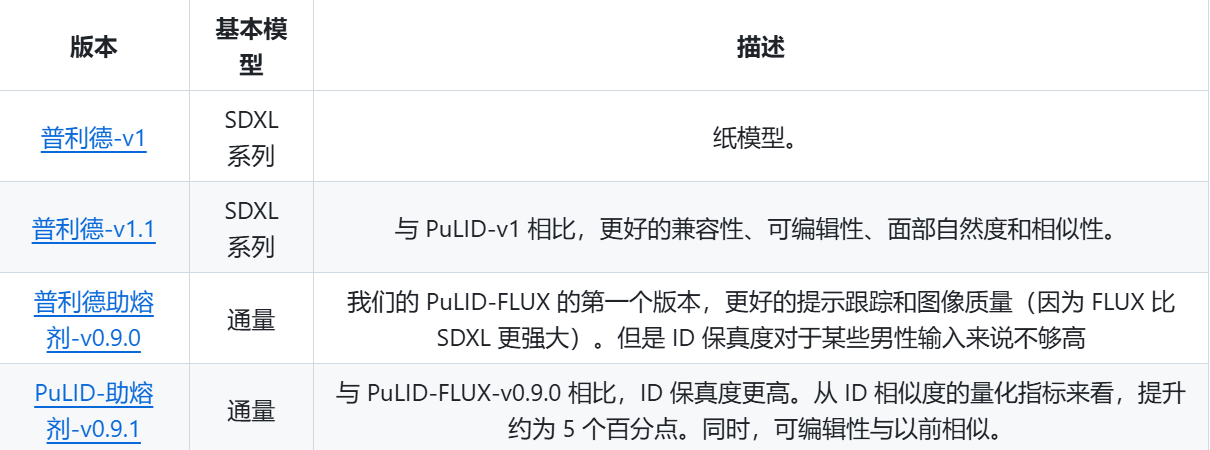
下载链接为:https://huggingface.co/guozinan/PuLID/tree/main
2.EVA Clip 节点****模型
这个节点会用到一个模型:**EVA02_CLIP_L_336_psz14_s6B.pt。**这个模型会在首次运行时自动下载到“ huggingface 缓存目录 ”(科学网络畅通),但是,很多时候是自动下载不了的。这个时候就需要我们手动下载了:
下载链接:https://huggingface.co/QuanSun/EVA-CLIP/tree/main
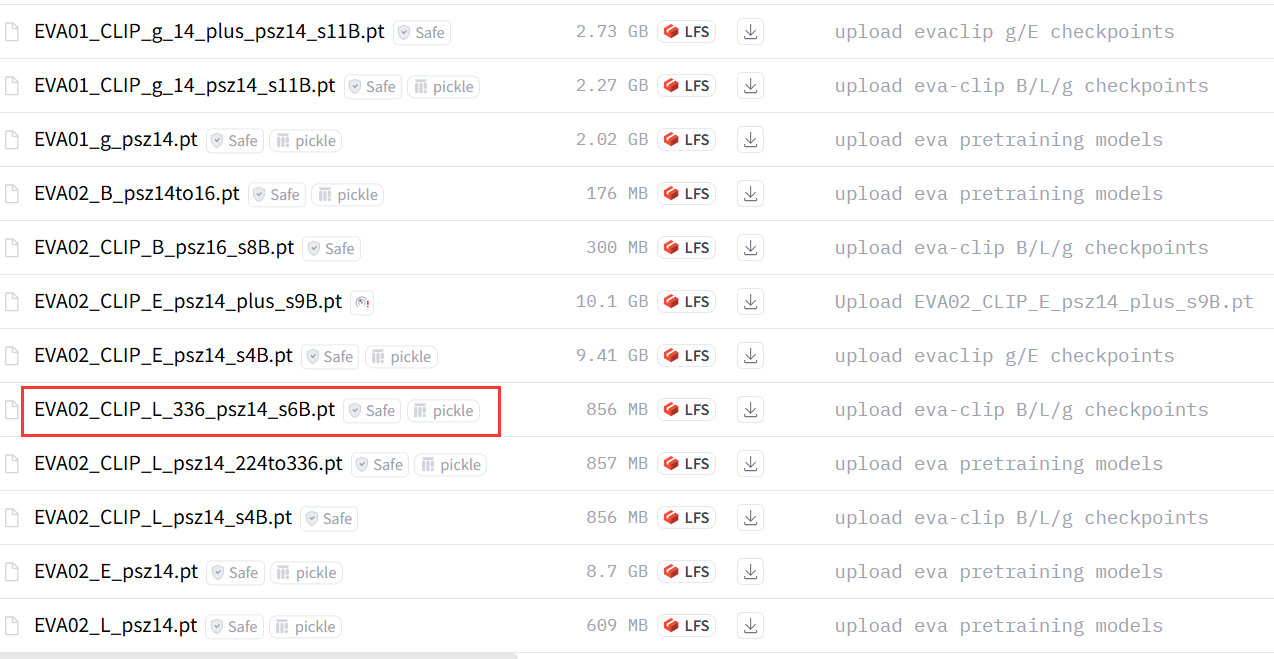
下载之后放置到 /root/.cache/huggingface/hub/models--QuanSun--EVA-CLIP/snapshots/11afd202f2ae80869d6cef18b1ec775e79bd8d12/这个路径下,然后还需要在 /root/.cache/huggingface/hub/models--QuanSun--EVA-CLIP/snapshots/refs/main文件中(没有就自己创建)写入:11afd202f2ae80869d6cef18b1ec775e79bd8d12并保存。
3.其它小模型
通常也会在首次运行时自动下载,但是如果因为网络原因无法下载的情况下也需要手动下载。
下载链接:https://github.com/xinntao/facexlib/releases/v0.2.0/将下面几个模型全部进行下载

然后放置到:/root/miniconda3/envs/comfyui/lib/python3.10/site-packages/facexlib/weights/路径下
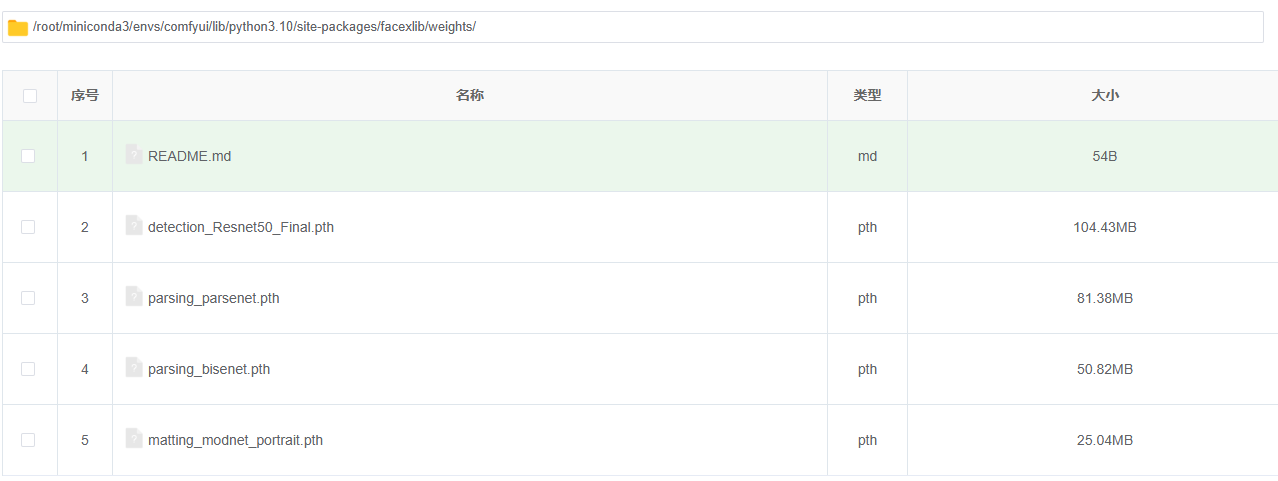
全部下载完成后PuLID-Flux插件才算是安装成功了
工作流解析
1.反推提示词
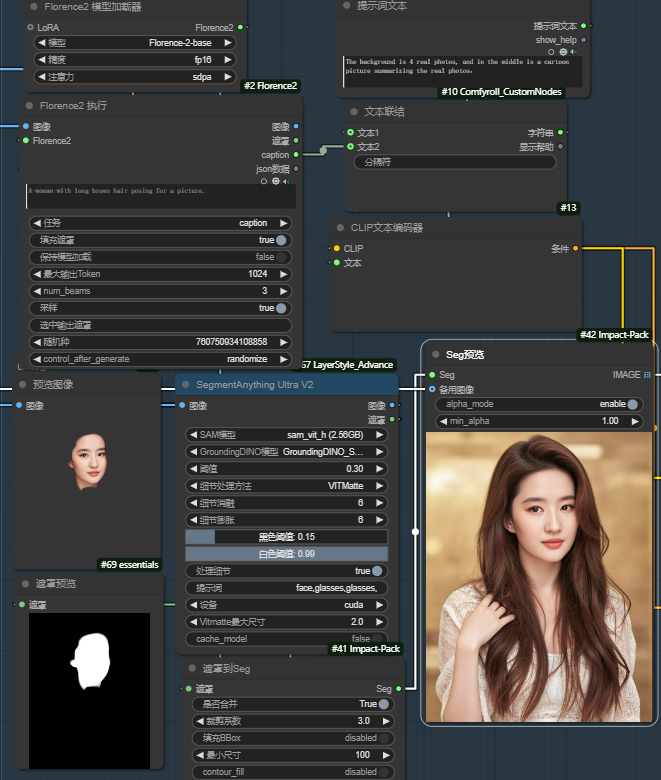
本部分首先通过加载的图片利用Florence2节点反推提示词,在这里需要注意的是Florence2节点的任务选择,选择caption就好,大概反推一下就可以了,如果反推太仔细会影响最好出图效果。反推之后需要将结果接入到“文本联结”,然后文本联结还需要一个输入,这个我们通过提示词文本输入我们想要出图的效果:
The background is 4 real photos, and in the middle is a cartoon picture summarizing the real photos
如果只生成卡通人物,提示词:
Cartoon images of real photos
2.遮罩
遮罩提取有多种方法可以使用"segformer UItra v2"、"segmentanything UItra v2"等节点进行实现,这里我使用segmentanything节点并使用sam_vit_h(2.56)进行处理。
我将两者进行了对比,左边是"segformer UItra v2",右边是"segmentanything UItra v2"分别测试了对脸和上衣的遮罩提取,能够看出虽然服装框架的使用虽然要简便一点,但确实还是使用sam_vit_h(2.56)进行处理的效果要更胜一筹:
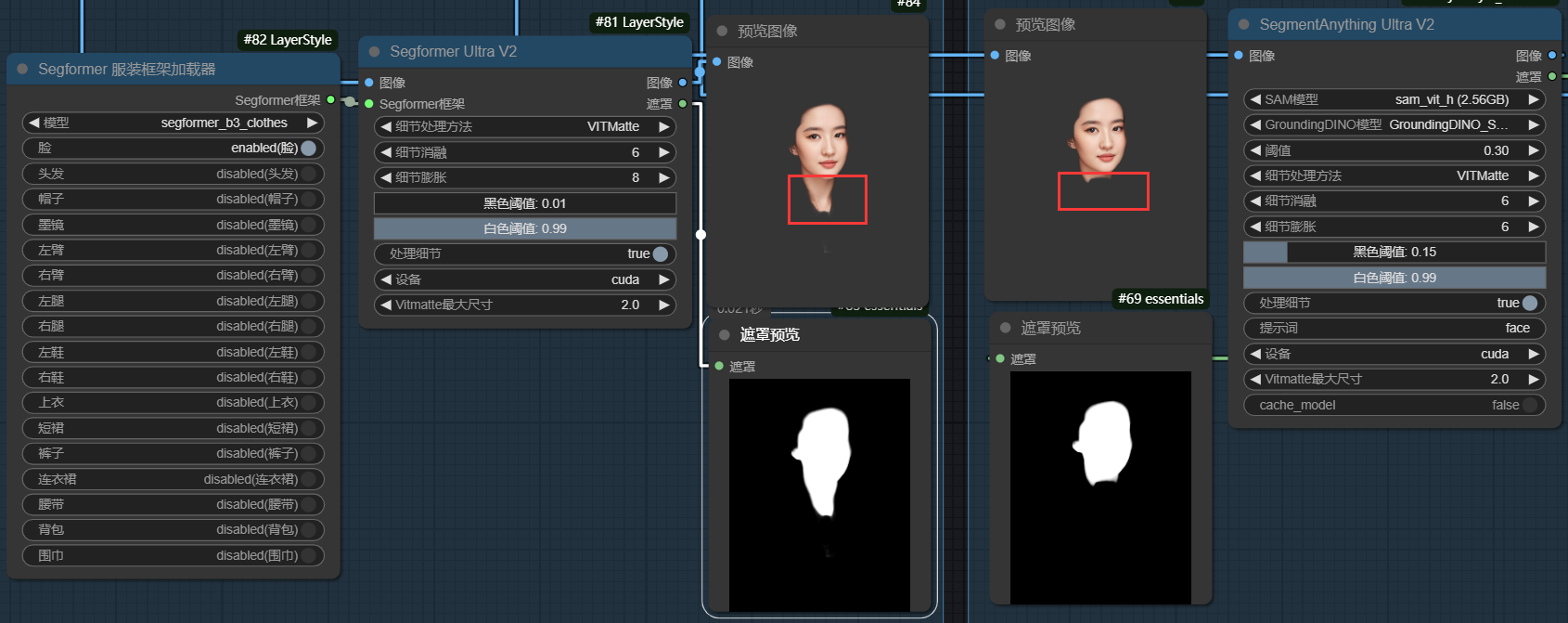
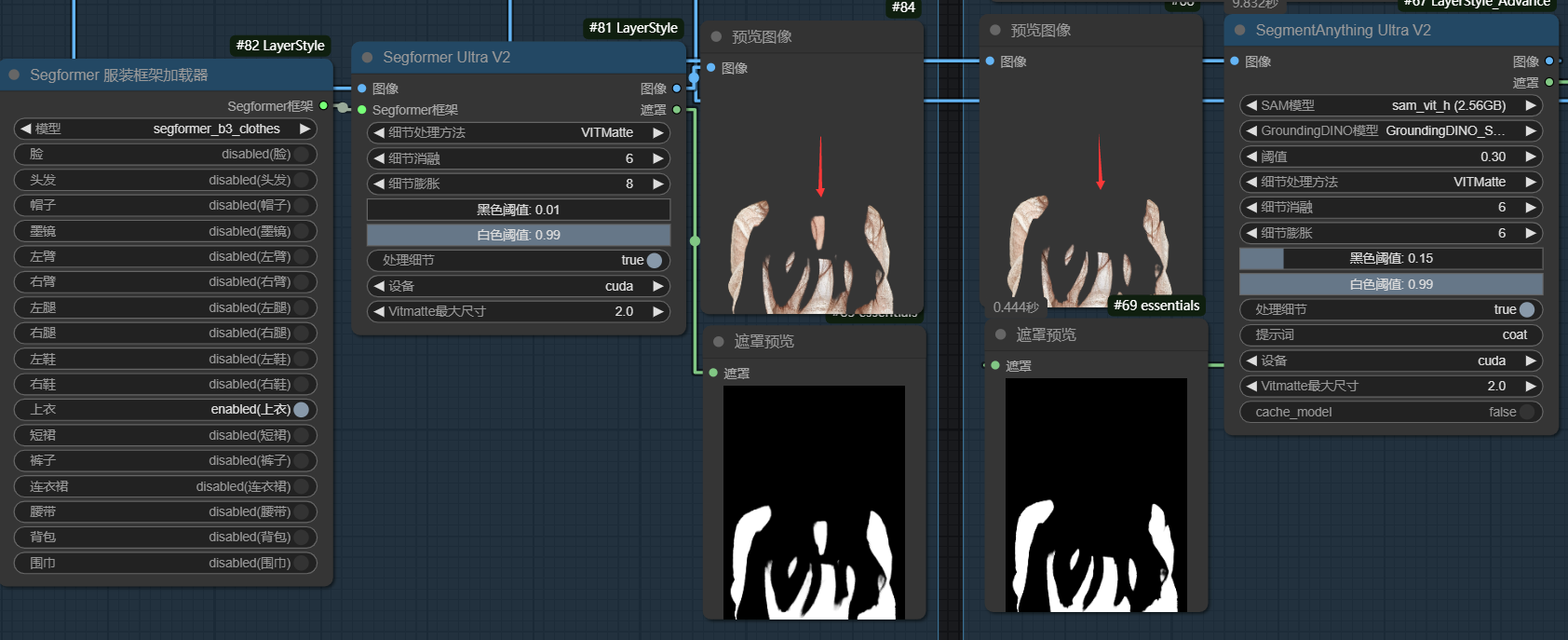
其中,“遮罩到Seg”节点的作用是将上一步提取的遮罩信息进行标准化(遮罩信息是模型对原图的原始分割结果,seg信息是更通用的或符合预期的数据格式)。通过该节点有以下作用:
(1)数据格式转换。(2)遮罩优化:优化边缘细节。修正分割区域的不规则性。处理透明度(Alpha)信息。(3)增强灵活性:不同任务可能对分割结果有不同要求,通过“遮罩到 Seg”节点,可以更方便地调整参数(如细节水平、透明度阈值),而不用直接修改“SegmentAnything Ultra V2”中的设置。节点中的相关参数如下:
| 参数 | 功能 | 常用场景 |
|---|---|---|
| 是否合并 | 合并多个遮罩为一个整体遮罩 | 多个目标分割后需要作为统一区域处理时(如统一应用透明度)。 |
| 裁剪系数 | 调整遮罩区域的边界大小 | 缩小边界去除噪点,或者扩大边界获取更多背景时。 |
| 填充 BBox | 使用矩形框填充遮罩区域 | 输出整齐的矩形遮罩框,用于目标检测或其他需要矩形框的应用。 |
| 最小尺寸 | 过滤掉小于设定尺寸的遮罩区域 | 删除无关紧要的小噪点或小遮罩,只保留主要目标。 |
| contour_fill | 填充或平滑遮罩边界,修复孔洞或不连续的区域 | 需要生成更平滑或完整的分割结果时,特别是对复杂的对象分割。 |
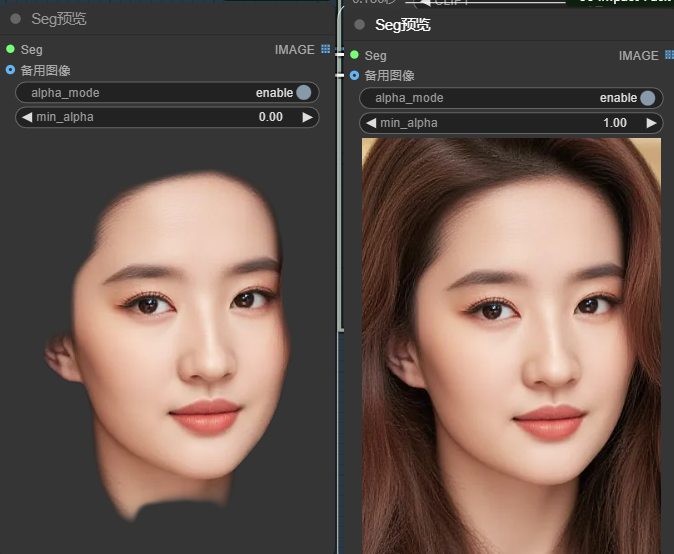
此外还有“seg预览”节点。此节点是将seg信息转化为图片信息作为预览和后面节点的输入,此节点的“备用图像”输入仅用于遮罩和原图对比显示,“min_alpha”数值越接近0原图显示越淡,反之越接近原图。
3.PuLID-FLux(换脸插件)
这是字节跳动开源的换脸项目,最先是在SDXL上进行支持,2024年9月12日发布在FLux上支持的模型PuLID-FLUX-v0.9.0。本部分的核心是四个节点,如下图:
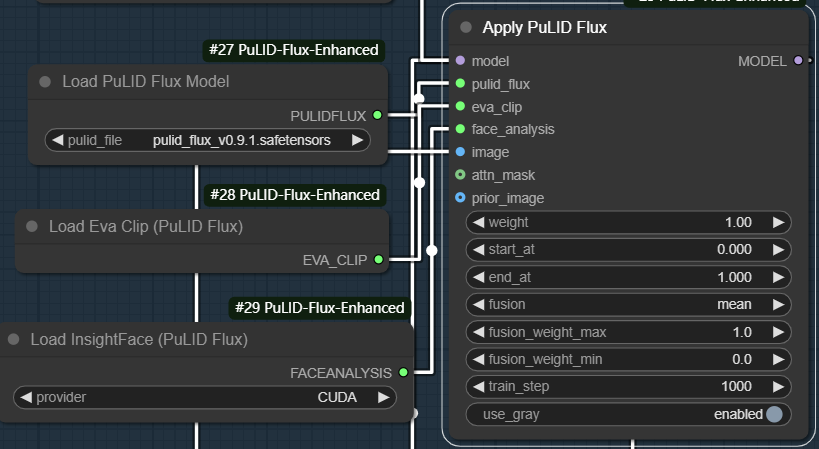
对于“Apply PuLID Flux”节点,值得提一嘴的是“attn_mask”和“prior_image”两个输入项。“attn_mask”是指注意力遮罩,用于指示图像中的哪些区域需要被特别关注或处理。“prior_image”是先验图像,pulid-flux会参考这张图片的特征,包括人脸特征和姿势等,如果对生成的图片有特殊要求的时候就可以将参考图片接入这里。
4.采样出图
这部分就比较常规了,没什么好讲的,只是这里有一个lora模型,也是整个工作流的灵魂:Shakker-Labs/FLUX.1-dev-LoRA-One-Click-Creative-Template。
下载地址:https://hf-mirror.com/Shakker-Labs/FLUX.1-dev-LoRA-One-Click-Creative-Template
工作流:
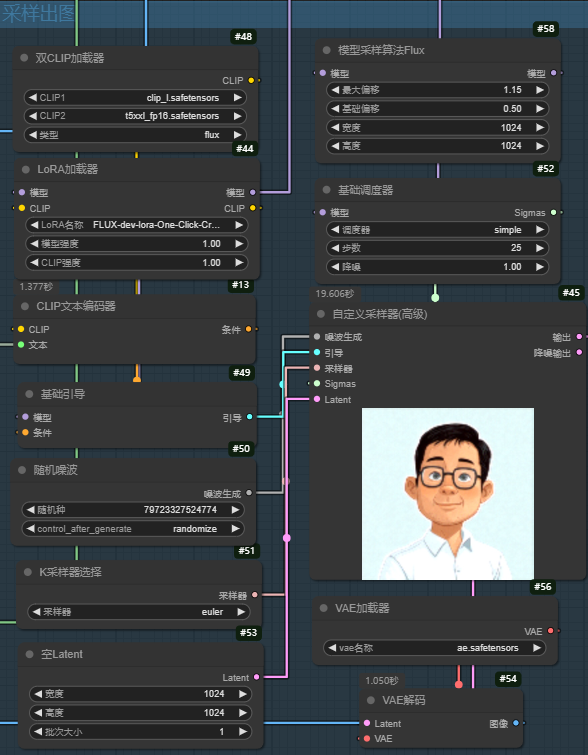
只需按照常规方法进行连接即可生图了。


















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









