







一、介绍
Fish-Speech是由Fish Audio团队开发的一款开源文本转语音(TTS)模型,它基于VQ-GAN、Llama和VITS等技术开发,采用了Transformer架构,这是一种在自然语言处理任务中表现卓越的神经网络结构。同时,它还使用了多任务学习方法和先进的神经网络声码器,以实现高质量的语音合成。Fish-Speech支持包括中文在内的多种主流语言,使得用户在跨文化交流中能够自如地表达自己。仅需15秒的音频样本,Fish-Speech便能迅速实现声音克隆,生成与目标声音高度相似的语音。
二、部署流程
环境推荐配置
系统:Ubuntu22.04,
显卡:4090,
显存:24G,cuda12.1
1. 基础环境
查看系统是否有Miniconda3的虚拟环境
conda -V
如果输入命令没有显示Conda版本号,则需要安装。

2.更新系统命令
输入下列命令将系统更新及系统下载
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y

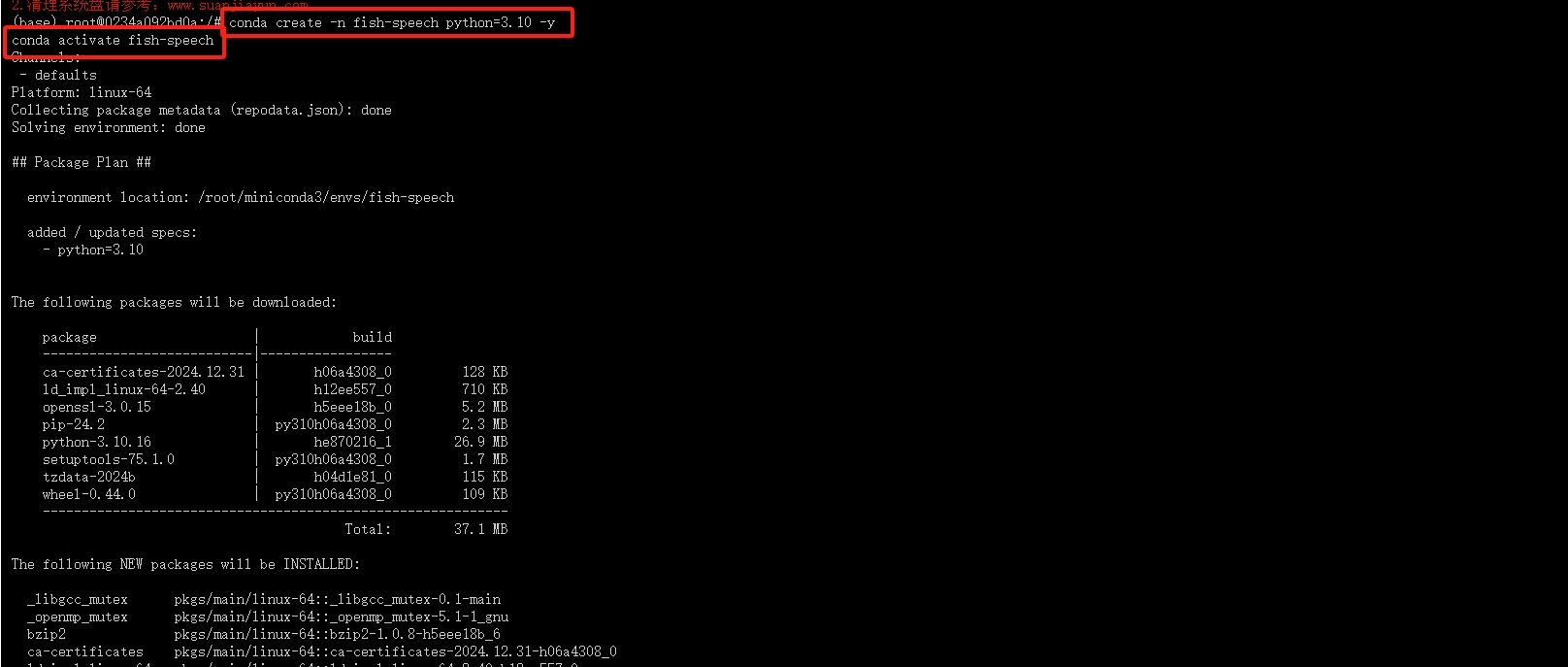
3.创建虚拟环境
创建名称为“Fish-Speech”的虚拟环境并激活
conda create -n Fish-Speech python==3.8 -y
conda activate fish-speech
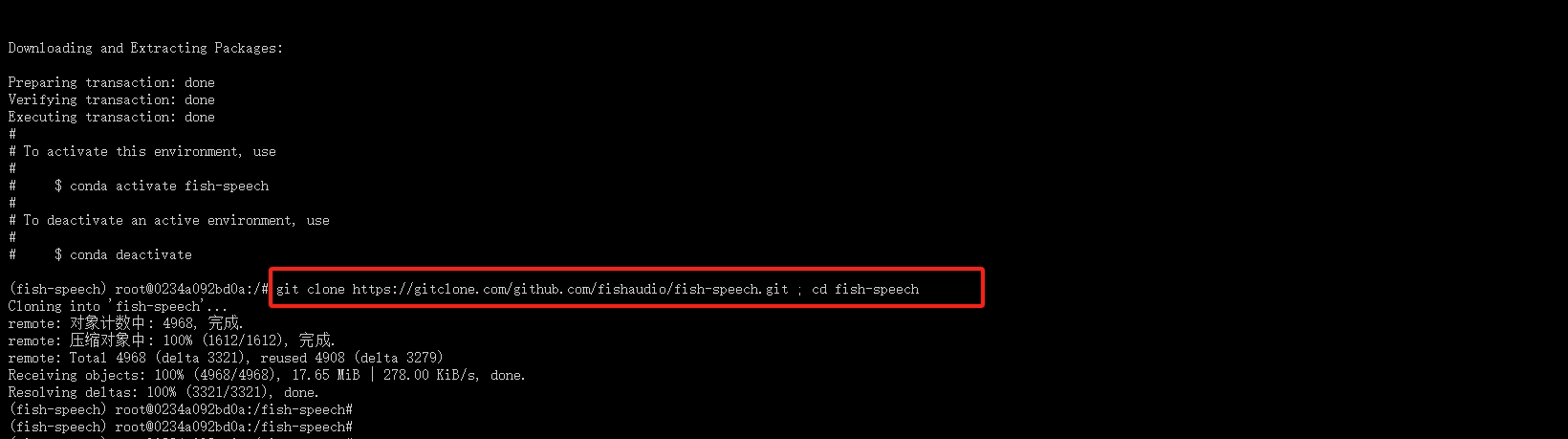
4.下载模型
输入下列命令下载fish-speech模型同时进入项目中
git clone https://gitclone.com/github.com/fishaudio/fish-speech.git ; cd fish-speech
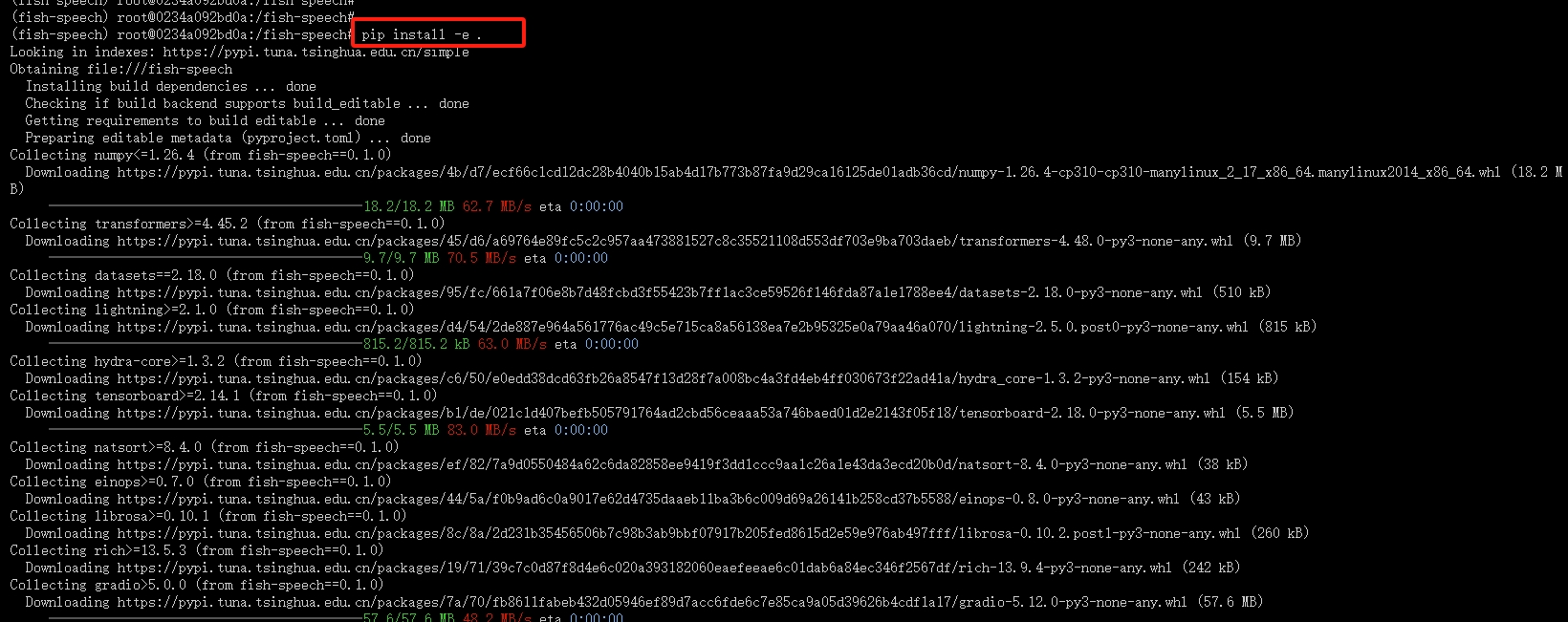
5.下载模型依赖包
输入下列命令:
pip install -e.
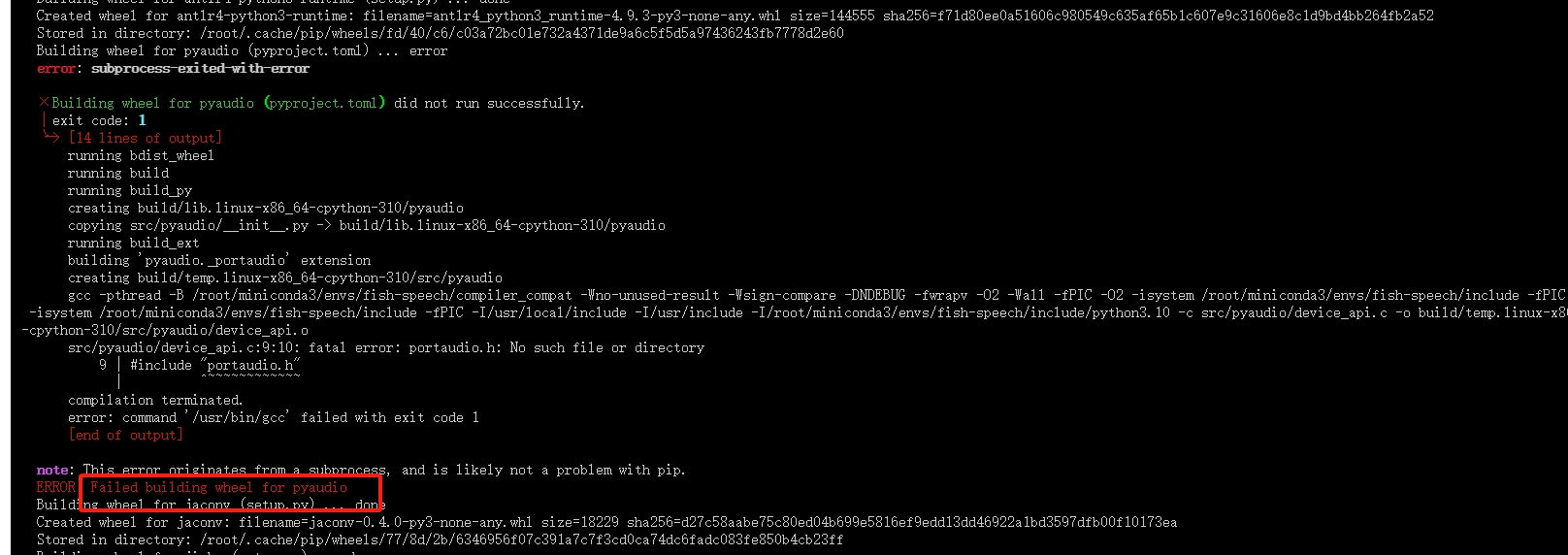
此时报错:
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (pyaudio)
复制下列命令解决:
apt-get install portaudio19-dev
再次使用pip install -e.命令继续下载其他的依赖包
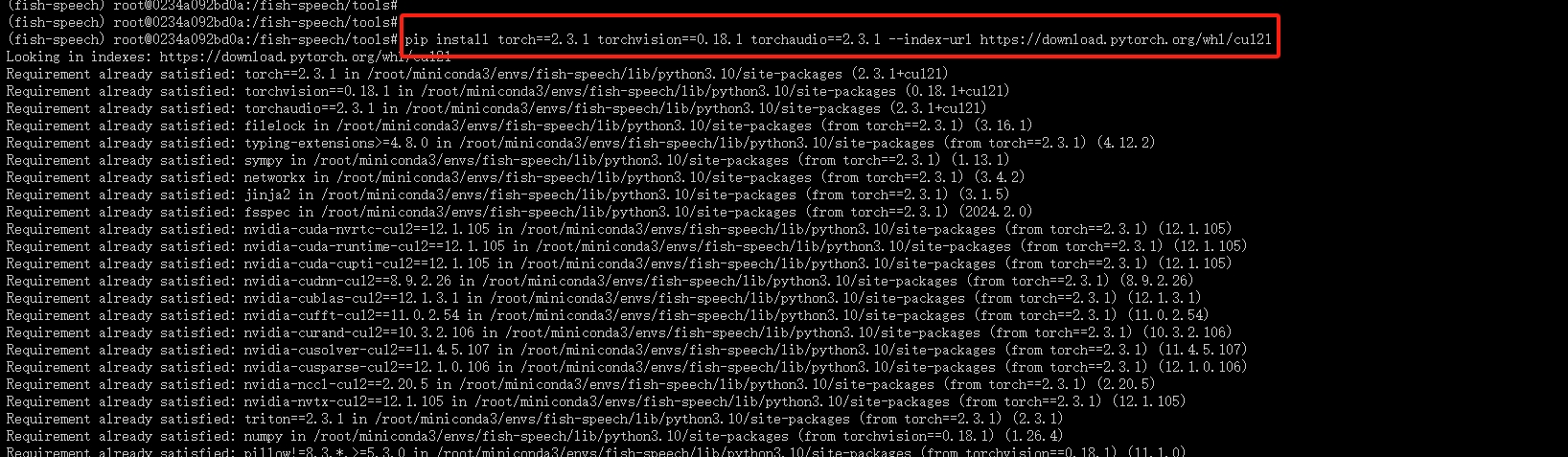
6.重新下载Pytorch
复制下列命令进行下载:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121
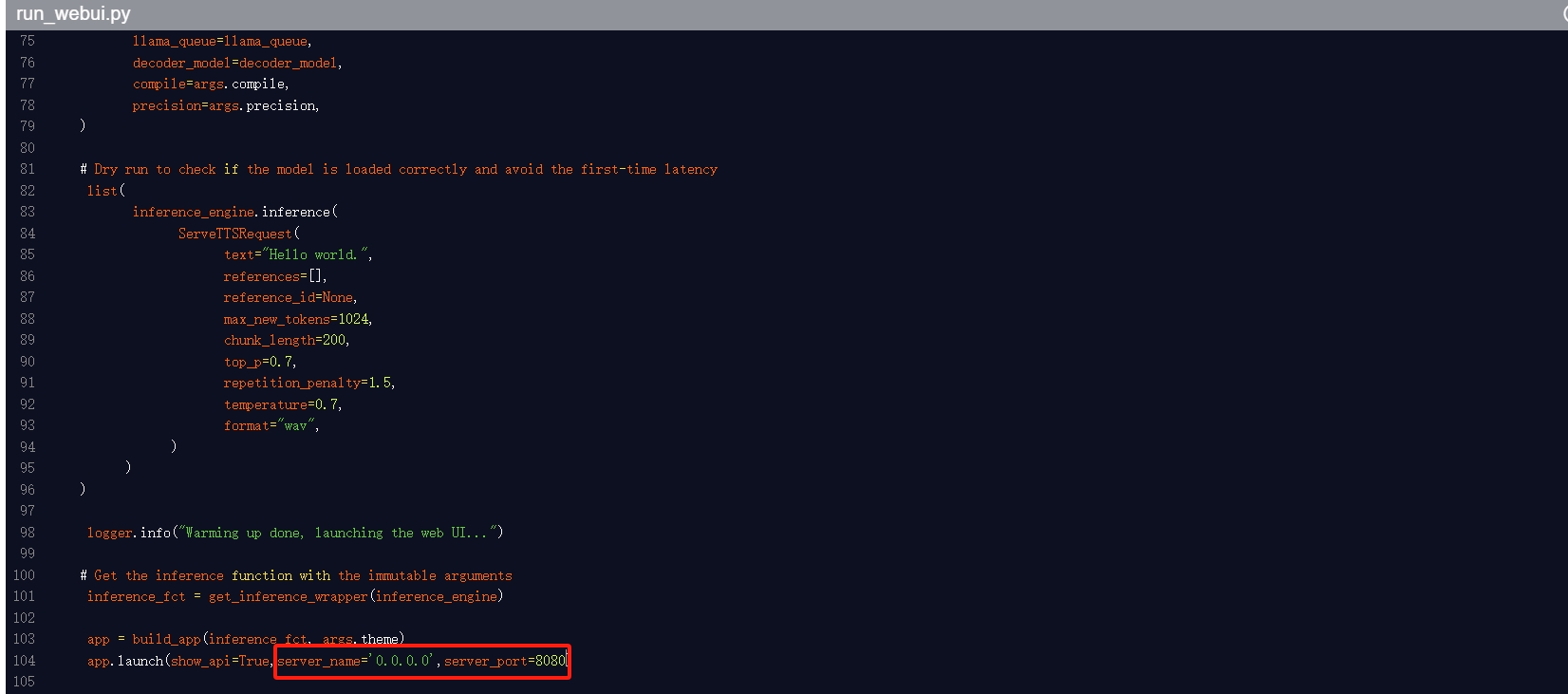
7.更改网址和端口
进入“/fish-speech/tools/”文件目录下,在run_webui.py文件最后一行添加下列代码:
server_name='0.0.0.0',server_port=8080
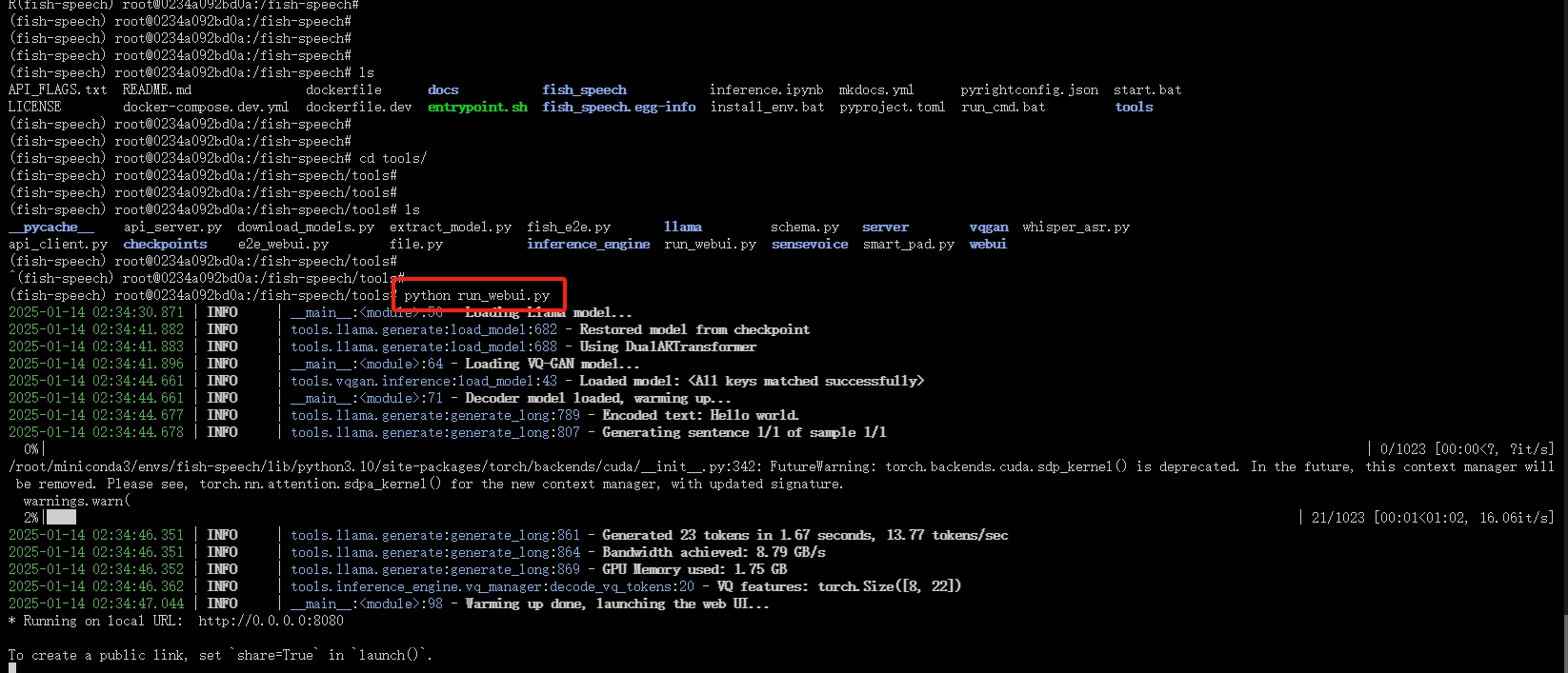
三、网页演示(启动程序)
复制下列命令运行项目呈现模型的成功界面
cd toolss
python run_webui.py
打开网址:
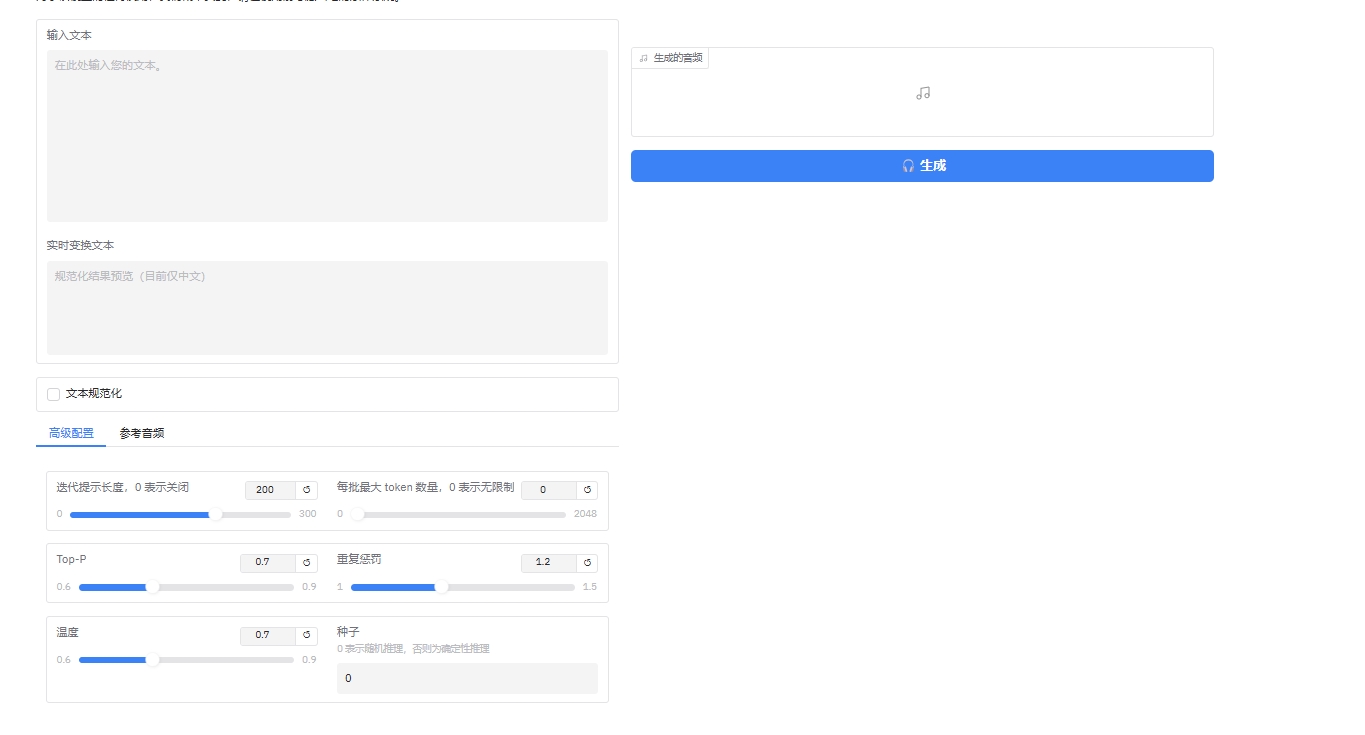


















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









