









1.ReduceLROnPlateau
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode, factor, patience, verbose, threshold, threshold_mode,cooldown, min_lr, eps=)
当模型的指标停止增加的时候,可以适当降低LR,在Patience时间内模型没有改进的时候,LR会降低。
optimizer - 网络的优化器
mode - default ‘min’
‘min’ - 监控量停止下降的时候,学习率将减小
‘max’ - 监控量停止上升的时候,学习率将减小 为’min’
factor - 学习率每次降低倍数,new_lr = old_lr * factor
patience - 容忍网路的性能不提升的次数,高于这个次数就降低学习率
verbose - True,则为每次更新向stdout输出一条消息。 default False
threshold - 测量新最佳值的阈值,仅关注重大变化。 default 1e-4
cooldown - 减少lr后恢复正常操作之前要等待的时期数。 default 0。
min_lr - 学习率的下限
eps - 适用于lr的最小衰减。 如果新旧lr之间的差异小于eps,则忽略更新。 default 1e-8。
2.CosineAnnealingWarmRestarts
一个周期性的余弦下降策略。每经过T0次重启一下。
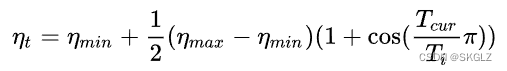
T0:重启周期
Tmult:T_0增加的因子,每次重启之后周期增加。
etamin:LR的最小值。
3.StepLR
规定了一个特殊的LambdaLR方式,每step_size步之后衰减gamma。多个参数组共用Step_size和gamma,同时Step_size固定。
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
引用补充:https://www.jianshu.com/p/424d9a1e5ced
使用SGD时注意结合monument,一般大学习率加大动量,结合reduce或者余弦优化















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









