






 CENET提出了一种新的事件预测模型,利用历史对比学习区分历史和非历史实体,有效处理缺乏历史交互的实体,尤其在新事件预测上表现出色,相较于现有方法在多个数据集上实现显著性能提升。
CENET提出了一种新的事件预测模型,利用历史对比学习区分历史和非历史实体,有效处理缺乏历史交互的实体,尤其在新事件预测上表现出色,相较于现有方法在多个数据集上实现显著性能提升。
AAAI Conference on Artificial Intelligence (AAAI-23)
Abstract
Temporal knowledge graph, serving as an effective way to store and model dynamic relations, shows promising prospects in event forecasting. However, most temporal knowledge graph reasoning methods are highly dependent on the recurrence or periodicity of events, which brings challenges to inferring future events related to entities that lack historical interaction. In fact, the current moment is often the combined effect of a small part of historical information and those unobserved underlying factors. To this end, we pro pose a new event forecasting model called Contrastive Event Network (CENET), based on a novel training framework of historical contrastive learning. CENET learns both the his torical and non-historical dependency to distinguish the most potential entities that can best match the given query. Simultaneously, it trains representations of queries to investigate whether the current moment depends more on historical or non-historical events by launching contrastive learning. The representations further help train a binary classifer whose output is a boolean mask to indicate related entities in the search space. During the inference process, CENET employs a mask-based strategy to generate the fnal results. We evaluate our proposed model on fve benchmark graphs. The results demonstrate that CENET signifcantly outperforms all exist ing methods in most metrics, achieving at least 8.3% relative improvement of Hits@1 over previous state-of-the-art base lines on event-based datasets.
时间知识图谱在事件预测方面展现出巨大的潜力,它有效地存储和模拟动态关系。但是,现有的时间知识图谱推理方法通常需要事件具有一定的周期性或重复性,这对于那些没有历史交互记录的实体未来事件的预测提出了挑战。因为很多时候,当前的情况是历史信息和一些未被察觉的深层次因素共同作用的结果。针对这个问题,我们提出了一个基于历史对比学习的新模型——Contrastive Event Network (CENET)。CENET能够学习到事件的历史和非历史依赖关系,从而判断哪些实体最有可能与特定查询相匹配。此外,它还通过对比学习训练查询的表示,来分析当前情况是更受历史事件影响还是非历史事件影响。这些表示还用于训练一个二进制分类器,它的作用是在搜索空间中标记出相关实体。在预测阶段,CENET利用基于掩码的策略来得出最终预测。我们的模型在五个基准数据集上进行了测试,结果表明,CENET在多数评估指标上远超现有方法,尤其在基于事件的数据集上,相比之前的最优模型,其在Hits@1指标上至少提高了8.3%。
1 Introduction
知识图谱(KGs)作为人类知识的集合,在自然语言处理(Sun等人,2020;Wang等人,2021)、推荐系统(Wang等人,2019)和信息检索(Liu等人,2018)等领域展现出了有希望的前景。传统的KG通常是一个静态的知识库,它使用图形结构的数据拓扑来整合事实(也称为事件),这些事实以三元组(s, p, o)的形式存在,其中s和o分别代表主体和客体实体,p作为关系类型表示谓词。在现实世界中,知识不断演变,这启发人们构建和应用时间知识图谱(TKGs),其中事实从三元组(s, p, o)扩展到了带有时间戳t的四元组,即(s, p, o, t)。因此,TKG由多个快照组成,同一快照中的事实是共存的。图1(a)展示了一个由一系列国际政治事件组成的TKG的例子,其中一些事件可能会重复发生,同时也会出现新的事件。
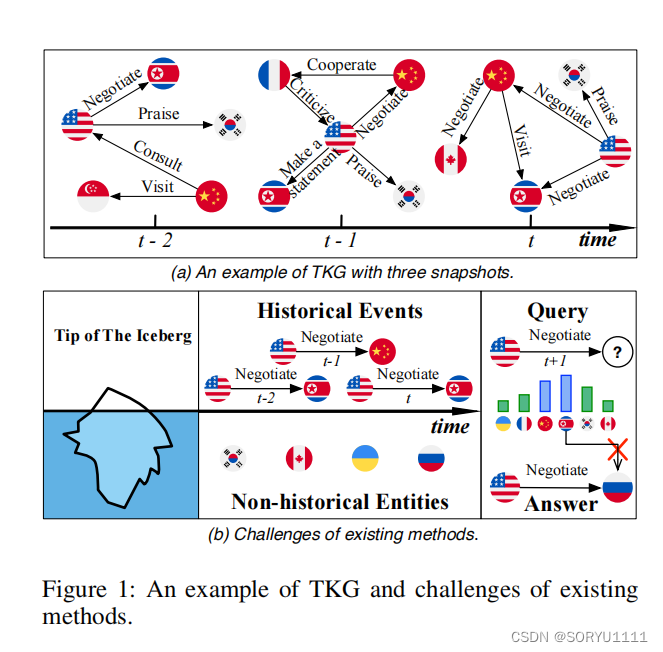
时间知识图谱(TKGs)为众多应用领域提供了新视角和新见解,包括政策制定、股票预测和对话系统等(Deng, Rangwala, 和 Ning 2020;Feng等人,2019;Jia等人,2018),这也使得对时间知识图谱推理的研究变得非常热门。本研究聚焦于在时间知识图谱上预测未来事件(事实),这一过程通常被称为图的外推。我们的目标是预测未来时间戳t(在训练集中未观察到)的查询(如(s, p, ?, t))中缺失的实体。
许多努力(Garcia-Duran, Dumanˇci´c和Niepert 2018; Jin等 2020)已经投入到建模时态知识图谱(TKGs)的结构和时态特征,以便预测未来事件。一些主流的例子(Jin等 2020; Li等 2021b)参考历史上的已知事件,这样可以容易地预测重复性或周期性的事件。
然而,在基于事件的时态知识图谱综合危机预警系统中,从未发生过的新事件约占40%(Boschee等,2015)。推断这些新事件是具有挑战性的,因为它们在整个时间线上具有较少的时态交互痕迹。例如,图1(b)的右侧部分显示了查询(美国,谈判,?,t+1)及其对应的新事件(美国,谈判,俄罗斯,t+1),大多数现有方法往往由于专注于高频率的循环事件而获得此类查询的错误结果。此外,在推理过程中,现有方法在整体图中对所有候选实体的概率得分进行排序,而没有任何偏差。我们认为,在接近不同事件的缺失实体时,偏差是必要的。对于重复性或周期性事件,模型应优先考虑几个频繁出现的实体,而对于新事件,模型应更多地关注历史交互较少的实体。
The contributions of our paper are summarized as follows:
我们提出了一种名为CENET的时态知识图谱模型,用于事件预测。CENET不仅可以预测重复性和周期性事件,还可以通过联合调查历史和非历史信息来预测潜在的新事件;
据我们所知,CENET是第一个将对比学习应用于时态知识图谱推理的模型,它通过训练查询的对比表示来识别高度相关的实体;
我们在五个公开的基准图上进行了实验。结果显示,CENET在事件预测任务上优于现有的时态知识图谱模型。
2 Related Work
2.1 Temporal Knowledge Graph Reasoning(时间知识图谱推理)
时态知识图谱推理有两种不同的设置:内插(interpolation)和外推(extrapolation)(Jin等 2020)。给定一个时间戳从t0到tn的时态知识图谱,具有内插设置的模型旨在完成发生在区间[t0, tn]内的缺失事件,这也可以称为TKG补全。相比之下,外推设置旨在预测给定时间tn之后可能发生的事件,即推断给定查询q = (s, p, ?, t)(或(?, p, o, t))中的实体o(或s),其中t > tn。
在前一种情况下的模型,如HyTE(Dasgupta, Ray和Talukdar 2018)、TeMP(Wu等 2020)和ChronoR(Sadeghian等 2021),被设计用于推断观察数据内的缺失关系。然而,这类模型并不是为了预测指定时间间隔之外的未来事件。在后一种情况下,各种方法被设计用于预测未来事件的目的。Know-Evolve(Trivedi等 2017)是第一个学习非线性演化实体嵌入的模型,但无法捕捉长期依赖性。xERTE(Han等 2020)和TLogic(Liu等 2022)提供了可以解释预测的可理解证据,但它们的应用场景有限。TANGO(Han等 2021)采用神经普通微分方程来模型时态知识图谱。在CyGNet(Zhu等 2021)中,采用了复制生成机制来识别高频率的重复事件。CluSTeR(Li等 2021a)采用强化学习设计,但其适用性仅限于基于事件的时态知识图谱。还有一些模型尝试采用GNN(Kipf和Welling 2016)或RNN架构来捕捉空间时态模式。典型的例子包括RENET(Jin等 2020)、RE-GCN(Li等 2021b)、HIP(He等 2021)和EvoKG(Park等 2022)。
3 Method
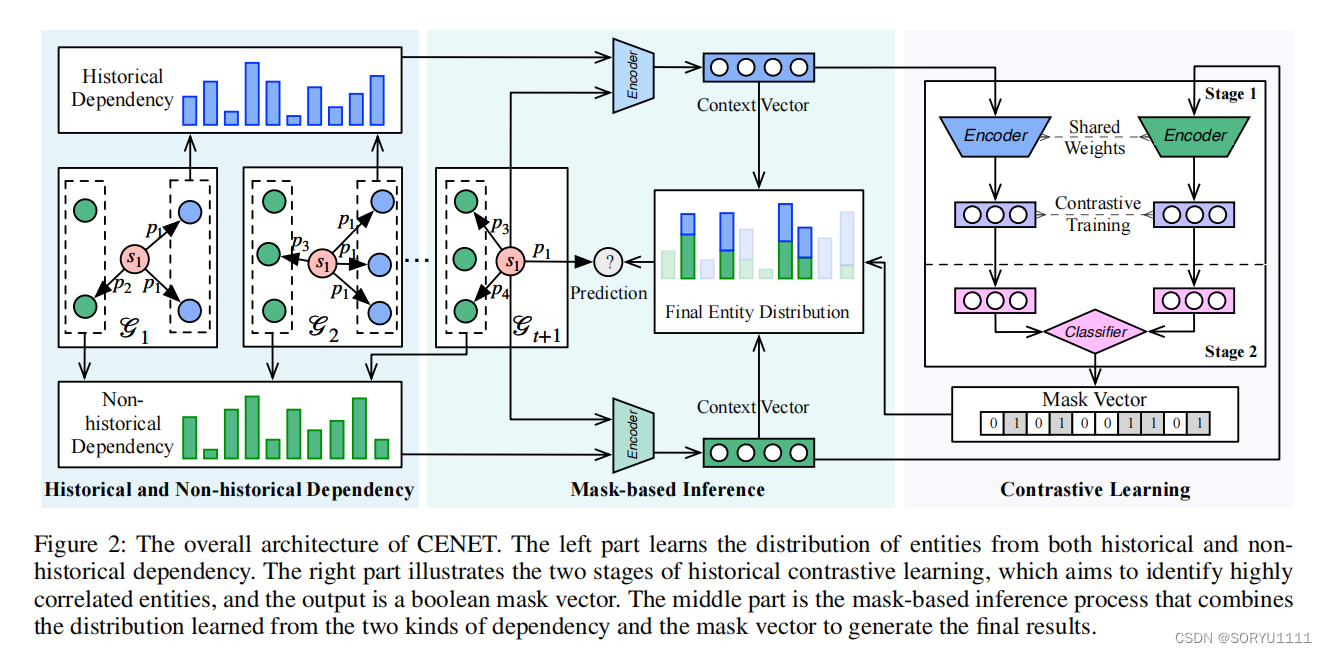
如图2所示,CENET同时捕捉历史和非历史依赖性。同时,它利用对比学习来识别高度相关的实体。进一步的,采用了基于掩码的推理过程来进行推理。在接下来的部分中,我们将详细介绍我们提出的方法。
3.1 Preliminaries
令E、R和T分别表示实体、关系类型和时间戳的有限集合。时态知识图G是由形式化为(s, p, o, t)的四元组集合,其中s ∈ E是一个主体(头)实体,o ∈ E是一个客体(尾)实体,p ∈ R是在时间戳t发生于s和o之间的关系(谓词)。**Gt代表一个时态知识图快照,即发生在时间t的四元组集合。**我们用粗体字的s、p、o分别表示s、p、o的嵌入向量,其维度为d。E ∈ R|E|×d是所有实体的嵌入,其中的一行代表一个实体的嵌入向量,如s和o。类似地,P ∈ R|R|×d是所有关系类型的嵌入。
给定一个查询q = (s, p, ?, t),我们定义历史事件集合为
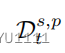
以及相应的历史实体集合为,
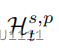
在以下方程中定义:
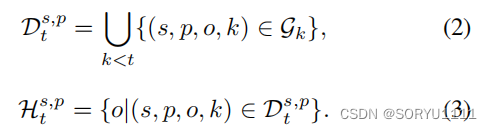
自然地,不在Ht s,p中的实体被称为非历史实体,而集合
![]()
表示非历史事件集合,其中一些四元组可能不存在于G中。值得注意的是,我们同样使用Dt s,p来表示当前事件(s, p, o, t)的历史事件集合。
如果一个事件(s, p, o, t)本身不在其对应的Dt s,p中,那么它就是一个新事件。不失一般性,我们将在接下来的部分详细说明CENET如何预测给定查询q = (s, p, ?, t)的对象实体。
3.2 Historical and Non-historical Dependency
在大多数TKGs中,尽管许多事件经常表现出重复发生的模式,新事件可能没有历史事件可以参考。因此,CENET不仅考虑历史实体,还考虑非历史实体。我们在数据预处理阶段首先调查了给定查询q = (s, p, ?, t)的历史实体的频率。
更具体地说,我们计算了在时间t之前,所有作为主体s和谓词p相关联的对象的实体的频率,
![]()
如方程4所示:
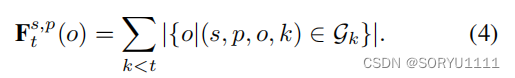
由于我们无法计算非历史实体的频率,CENET将Fs,p t转换为Z s,p t ∈ R |E|,其中每个槽的值由超参数λ限制: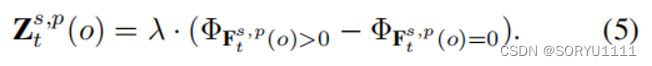
Φβ 是一个指示函数,当β为真时返回1,否则返回0。Z s,p t (o) > 0 表示三元组 (s, p, o, tk) 是一个历史事件,与 s、p 和 t (tk < t) 相关联,而 Z s,p t (o) < 0 表示三元组 (s, p, o, tk) 是一个在 G 中不存在的非历史事件。接下来,CENET 从历史和非历史事件中学习依赖关系,基于输入 Z s,p t 。CENET 采用了一种基于复制机制的学习策略(Gu等 2016)来捕捉不同类型的依赖关系:一方面是查询与实体集之间的相似度得分向量,另一方面是查询的相应频率信息与复制机制。
对于历史依赖,CENET 为查询 q 生成一个潜在的上下文向量 H s,p his ∈ R |E|,为不同对象实体评分历史依赖性:
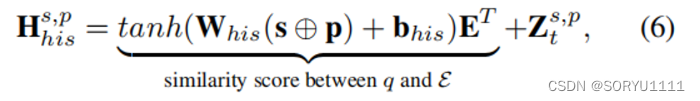
其中 tanh 是激活函数,⊕ 表示串联运算符,Whis ∈ Rd×2d和 bhis ∈ Rd 是可训练参数。我们使用一个带有 tanh 激活的线性层来聚合查询的信息。线性层的输出然后与 E 相乘,以获得一个 |E| 维向量,其中每个元素代表对应实体 o′ ∈ E 与查询 q 之间的相似度得分。 然后,根据复制机制,我们将复制项 Zs,pt 添加到 Hs,p his 中,直接提高历史实体的索引分数而不贡献于梯度更新。因此,Z s,p t 使得 Hs,phis 更加关注历史实体。类似地,对于非历史依赖,潜在上下文向量 Hs,p nhis 定义为:
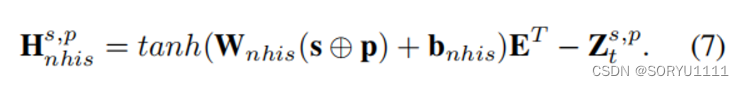
与历史依赖性(方程 6)相反,减去 Zs,pt 使得 Hs,p nhis 关注非历史实体。
从历史和非历史事件中学习的训练目标是最小化以下损失 Lce:
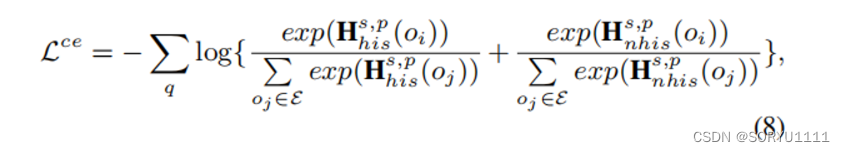
其中 oi 表示给定查询 q 的真实对象实体。Lce 的目的是通过比较 Hs,phis 和 Hs,pnhis 中的每个标量值来区分真实值与其他值。在推理过程中,CENET 将上述两个潜在上下文向量的 softmax 结果结合起来,作为对所有对象实体的预测概率 Ps,pt:
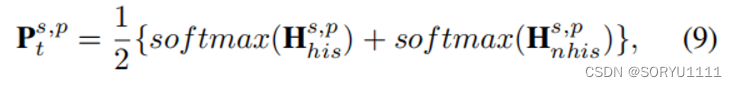
其中值最大的实体是最有可能被该组件预测的实体。
3.3 Historical Contrastive Learning
显然,上述定义的学习机制能够很好地捕捉每个查询的历史和非历史依赖性。然而,许多重复性和周期性事件只与历史实体有关。此外,对于新事件,现有模型可能会忽略那些历史交互较少的实体,并预测那些经常与其他事件交互的错误的实体。提出的历史对比学习训练了查询的对比表示,以识别在查询级别上高度相关的少数实体。
具体来说,监督对比学习(Khosla等人,2020年)的训练过程包括两个阶段。我们首先引入Iq来表示缺失对象是否在Hs,pt中,对于查询q。换句话说,如果Iq等于1,给定查询q的缺失对象在Hs,pt中,否则为0。这两个阶段的目的是训练一个二元分类器,它推断查询q的这样一个布尔标量的值。
Stage 1: Learning Contrastive Representations.
在第一阶段,模型通过最小化监督对比损失来学习查询的对比表示,该损失以Iq是否为正作为训练标准,以尽可能在语义空间中分离不同查询的表示。让vq表示给定查询q的嵌入向量(表示):
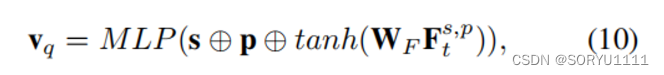
在这里,查询的信息通过一个多层感知器(MLP)进行编码,以归一化并将嵌入向量投影到单位球面上,以便进行进一步的对比训练。让M表示小批量数据,Q(q)表示在M中除了q之外的查询集合,其布尔标签与Iq相同,给定如下:
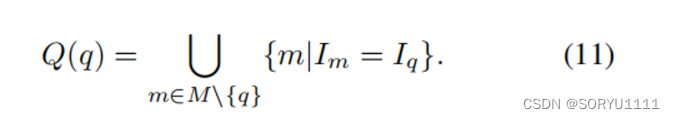
1第一阶段计算监督对比损失Lsup的细节如下:
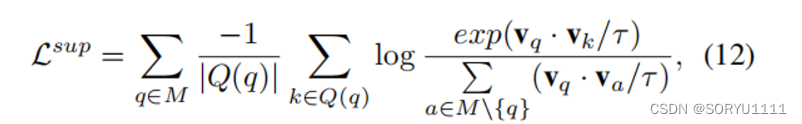
其中,WF ∈ Rd×|E| 是可训练的参数,τ ∈ R是温度参数,在实验中设置为0.1,这是根据之前的工作(Khosla等人,2020年)推荐的。Lsup的目标是使得同一类别的表示更接近。需要注意的是,对比监督损失Lsup和之前的交叉熵类损失Lce是同时训练的。
Stage 2: Training Binary Classifer.
当第一阶段的训练完成后,CENET会冻结第一阶段中包括E、P及其编码器在内的相应参数的权重。然后,它将vq输入到一个线性层中,根据真实标签Iq使用交叉熵损失来训练一个二元分类器,这一点值得一提。现在,这个分类器能够识别查询q中缺失对象实体是否存在于历史实体集合中。

(在推理过程中,根据预测的Iˆq和o ∈ Hts,p是否为真,生成一个布尔掩码向量B s,pt ∈ R|E|,以识别应该关注哪种类型的实体:)
所有阳性位置(Bs,pt(o) = 1)的实体概率将进一步增加,反之亦然。换句话说,如果预测缺失对象在Hs,pt中,那么历史集中的实体将受到更多的关注。否则,历史集之外的实体更容易被关注。
4 Results
Results on Event-based TKGs
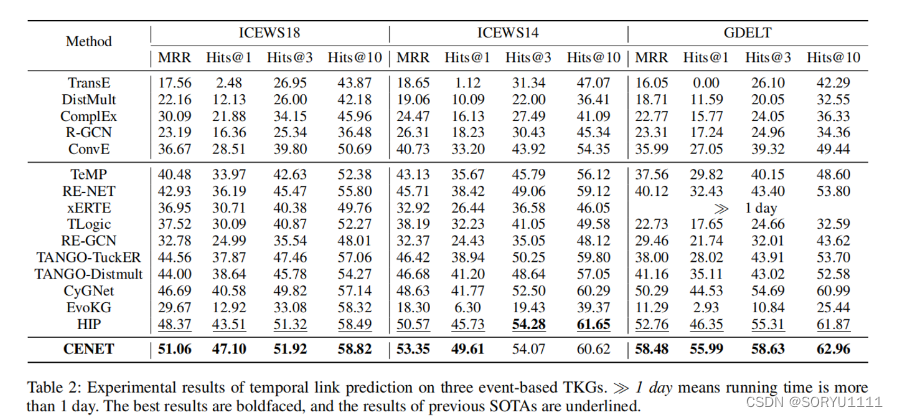
表2展示了在三个基于事件的知识图谱上链接(事件)预测的MRR和Hits@1/3/10结果。我们提出的CENET在大多数情况下都优于其他基线模型。可以观察到,许多静态模型不如时间模型,因为静态模型不考虑时间信息以及不同快照之间的依赖关系。在时间模型的情况下,TeMP被设计用于完成缺失链接(图形插值)而不是预测新事件,因此它的性能比外推模型差。尽管xERTE提供了一定程度的预测可解释性,但它处理像GDELT这样的大型数据集时在计算上是低效的,其训练集包含超过100万个样本。在Hits@10方面,CENET在这三个基于事件的数据集上与HIP持平。然而,Hits@1的结果在我们的模型中得到了最大的改进。CENET在ICEWS18、ICEWS14和GDELT上分别实现了高达8.25%、8.48%和20.80%的Hits@1改进。主要原因是在基于事件的数据集中存在大量没有历史事件的新事件。CENET同时学习新事件的历史和非历史依赖,挖掘那些未被观察到的潜在因素。相比之下,包括TANGO和HIP在内的模型在Hits@10方面表现良好,但不能精确预测正确的实体,使得Hits@1远低于我们的模型。
Results on Public KGs
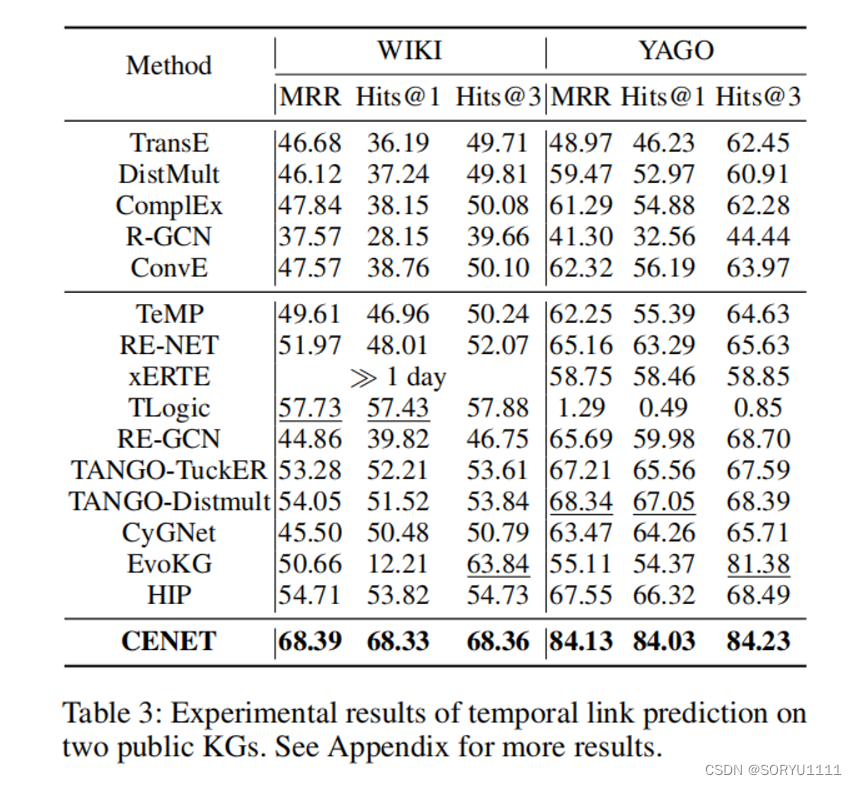
CENET在WIKI和YAGO上的所有指标上也优于基线模型。从表3中可以看出,CENET在公共知识图谱上显著地实现了最高达23.68%(MRR)、25.77%(Hits@1)和7.08%(Hits@3)的改进。这是因为这两个数据集中的复发率不平衡(Zhu等人,2021年),而我们的模型可以轻松处理这样的数据。就WIKI数据集而言,62.3%的对象实体与其对应的事实(按(主体,关系)元组分组)在历史中至少重复出现了一次。相比之下,主体实体(按(对象,关系)元组分组)的复发率为23.4%,这在推断主体实体时阻碍了许多模型从历史信息中学习。CENET可以有效缓解复发率不平衡的问题,因为同时学习历史和非历史依赖可以相互补充,生成实体分布。此外,由于二元分类器不考虑复发率不平衡,选择不相关实体的概率大大降低。
附录

ICEWS18
ICEWS18数据集主要包含文本数据,特别是关于政治事件和冲突的新闻报道的文本信息。这些文本数据通常包括新闻报道的标题、内容和元数据,如报道的日期、来源和地理位置。数据集中的文本数据被用来分析和预测国际危机和事件。
ICEWS18数据集通常不包含图片或图像数据。它主要是文本驱动的,用于文本分析和自然语言处理任务,如事件检测、情绪分析、主题建模和预测分析。如果研究需要图像数据,研究人员通常会使用其他数据源或数据集来补充ICEWS18的数据。















 1334
1334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









