






Prompting ChatGPT in MNER: Enhanced Multimodal Named Entity Recognition with Auxiliary Refined Knowledge
ACL 23
代码地址 https://github.com/ JinYuanLi0012/PGIM
Abstract
Multimodal Named Entity Recognition(MNER) on social media aims to enhance textual entity prediction by incorporating image-based clues. Existing studies mainly focus on maximizing the utilization of pertinent image information or incorporating external knowledge from explicit knowledge bases. However, these methods either neglect the necessity of providing the model with external knowledge, or encounter issues of high redundancy in the retrieved knowledge. In this paper, we present PGIM — a two-stage framework that aims to leverage ChatGPT as an implicit knowledge base and enable it to heuristically generate auxiliary knowledge for more efficient entity prediction. Specifically, PGIM contains a Multimodal Similar Example Awareness module that selects suitable examples from a small number of predefined artificial samples. These examples are then integrated into a formatted prompt template tailored to the MNER and guide ChatGPT to generate auxiliary refined knowledge. Finally, the acquired knowledge is integrated with the original text and fed into a downstream model for further processing. Extensive experiments show that PGIM outperforms state-of-the-art methods on two classic MNER datasets and exhibits a stronger robustness and generalization capability.1
社交媒体上的多模态命名实体识别(MNER)旨在通过融合基于图像的线索来增强文本实体预测。现有的研究主要集中在最大化相关图像信息的利用或将外部知识从显式知识库中融入。然而,这些方法要么忽视向模型提供外部知识的必要性,要么遇到检索到的知识中高度冗余的问题。本文提出了PGIM,这是一个两阶段的框架,旨在利用ChatGPT作为隐式知识库,并使其能够启发式地生成辅助知识以实现更高效的实体预测。具体而言,PGIM包括一个多模态相似示例感知模块,从少量预定义的人工样本中选择合适的示例。然后,这些示例被整合到适用于MNER的格式化提示模板中,引导ChatGPT生成辅助的精炼知识。最后,获取的知识与原始文本集成,并输入到下游模型进行进一步处理。大量实验证明,PGIM在两个经典的MNER数据集上优于最先进的方法,并展示了更强的鲁棒性和泛化能力。
1、Introduction
为了利用多模态特征并提高NER的性能,许多先前的工作尝试使用各种注意机制来隐式地对齐图像和文本(Yu等,2020;Sun等,2021),但这些图像-文本(I+T)范式方法存在几个重要的限制。
限制1:不同模态的特征分布存在变化,这妨碍了模型在不同模态之间学习对齐表示。
限制2:这些方法中使用的图像特征提取器是在ImageNet(Deng等,2009)和COCO(Lin等,2014)等数据集上训练的,其中标签主要由名词而不是命名实体组成。这些数据集的标签与我们要识别的命名实体之间存在明显的偏差。
考虑到这些限制,这些多模态融合方法可能不如专注于文本的最先进语言模型那样有效。
**尽管MNER是一项多模态任务,但图像和文本模态对该任务的贡献并不相等。当图像无法为文本提供更多的解释信息时,甚至可以将图像信息丢弃和忽略。**此外,最近的研究(Wang等,2021b;Zhang等,2022)表明,在原始文本的基础上引入额外的文档级上下文可以显著提高NER模型的性能。因此,最近的研究(Wang等,2021a,2022a)旨在使用文本-文本(T+T)范式解决MNER任务。在这些方法中,图像通过图像标题和光学字符识别(OCR)等技术被合理地转换为文本表示。显然,文本之间的注意机制更有可能胜过跨模态的注意机制。然而,现有的第二范式方法仍然存在一定的潜在不足之处:
一、对于仅依赖于样本内信息的方法,它们在需要额外外部知识来增强文本理解的情况下常常表现不佳。
二、对于那些考虑引入外部知识的现有方法来说,从外部明确的知识库(例如维基百科)检索到的相关知识往往是冗余的。这些低相关性的扩展知识有时甚至会误导模型对文本的理解。
最近,大型语言模型(LLMs)领域正在快速发展,出现了引人注目的新发现和进展(Brown等,2020;Touvron等,2023)。一方面,关于LLMs的最新研究(Qin等,2023;Wei等,2023;Wang等,2023a)显示,在序列标注任务中,生成模型的效果存在明显的缺点。另一方面,LLMs在各种自然语言处理(NLP)(Vilar等,2022;Moslem等,2023)和多模态任务(Yang等,2022;Shao等,2023)中取得了有希望的结果。这些具有上下文学习能力的LLMs可以被视为对基于互联网的知识的全面表示,并且通常可以提供高质量的辅助知识。
So we ask:Is it possible to activate the potential of ChatGPT in MNER task by endowing ChatGPT with reasonable heuristics?(通过赋予ChatGPT合理的启发式规则,激发其在MNER任务中的潜力,这是可能的吗?)
在本文中,我们提出了PGIM(Prompting ChatGPT In MNER)——一个概念上简单的框架,旨在通过促使ChatGPT在MNER任务中生成辅助的精细化知识来提高模型的性能。如图1所示,以这种方式生成的额外辅助的精细化知识克服了(i)和(ii)的限制。我们首先手动标注了一小部分样本。随后,PGIM利用多模态相似示例感知模块选择相关实例,并将它们无缝地整合到专门为MNER任务定制的精心设计的提示模板中,从而引入相关知识。这种方法有效地利用了ChatGPT的上下文少样本学习能力。最后,ChatGPT的启发式方法生成的辅助精细化知识随后与原始文本结合,输入到下游文本模型进行进一步处理。
PGIM在两个经典的MNER数据集上表现优于基于图像-文本和文本-文本范式的所有最新模型,并展现出更强的鲁棒性和泛化能力。此外,与一些先前的方法相比,PGIM对大多数研究人员更加友好,其实现只需要一个单独的GPU和合理数量的ChatGPT调用。
2、相关工作和动机:
这些方法都无法充分满足模型理解文本所需的必要知识。LLMs的进展解决了上述方法中所识别的限制。虽然在完全样本情况下,LLMs对命名实体的直接预测可能无法达到与任务特定模型相媲美的性能,但我们可以利用LLMs作为隐含的知识库,启发地生成对文本的进一步解释。这种方法更符合人类的认知和推理过程。
上下文学习:
随着LLMs的发展,实证研究表明这些模型(Brown等,2020)展现出一种有趣的新兴行为,称为上下文学习(ICL)。与BERT(Devlin等,2018)等预训练后微调语言模型的范式不同,GPT等LLMs引入了一种新颖的上下文少样本学习范式。这种范式不需要参数更新,并且仅使用少量来自下游任务的示例即可取得出色的结果。由于ICL的效果与示范示例的选择密切相关,最近的研究探索了几种有效的示例选择方法,例如基于相似度的检索方法(Liu等,2021;Rubin等,2021)、基于验证集分数的选择(Lee等,2021)和基于梯度的方法(Wang等,2023b)。这些结果表明,合理的示例选择可以提高LLMs的性能。
3、Methodology
PGIM主要分为两个阶段。在生成辅助精细化知识(generating auxiliary refined knowledge)的阶段中,PGIM利用一小部分预定义的人工样本,并使用多模态相似示例感知**(MSEA)模块仔细选择相关实例。然后,这些选择的示例被整合到适当格式的提示中,从而增强了对ChatGPT获取精细化知识的启发式引导。**(详见第3.2节)。
在基于辅助知识的实体预测阶段(entity prediction based on auxiliary knowledge),PGIM将原始文本与ChatGPT生成的知识信息相结合。然后,将这个连接后的输入馈入基于Transformer的编码器,以生成标记表示。最后,PGIM将这些表示馈入线性链条件随机场(CRF)层,以预测原始文本序列的概率分布(详见第3.3节)。PGIM的概述如图2所示。

3.1 预备知识
在介绍PGIM之前,我们首先对MNER任务进行了规范,并简要介绍了最初由GPT-3开发的上下文学习范式及其在MNER中的应用。
Task Formulation:
考虑将MNER任务视为一个序列标注任务。给定一个句子T = {t1, · · · , tn},其中包含n个标记,并且对应的图像为I,MNER的目标是定位和分类句子中提及的命名实体,形成一个标签序列y = {y1, · · · , yn},其中yi ∈ Y为预定义的语义类别,采用BIO2标记方案。
In-context learning in MNER:
(本文用的是GPT-3.5)
GPT-3及其继任者ChatGPT(以下统称为GPT)是在庞大数据集上预训练的自回归语言模型。在推断过程中,上下文少样本学习以冻结的GPT模型的文本序列生成任务的方式完成新的下游任务。具体而言,给定一个测试输入x,其目标y基于格式化的提示 p(h, C, x)作为条件进行预测,其中h表示描述任务的提示头部,而上下文C = {c1, · · · , cn}包含n个上下文示例。所有的h、C、x、y都是文本序列,目标y = {y1, · · · , yL}是长度为L的文本序列。在每个解码步骤l中,我们有:
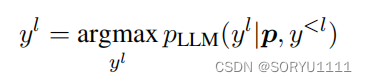
其中,LLM代表预训练大型语言模型的权重,这些权重在新任务中被冻结。每个上下文示例ci = (xi, yi)由任务的输入-目标对组成,这些示例可以手动构建或从训练集中采样获得。
尽管GPT-4可以接受多模态信息的输入,但该功能目前仅处于内部测试阶段,尚未对公众开放使用。此外,与ChatGPT相比,GPT-4的成本更高,API请求速度更慢。为了增强PGIM的可复现性,我们仍然选择ChatGPT作为我们方法的主要研究对象。而且,PGIM提供的这种范式也可以在GPT-4中使用。为了使ChatGPT能够完成图像-文本多模态任务,我们使用了先进的多模态预训练模型将图像转换为图像描述。受基于知识的视觉问答(PICa)(Yang等,2022)和Prophet(Shao等,2023)的启发,PGIM将测试输入x表示为以下模板:

其中,t、p和q表示特定的测试输入。\n代表模板中的换行符。
类似地,每个上下文示例ci使用类似的模板定义如下:
 其中,ti、pi、q和ai表示从预定义的人工样本中检索到的文本-图像-问题-答案四元组。MNER的完整提示模板由一个固定的提示头部、一些上下文示例和一个测试输入组成,将其馈入ChatGPT生成辅助知识。
其中,ti、pi、q和ai表示从预定义的人工样本中检索到的文本-图像-问题-答案四元组。MNER的完整提示模板由一个固定的提示头部、一些上下文示例和一个测试输入组成,将其馈入ChatGPT生成辅助知识。
3.2 Stage-1. Auxiliary Refined Knowledge Heuristic Generation
Predefined artificial samples
使ChatGPT在MNER任务中表现更好的关键是选择合适的上下文示例。获取准确注释的上下文示例,以准确反映数据集的注释风格并提供扩展辅助知识的方式,是一个重大挑战。直接从原始数据集中获取这样的示例是不可行的。
为了解决这个问题,我们采用了随机抽样的方法,从训练集中选择一个小的样本子集进行手动标注。具体而言,对于Twitter-2017数据集,我们从训练集中随机抽取200个样本进行手动标注,而对于Twitter-2015数据集,则是120个。标注过程包括两个主要组成部分。第一部分涉及在句子中识别命名实体,第二部分是通过考虑图像和文本的内容来提供全面的论证。在标注过程中遇到许多可能性时,注释者需要从人类的角度正确判断和解释样本。对于图像和文本相关的样本,我们直接说明了图像强调了文本中的哪些实体。对于图像和文本无关的样本,我们直接声明图像描述与文本无关。
通过人工注释过程,我们强调句子中的实体及其对应的类别。此外,我们还融入相关的辅助知识来支持这些判断。这个细致入微的注释过程作为ChatGPT的指导,使其能够生成高度相关和有价值的回答。
Multimodel Similar Example Awareness Module(MSEA)(多模态相似示例感知模块)
由于GPT的少样本学习能力在很大程度上取决于上下文示例的选择,我们设计了一个多模态相似示例感知(MSEA)模块来选择合适的上下文示例。作为经典的多模态任务,MNER的预测依赖于文本和视觉信息的整合。因此,PGIM利用文本和图像的融合特征作为评估相似示例的基本标准。而这种多模态融合特征可以从各种先前的基准MNER模型(Vanilla MNER Model)中获得。
将MNER数据集表示为D,预定义的人工样本表示为G:

其中,ti、pi、yi分别表示文本、图像和gold labels。在数据集D上训练的基准MNER模型M主要由骨干编码器Mb和CRF解码器Mc组成。多模态图像-文本对通过编码器Mb进行编码,得到多模态融合特征H。

在先前的研究中,将经过交叉注意力投影到高维潜空间的融合特征H直接输入到解码器层进行结果预测。与它们不同的是,PGIM选择H作为判断相似示例的依据。因为在高维潜空间中近似的示例更有可能具有相同的映射方法和实体类型。PGIM计算测试输入与每个预定义人工样本之间融合特征H的余弦相似度。然后,选择前N个相似的预定义人工样本作为上下文示例,为ChatGPT生成辅助的精炼知识:

I 是G中前N个相似样本的索引集合。上下文示例C的定义如下:

为了有效地实现对相似实例的感知,所有的多模态融合特征都可以提前计算和存储。
Heuristics-enhanced Prompt Generation(启发式增强的提示生成)
在获取上下文示例C之后,PGIM构建了一个完整的启发式增强提示,以利用ChatGPT在MNER中的少样本学习能力。一个提示头部、一组上下文示例和一个测试输入共同构成一个完整的提示。提示头部根据需求以自然语言描述MNER任务。考虑到输入的图像和文本可能并不总是直接相关的,PGIM鼓励ChatGPT行使自己的判断。上下文示例是从MSEA模块的结果C = {c1, · · · , cn}构建而成的。对于测试输入,答案槽留空供ChatGPT生成。提示模板的完整格式请参见附录A.4。
(我们提供了用于提示ChatGPT生成答案的模板。在图6中,PGIM引导ChatGPT进行辅助的精细知识生成。模板中的上下文示例和答案是由MSEA模块从预定义的人工样本中选择的。在图7中,我们引导ChatGPT进行直接预测。上下文示例是由MSEA模块从相同的预定义人工样本中选择的。请注意,这里的答案不再是人类的答案,而是文本中的命名实体。)




3.3 Stage-2. Entity Prediction based on Auxiliary Refined Knowledge
将ChatGPT在上下文学习后生成的辅助知识定义为Z = {z1, · · · , zm},其中m是Z的长度。PGIM将原始文本T = {t1, · · · , tn}与获得的辅助精炼知识Z连接起来,形成**[T;Z]**,并将其输入到基于Transformer的编码器中:

由于基于Transformer的编码器采用了注意力机制,所以所获得的标记表示H = {h1, · · · , hn}能够包含来自辅助知识Z的相关线索。与先前的研究类似,PGIM将H输入到一个标准的线性链条件随机场(CRF)层中,该层定义了给定输入句子T的标签序列y的概率:

其中![]()
是potential functions(潜在函数)
最后,PGIM使用负对数似然(NLL)作为带有真实标签y*的输入序列的损失函数:

Main Results

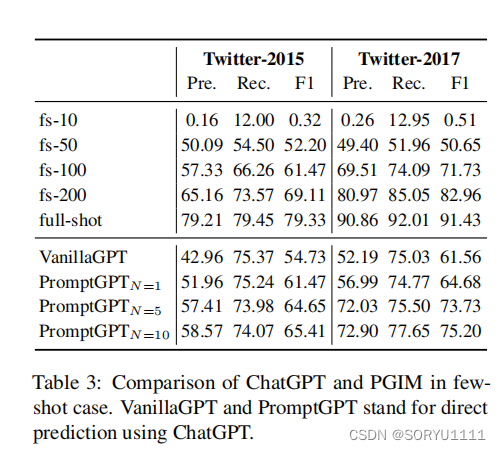
Compared with direct prediction of ChatGPT
Conclusion
在本文中,我们提出了一个名为PGIM的两阶段框架,并以一种新颖的方式将LLMs的潜力引入到MNER中。大量实验证明,PGIM优于最先进的方法,并显著克服了先前研究中的明显问题。此外,PGIM表现出强大的鲁棒性和泛化能力,只需要一个单独的GPU和合理数量的ChatGPT调用。在我们看来,这是将LLMs引入MNER中的一种巧妙方式。我们希望PGIM能够作为一个坚实的基准,激发未来关于MNER的研究,并最终更好地解决这个任务。
补充:
MSEA模块通常用于处理包含多种类型信息(如文本、图像、音频等)的数据集。它的主要任务是将不同模态的数据进行相似性度量和匹配,以便在多模态任务中进行有效的联合学习和决策。
Vanilla MNER模型指的是基本的、原始的MNER(Named Entity Recognition)模型,也被称为基准模型。它是一种经典的序列标注模型,用于从文本中识别和标记命名实体。














 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









