







Metric3D Towards Zero-shot Metric 3D Prediction from A Single Image
论文链接
开源项目
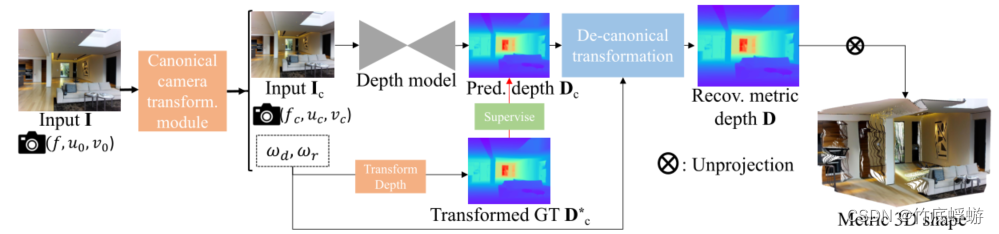
一句话总结:作者提出了一个规范相机空间变换模块,可以将图像映射到规范空间里预测深度,然后再将深度预测图通过去规范变换恢复到真实尺度,从而达到单目真实深度预测的目的。
Metric指的是真实世界中的度量值(XX米这种),不是相对的。由于相机参数不同,人们很难从单张图像中得到真实世界的度量值。

如上图,第一张和第二张depth是相同的,但因为相机参数不同,显得很不一样。第二张和第三张,照片上看很像,但是depth不同。
Abstruct
目标是使用图像还原3D场景。挑战是单目图像的ill-posedness,也就是一张图像可以对应无数个3D场景。导致这个挑战的原因是metric ambiguity,也就是图像中缺少了真实世界的度量信息。
SOTA monocular metric depth estimation methods只能够处理一种相机模式,不能处理大规模混合数据。因为它的Metric只是这一种相机的,换个相机就不能得到正确的Metric了。SOTA monocular metric depth estimation methods可以处理混合数据,学习affine-invariant depths后也能做零样本泛化,但是不能恢复真实世界的度量信息。
他们的方法既能Large-scale data training,又能解决Metric Ambiguity,从而实现了一个Zero-shot single-view metric depth model。
方法是:规范相机变换模块(canonical camera space transformation module),它的优点是能解决metric ambiguity,还可以很方便的插进现有的单目深度估计模型中。
Introduction
现有方法的问题
- 最先进的可转移方法(MiDas, LeRes, HDN)
- 能够应用到它没看到过的数据
- 只能得到Affine-invariant depth,相较真实的深度值有未知的偏移或尺度变化
- 单目Metric深度估计方法
- 只能在有单个相机模式的单个数据集上工作
- 不能应用到没见过的相机模式
深度估计方法分三类
- Metric Depth
- Relative Depth
- 估计图片中点的相对远近,应用范围有限
- Affine-invariant Depth
- 在大规模训练中解耦了度量信息(深度信息与具体的度量尺度的关系丢失了)
我们怎么做的
- 关键词:零样本、可迁移、单图像、真实度量
- 发现焦距(focal length)是影响真实度量信息准确度的关键因素
- LeReS训练时没有使用焦距信息,所以导致了深度尺度的解耦
- CamConv可以提取图像外观中隐藏的相机参数,但是训练数据的图像和相机类型太少了
- 训练:做规范变换(Canonical Transformation)将所有训练数据转换到规范相机空间(Canonical Camera Space)。转化后相当于所有图像都是来自于同一个相机。
- 图像映射到规范相机空间
- 地面实况标签也映射到规范相机空间(训练中用以监督)
- 推理:做去规范变换(de-canonical transformation)将规范相机空间中的预测深度图恢复到真实世界的深度度量
- Random proposal normalization loss:提高深度精度,但压缩了细粒度上的深度差异
- randomly crop several patchs:在图像中随机裁剪几个补丁,然后对他们做尺度变换不变损失(scale-shift invariant loss)。用来弥补随机提案归一化损失导致的细粒度深度差异的损失。
效果
- 可以做大规模、多种类的训练
- 零样本精度大大提高
- 下游应用收益(mono-SLAM, 3D场景重建……)
方法
尺度模糊性分析
相机参数:焦距( f ^ \hat{f} f^),像素点大小( δ \delta δ),主中心( ( u 0 , v 0 ) (u_0, v_0) (u0,v0))。论证了像素点大小对图像物体大小和实际物体大小的关系没影响,所以规范相机空间由 ( f , u , v ) (f, u, v) (f,u,v)描述。
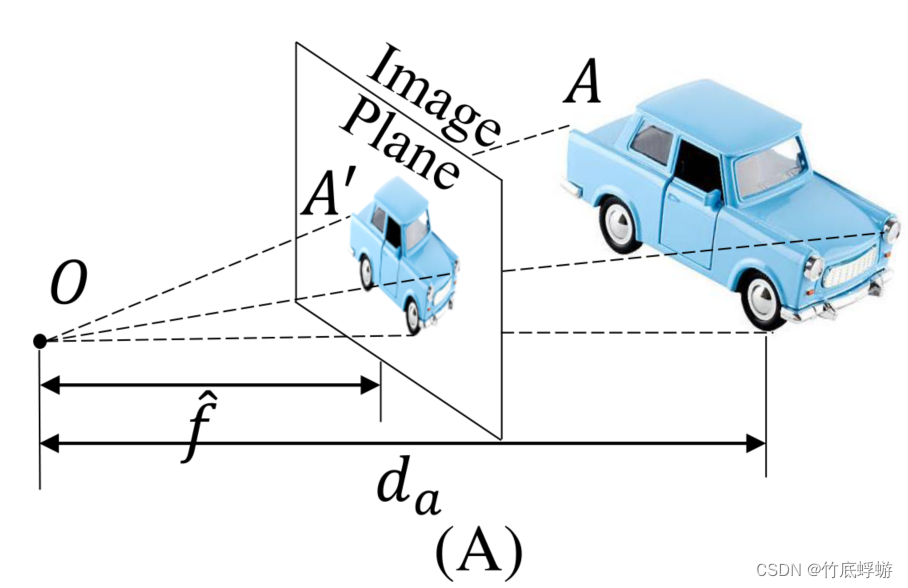
上图表明了相机参数对真实世界度量尺度的影响: d a = S ^ [ f ^ S ^ ′ ] = S ^ ⋅ α d_{a}=\hat{S}\left[\frac{\hat{f}}{\hat{S}^{\prime}}\right]=\hat{S} \cdot \alpha da=S^[S^′f^]=S^⋅α,其中 S ^ \hat{S} S^是真实世界大小, S ^ ′ \hat{S}^{\prime} S^′是图像大小。
规范相机变换
原始图像相机参数为 { f , u 0 , v 0 } \{f, u_0, v_0\} {f,u0,v0},规范相机空间参数 { f c , u c , v c } \{f_c, u_c, v_c\} {fc,uc,vc}。
transforming depth labels (CSTM label)
设置一个比率 ω d = f c f \omega_{d}=\frac{f^{c}}{f} ωd=ffc,给原来的深度空间尺度乘上 ω d \omega_{d} ωd就变换到规范空间,给规范空间深度图乘上 1 ω d \frac{1}{\omega_{d}} ωd1就变回真实深度空间。
transforming input images (CSTM image)
同理
Supervision
使用了随机提案归一化损失(random proposal normalization loss,RPNL),其中还裁剪了
M
M
M块。
L
R
P
N
L
=
1
M
N
∑
p
i
M
∑
j
N
∣
d
p
i
,
j
∗
−
μ
(
d
p
i
,
j
∗
)
1
N
∑
j
N
∣
d
p
i
,
j
∗
−
μ
(
d
p
i
,
j
∗
)
∣
−
d
p
i
,
j
−
μ
(
d
p
i
,
j
)
1
N
∑
j
N
∣
d
p
i
,
j
−
μ
(
d
p
i
,
j
)
∣
∣
\begin{array}{r} L_{\mathrm{RPNL}}=\frac{1}{M N} \sum_{p_{i}}^{M} \sum_{j}^{N} \mid \frac{d_{p_{i}, j}^{*}-\mu\left(d_{p_{i}, j}^{*}\right)}{\frac{1}{N} \sum_{j}^{N}\left|d_{p_{i}, j}^{*}-\mu\left(d_{p_{i}, j}^{*}\right)\right|}- \\ \frac{d_{p_{i}, j}-\mu\left(d_{p_{i}, j}\right)}{\frac{1}{N} \sum_{j}^{N}\left|d_{p_{i}, j}-\mu\left(d_{p_{i}, j}\right)\right|} \mid \end{array}
LRPNL=MN1∑piM∑jN∣N1∑jN
dpi,j∗−μ(dpi,j∗)
dpi,j∗−μ(dpi,j∗)−N1∑jN∣dpi,j−μ(dpi,j)∣dpi,j−μ(dpi,j)∣
d
∗
d^*
d∗表示真实深度,
d
d
d表示预测深度,
μ
(
.
)
\mu(.)
μ(.)表示深度中位数。
还用了其他的损失 L s i l o g , L P W N , L V N L L_{silog}, L_{PWN}, L_{VNL} Lsilog,LPWN,LVNL。
最终的损失值: L = L P W N + L V N L + L silog + L R P N L L=L_{\mathrm{PWN}}+L_{\mathrm{VNL}}+L_{\text {silog }}+L_{\mathrm{RPNL}} L=LPWN+LVNL+Lsilog +LRPNL















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









