







【准备工作】
下载好课后习题所用的数据集:
单变量线性回归
【问题描述】使用一个变量实现线性回归,预测食品卡车的利润。
假设你是一家餐馆的首席执行官,正在考虑在不同的城市开设一个新的分店。该连锁店已经在各个城市拥有卡车,假设现在你有各个城市的利润和人口数据。您将会使用这些数据来帮助您选择下一个扩张的城市。文件ex1data1.txt包含了我们线性回归问题的数据集。第一列是一个城市的人口,第二列是在该城市的食品卡车的利润。利润的负值表示损失。
首先,导入所需要的包。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
1. 导入数据
path='ex1data1.txt'
data=pd.read_csv(path,header=None,names=['Population','Profit'])
data # 导入数据并查看
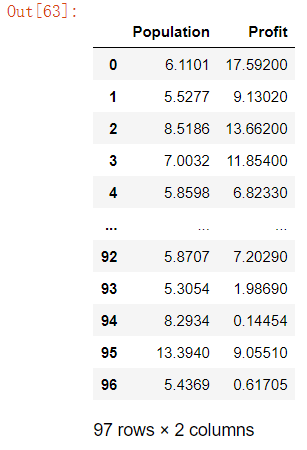
通过data.describe()进一步分析数据。
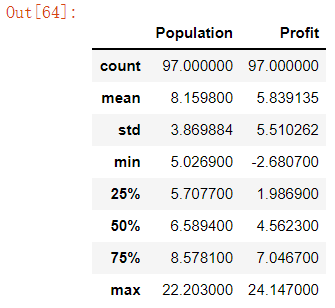
data.describe() # 数据描述
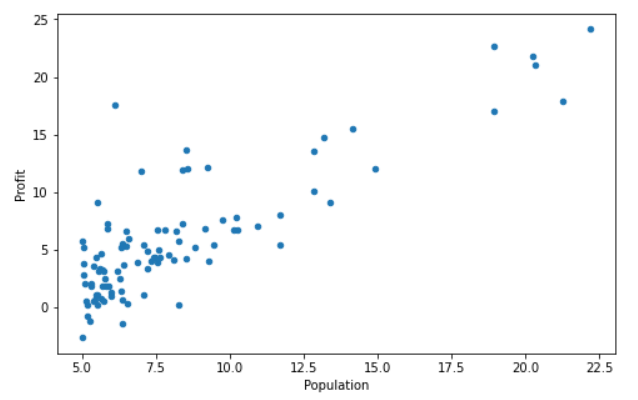
通过绘制散点图将数据可视化,横坐标为人口数量,纵坐标为利润。
2. 计算代价函数 θ
定义代价函数:
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2) # 注意此处用到的是theta的转置矩阵,所以theta维度为1*2
return np.sum(inner) / (2 * len(X))
在训练集中添加一列,以便我们可以使用向量化的解决方案来计算代价和梯度。(联想:用矩阵乘法可以同时预测4个房子的价格)
# 添加一列名为Ones的数据方便计算
data.insert(0,'Ones',1)
此时若执行cols=data.shape[1](该数据集维度为97*3,shape[1]返回列数),则得到cols的值为3。
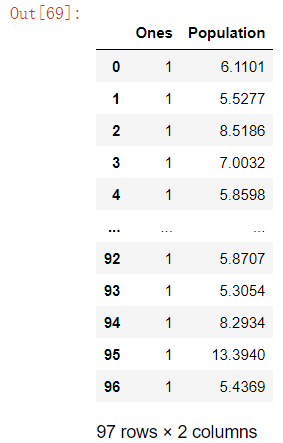
取前两列数据并查看(输入向量):
# 取除了最后一列的所有数据
X=data.iloc[:,0:cols-1]
X
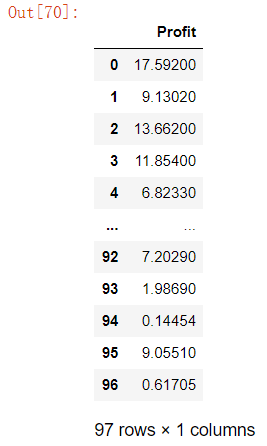
取最后一列的数据(目标向量)并查看:
# 取最后一列数据
y=data.iloc[:,cols-1:cols]
y
处理完数据集之后,我们可以进行一些变量初始化。
由于代价函数应该是numpy矩阵,所以我们需要转换X和Y再使用。我们还需要初始化θ。
X=np.matrix(X.values)
y=np.matrix(y.values)
theta=np.matrix([0,0])
theta

检查各数据的维度,确保计算无误。X.shape, theta.shape, y.shape结果为((97, 2), (1, 2), (97, 1))。
现在可以计算出初始代价函数的值:
computeCost(X, y, theta) # 32.072733877455676
3. batch gradient decent(批量梯度下降)
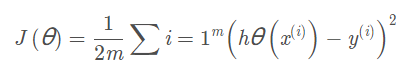
其中:
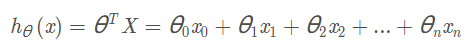
梯度下降优化公式:
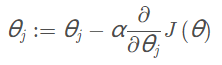
定义一个函数实现梯度下降。
def gradientDescent(X, y, theta, alpha, epoch):
temp = np.matrix(np.zeros(theta.shape)) # 初始化一个 θ 临时矩阵(1, 2)
parameters = int(theta.flatten().shape[1]) # 参数 θ的数量
cost = np.zeros(epoch) # 初始化一个ndarray,包含每次epoch的cost
m = X.shape[0] # 样本数量m
for i in range(epoch):
# 利用向量化一步求解
temp =theta - (alpha / m) * (X * theta.T - y).T * X
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost
# 使用梯度下降算法使得参数θ更适合于训练集
alpha=0.01
epoch=1000
final_theta, cost = gradientDescent(X, y, theta, alpha, epoch)
最后,我们可以使用梯度下降求解出的最终参数来计算训练模型的代价函数(误差)。
computeCost(X, y, final_theta) # 4.515955503078912
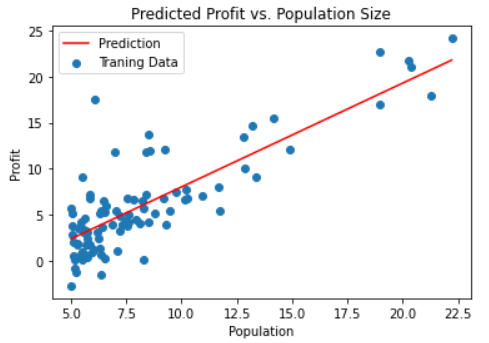
绘制线性模型以及数据,直观地看出它的拟合。
x = np.linspace(data.Population.min(), data.Population.max(), 100) # 横坐标
f = final_theta[0, 0] + (final_theta[0, 1] * x) # 纵坐标,利润
fig, ax = plt.subplots(figsize=(6,4))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data['Population'], data.Profit, label='Traning Data')
ax.legend(loc=2) # 2表示在左上角
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
由于梯度下降函数中的方程式也在每个训练迭代中输出一个代价的向量,于是我们也可绘制代价函数与迭代的关系。
fig, ax = plt.subplots(figsize=(8,4))
ax.plot(np.arange(epoch), cost, 'r') # np.arange()返回等差数组
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
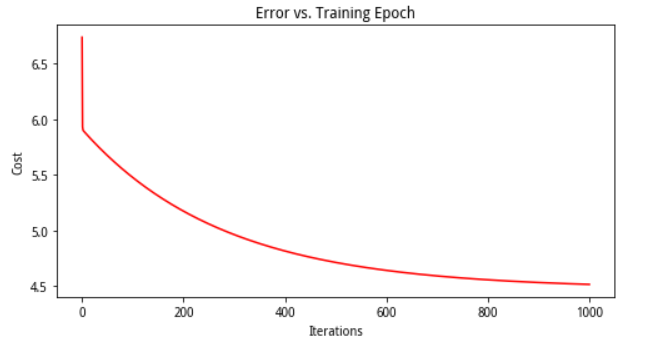
注意:线性回归中的代价函数总是降低的,这是凸优化问题的一个例子。















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









