







本练习ex8的压缩包已上传至我的资源已上传至我的资源 ,结合本篇博客食用更佳。
原理
原理在此,其实就是改了一下代价-梯度函数的回归算法。
载入数据
MovieLens 100k Dataset from GroupLens Research. 包含943位用户、1682部电影。
% Load data
load('ex8_movies.mat');
% From the matrix, we can compute statistics like average rating.
fprintf('Average rating for movie 1 (Toy Story): %f / 5\n\n', mean(Y(1, R(1, :))));
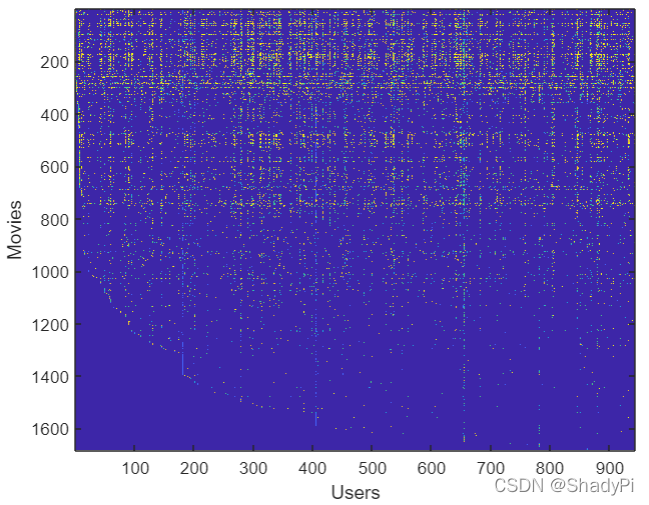
% We can "visualize" the ratings matrix by plotting it with imagesc
imagesc(Y);
ylabel('Movies');
xlabel('Users');
可以可视化看一看,跟背景一个颜色(蓝色)就是无评分,其他的就是不同颜色表示不同评分:
代价-梯度函数
表达式原理部分已经有了,照着表达式进行向量化即可,记住向量化的真理:按照矩阵运算规则替换代数公式。
另外要注意跟最优化函数保持兼容,所以代价-梯度函数的输入输出都是列向量,这点跟神经网络部分很像。
function [J, grad] = cofiCostFunc(params, Y, R, num_users, num_movies, ...
num_features, lambda)
%COFICOSTFUNC Collaborative filtering cost function
% [J, grad] = COFICOSTFUNC(params, Y, R, num_users, num_movies, ...
% num_features, lambda) returns the cost and gradient for the
% collaborative filtering problem.
%
% Unfold the U and W matrices from params
X = reshape(params(1:num_movies*num_features), num_movies, num_features);
Theta = reshape(params(num_movies*num_features+1:end), ...
num_users, num_features);
% You need to return the following values correctly
J = 0;
X_grad = zeros(size(X));
Theta_grad = zeros(size(Theta));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost function and gradient for collaborative
% filtering. Concretely, you should first implement the cost
% function (without regularization) and make sure it is
% matches our costs. After that, you should implement the
% gradient and use the checkCostFunction routine to check
% that the gradient is correct. Finally, you should implement
% regularization.
%
% Notes: X - num_movies x num_features matrix of movie features
% Theta - num_users x num_features matrix of user features
% Y - num_movies x num_users matrix of user ratings of movies
% R - num_movies x num_users matrix, where R(i, j) = 1 if the
% i-th movie was rated by the j-th user
%
% You should set the following variables correctly:
%
% X_grad - num_movies x num_features matrix, containing the
% partial derivatives w.r.t. to each element of X
% Theta_grad - num_users x num_features matrix, containing the
% partial derivatives w.r.t. to each element of Theta
%
E=(X*Theta'-Y).*R;
J=sum(sum(E.^2))/2+(lambda/2)*sum(sum(Theta.^2))+(lambda/2)*sum(sum(X.^2));
Theta_grad=E'*X+lambda*Theta;
X_grad=E*Theta+lambda*X;
% =============================================================
grad = [X_grad(:); Theta_grad(:)];
end
如果你觉得求梯度比较复杂,担心出错,可以使用梯度检验,该代码由吴恩达提供。
function numgrad = computeNumericalGradient(J, theta)
%COMPUTENUMERICALGRADIENT Computes the gradient using "finite differences"
%and gives us a numerical estimate of the gradient.
% numgrad = COMPUTENUMERICALGRADIENT(J, theta) computes the numerical
% gradient of the function J around theta. Calling y = J(theta) should
% return the function value at theta.
% Notes: The following code implements numerical gradient checking, and
% returns the numerical gradient.It sets numgrad(i) to (a numerical
% approximation of) the partial derivative of J with respect to the
% i-th input argument, evaluated at theta. (i.e., numgrad(i) should
% be the (approximately) the partial derivative of J with respect
% to theta(i).)
%
numgrad = zeros(size(theta));
perturb = zeros(size(theta));
e = 1e-4;
for p = 1:numel(theta)
% Set perturbation vector
perturb(p) = e;
loss1 = J(theta - perturb);
loss2 = J(theta + perturb);
% Compute Numerical Gradient
numgrad(p) = (loss2 - loss1) / (2*e);
perturb(p) = 0;
end
end
function checkCostFunction(lambda)
%CHECKCOSTFUNCTION Creates a collaborative filering problem
%to check your cost function and gradients
% CHECKCOSTFUNCTION(lambda) Creates a collaborative filering problem
% to check your cost function and gradients, it will output the
% analytical gradients produced by your code and the numerical gradients
% (computed using computeNumericalGradient). These two gradient
% computations should result in very similar values.
% Set lambda
if ~exist('lambda', 'var') || isempty(lambda)
lambda = 0;
end
%% Create small problem
X_t = rand(4, 3);
Theta_t = rand(5, 3);
% Zap out most entries
Y = X_t * Theta_t';
Y(rand(size(Y)) > 0.5) = 0;
R = zeros(size(Y));
R(Y ~= 0) = 1;
%% Run Gradient Checking
X = randn(size(X_t));
Theta = randn(size(Theta_t));
num_users = size(Y, 2);
num_movies = size(Y, 1);
num_features = size(Theta_t, 2);
numgrad = computeNumericalGradient( ...
@(t) cofiCostFunc(t, Y, R, num_users, num_movies, ...
num_features, lambda), [X(:); Theta(:)]);
[cost, grad] = cofiCostFunc([X(:); Theta(:)], Y, R, num_users, ...
num_movies, num_features, lambda);
disp([numgrad grad]);
fprintf(['The above two columns you get should be very similar.\n' ...
'(Left-Your Numerical Gradient, Right-Analytical Gradient)\n\n']);
diff = norm(numgrad-grad)/norm(numgrad+grad);
fprintf(['If your cost function implementation is correct, then \n' ...
'the relative difference will be small (less than 1e-9). \n' ...
'\nRelative Difference: %g\n'], diff);
end
求解
求解还是那一套,调用大佬写的函数就完事了,记得均值归一化。
function [Ynorm, Ymean] = normalizeRatings(Y, R)
%NORMALIZERATINGS Preprocess data by subtracting mean rating for every
%movie (every row)
% [Ynorm, Ymean] = NORMALIZERATINGS(Y, R) normalized Y so that each movie
% has a rating of 0 on average, and returns the mean rating in Ymean.
%
[m, n] = size(Y);
Ymean = zeros(m, 1);
Ynorm = zeros(size(Y));
for i = 1:m
idx = find(R(i, :) == 1);
Ymean(i) = mean(Y(i, idx));
Ynorm(i, idx) = Y(i, idx) - Ymean(i);
end
end
% Load data
load('ex8_movies.mat');
% Y is a 1682x943 matrix, containing ratings (1-5) of 1682 movies by 943 users
% R is a 1682x943 matrix, where R(i,j) = 1 if and only if user j gave a rating to movie i
% Add our own ratings to the data matrix
Y = [my_ratings Y];
R = [(my_ratings ~= 0) R];
% Normalize Ratings
[Ynorm, Ymean] = normalizeRatings(Y, R);
% Useful Values
num_users = size(Y, 2);
num_movies = size(Y, 1);
num_features = 10;
% Set Initial Parameters (Theta, X)
X = randn(num_movies, num_features);
Theta = randn(num_users, num_features);
initial_parameters = [X(:); Theta(:)];
% Set options for fmincg
options = optimset('GradObj','on','MaxIter',100);
% Set Regularization
lambda = 10;
theta = fmincg(@(t)(cofiCostFunc(t, Ynorm, R, num_users, num_movies, num_features,lambda)), initial_parameters, options);
% Unfold the returned theta back into U and W
X = reshape(theta(1:num_movies*num_features), num_movies, num_features);
Theta = reshape(theta(num_movies*num_features+1:end), num_users, num_features);
预测
求出了 Θ \Theta Θ和 X X X就相当于求得了用户的喜好与电影的特征值,根据这些参数我们就可以为用户推荐电影了:
p = X * Theta';
my_predictions = p(:,1) + Ymean;
movieList = loadMovieList();
[r, ix] = sort(my_predictions,'descend');
for i=1:10
j = ix(i);
if i == 1
fprintf('\nTop recommendations for you:\n');
end
fprintf('Predicting rating %.1f for movie %s\n', my_predictions(j), movieList{j});
end
















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











