




作者:云智慧算法工程师 Chris Hu
异常检测是识别与正常数据不同的数据,与预期行为差异大的数据。本文详细介绍了异常检测的应用领域以及总结梳理了异常检测的算法模型分类。文章最后更是介绍了常用的异常算法数据集。
异常的概念与类型
目前异常检测主要是基于Hawkins对异常的定义:(Hawkins defines an outlier as an observation that deviates so significantly from other observations as to arouse suspicion that it was generated by a different mechanism.)。异常(anomaly/outlier)指的是远离其他观测数据而疑为不同机制产生的观测数据。根据概率理论对异常的形式化定义如下:

异常主要分为以下三种类型:
-
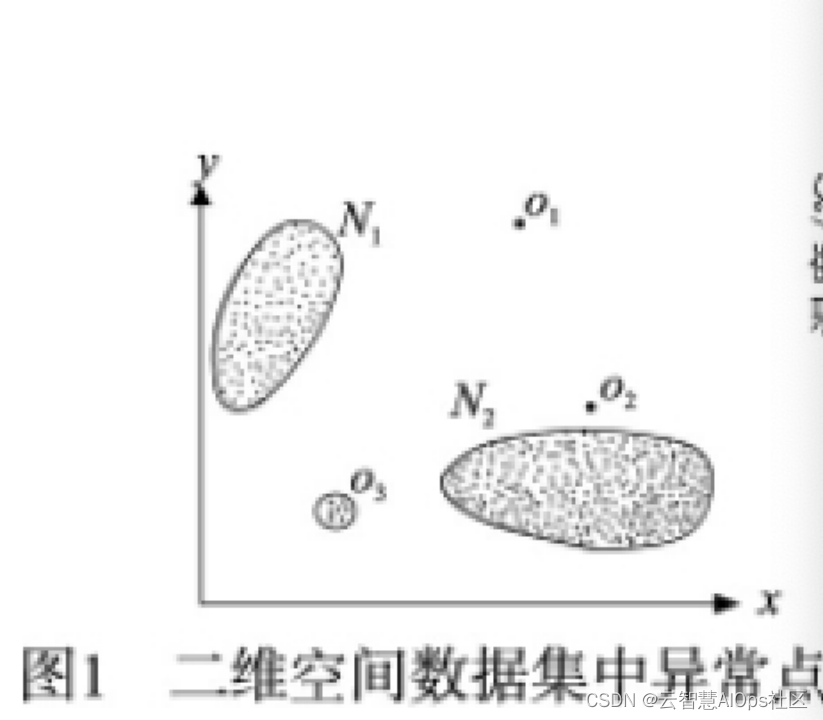
point anomalies(点异常)
点异常是单个异常数据点 ,将数据集中每个数据映射到高维空间中,其中孤立的点被称为点异常。这种异常点与其他数据点具有明显差异,这种异常分类是异常数据中最为简单的一种,也是异常检测研究中最常研究的异常类型。
-
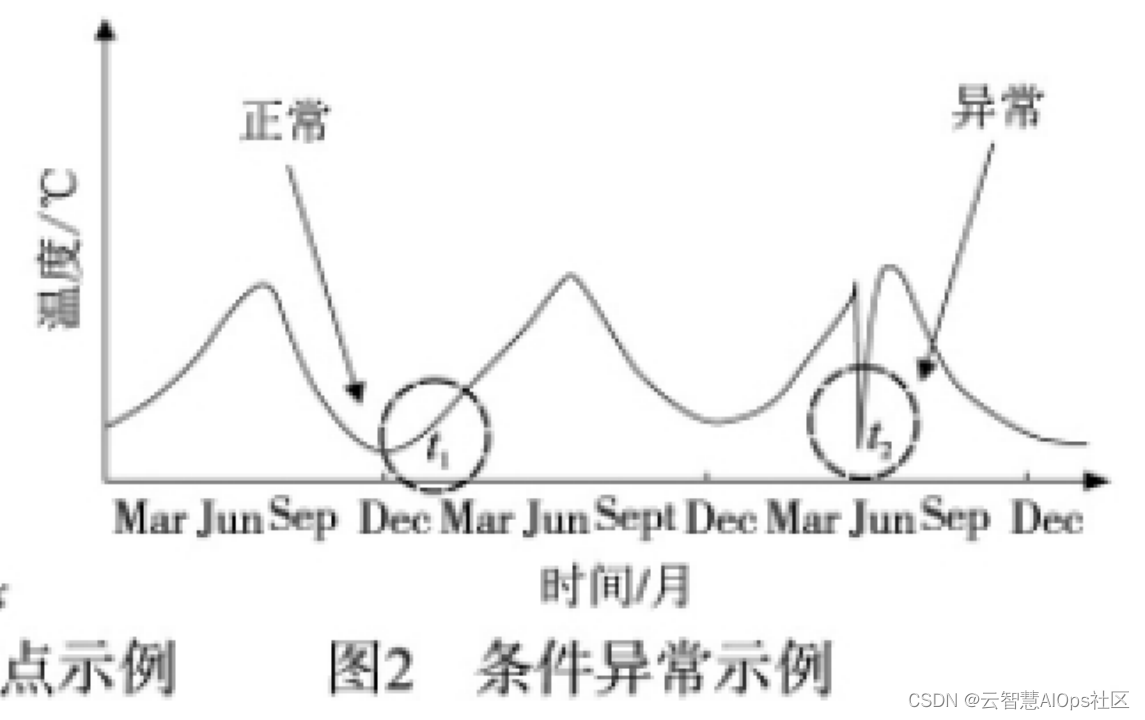
conditional anomalies/contextual anomalies(条件异常/上下文异常)
一个数据本身来看属于正常点,但在特定的条件下又与一般情况有差异,这类数据称为条件异常或上下文异常。其中上下文指数据集间的结构和关系,每个数据均由上下文特征( contextual attributes) 及行为特征( behavioral attributes) 来定义,即条件异常需要考虑的不仅仅是数据的取值,还需考虑数据出现的环境,也就是说某一数据在特定数据环境下被判断为异常,而在其他数据集中则可能是正常的。
-
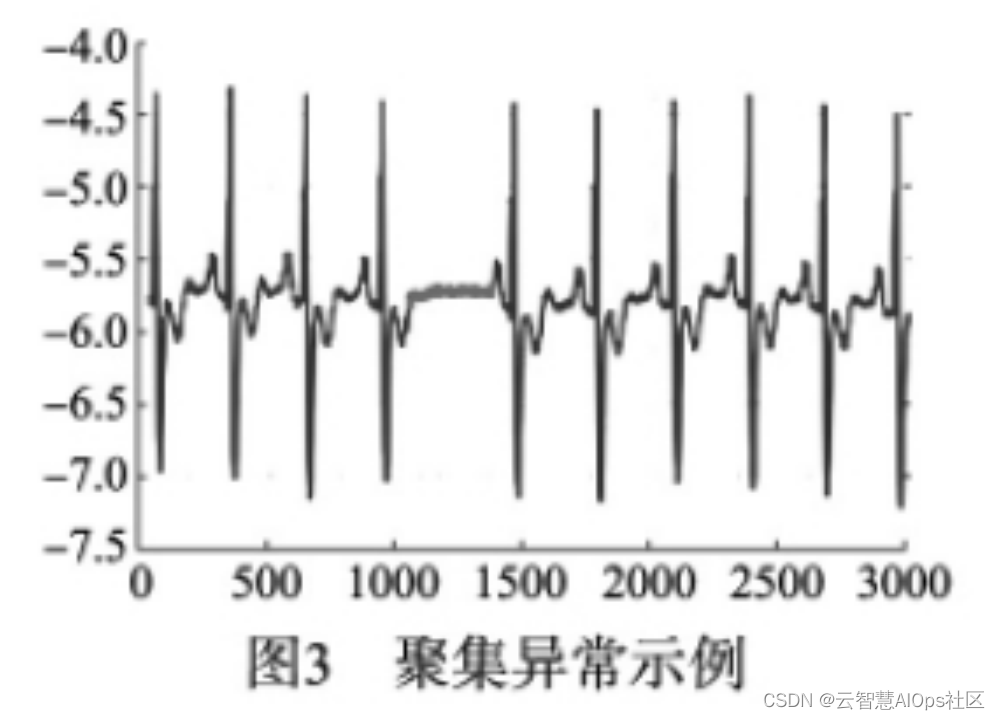
collective anomalies/group anomalies(群体异常/序列异常)
数据属性在正常范围内,且从上下文环境角度判断也属于正常的数据仍有可能是异常数据。如图3所示,在脑电图中虚线圆圈部分与脑电图整体图形不一致模式称之为聚集异常( 或称集合异常)。异常数据集中单个点可能并不异常,但这些相互关联的数据点聚集在一起时变为异常的情况。聚集异常不仅需要考虑数据的取值、上下文环境,还考虑数据集是否符合整体模式。聚集异常检测常用于时间序列、空 间数据以及图形式的数据中。
在实际的运维场景中,以上三种异常都会出现,比如资源使用率突然上升造成Point Anomalies,又如CPU使用过程中的突然卡顿形成Contextual anomaly,再如某指标使用率连续一段时间处于“满格”状态而呈现出Collective or group anomalies。后两者异常通常需要和业务紧密结合,单纯从数据本身出发具有一定的辨识难度,再加上运维领域中大比例情况下出现的是Point Anomalies,客户多关注于此,因而通常情况下我们更关注Point Anomalies。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









