






 本文探讨了在联邦学习环境下,医院模型如何通过APD算法解决持续学习中的灾难性遗忘问题,通过任务相关性和注意力机制优化多任务协作。实验展示了模型在异步场景下的优势。
本文探讨了在联邦学习环境下,医院模型如何通过APD算法解决持续学习中的灾难性遗忘问题,通过任务相关性和注意力机制优化多任务协作。实验展示了模型在异步场景下的优势。
本文提出了一种新的场景,联邦学习(FL)的每个client各自执行一系列的持续学习(Continual Learning)任务,为了说明这个场景的实际意义,文章给出了这样一个场景:
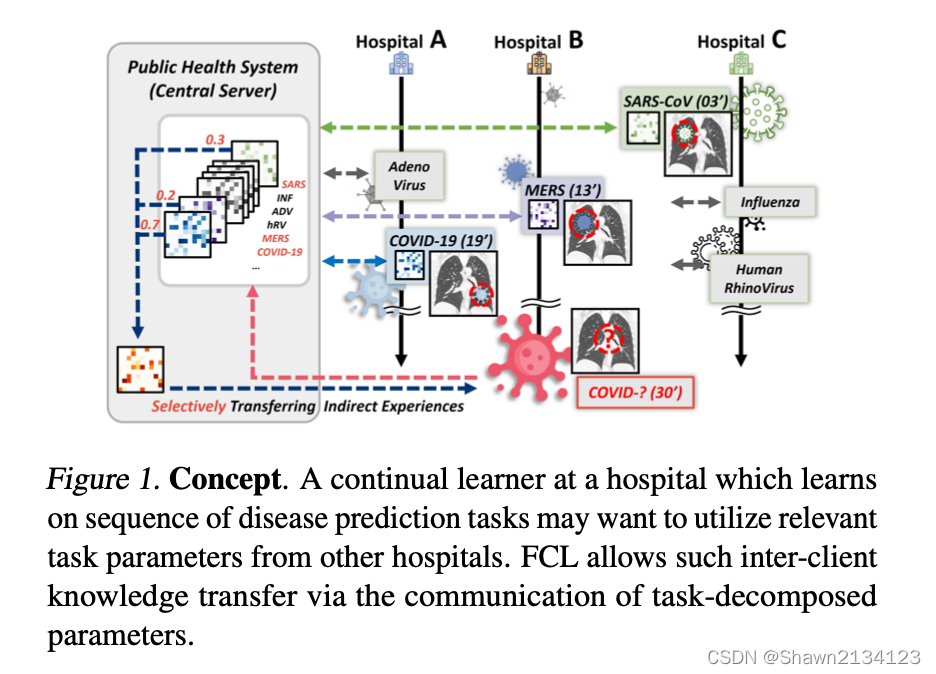
若干个医院要通过一个联邦学习框架交流自己的知识,每个医院的模型都在进行自己的一系列的疾病预测任务。作者以一个持续学习算法(Additive Parameter Decomposition,APD)为基础,加上了client之间的知识的加权,构成了整个算法,其中APD是本文同一作者发表在2020年ICLR的论文。
Continual Learning、APD
Continual Learning是为了解决现有模型,尤其是神经网络在学习多个任务的时候出现的灾难性遗忘(Catastrophic Forgetting)问题。比如模型在学习了一段时间任务A之后,开始学习任务B,那么模型的参数将转而向任务B偏移,遗忘从任务A中学习到的知识。为了能够让模型拥有像人这样,学习了后面的任务但是不会遗忘前面的知识、或者说能够不让模型在前面的任务中表现下滑太多,我们引入了Continual Learning 这个研究内容。APD是本文作者以前提出的一个持续学习算法,这里不过多介绍,只说一下它的核心思想,就是把模型拆分成两部分:共享参数(task-shared parameters)和自适应参数(task-adaptive parameters),简称为
σ
\sigma
σ和
τ
\tau
τ。因为每个任务之间有些基本的知识是共通的,比如图片中像线条、颜色等这样的浅层特征,这些由
σ
\sigma
σ来学习,细化到每个任务的学习目标,比如猫狗识别、数字识别等,这些是不同任务间特有的知识,有
τ
\tau
τ来学习。每个任务t的参数
θ
t
=
σ
⊗
M
t
+
τ
t
\theta_t=\sigma\otimes\mathcal{M}_t+\tau_t
θt=σ⊗Mt+τt,其中
M
\mathcal{M}
M表示一个mask变量,使
σ
\sigma
σ集中注意力于特定的任务上。优化目标为
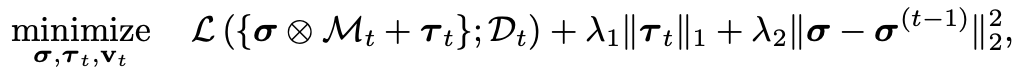
模型
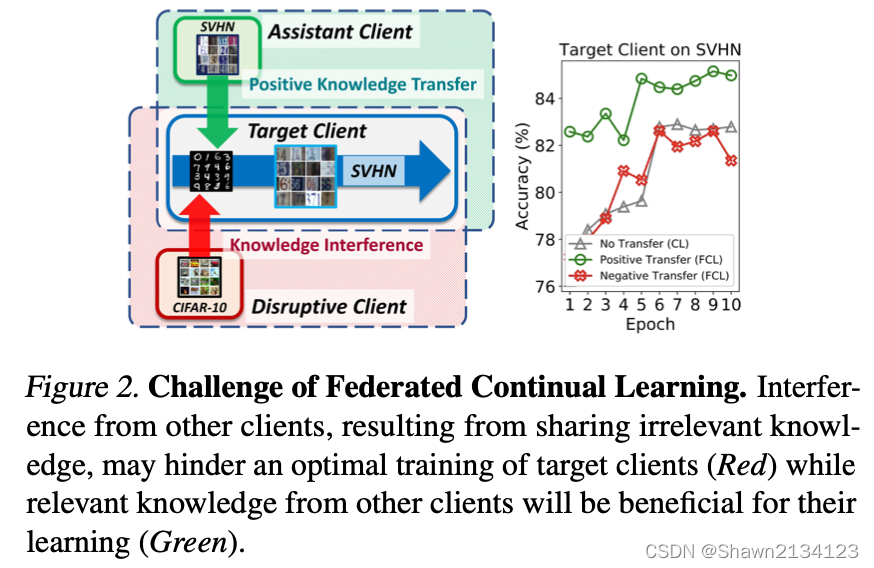
两个不同的任务合作学习时,往往会出现Figure 2所示的问题,如果两个任务相关性比较强,辅助任务对目标任务有正向作用,如果任务相关性比较弱,则可能会阻碍目标任务的结果,因此在学习时,应当让与目标任务更相似的任务参与辅助。
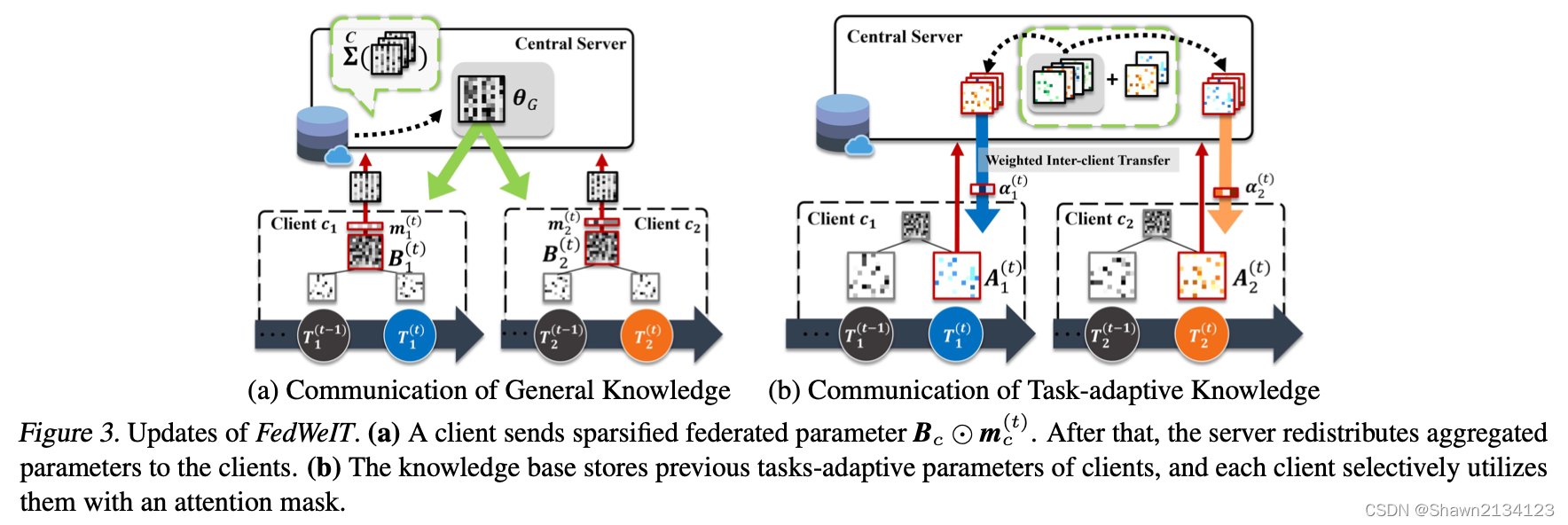
如图,每个client执行一系列的任务,这些任务共享一个base model:B。client先将全局模型
θ
G
\theta_G
θG下载下来,作为本地的base model。经过若干轮的local update之后,B通过一个mask m上传到服务端,服务端对其进行聚合得到新的全局模型
θ
G
\theta_G
θG。这部分学习的是这些client的通用知识。此外,因为每个client的每个任务都划分为base model(B)和adaptive model(A),client还会把自己所有的A上传,server把这一组A广播给所有的client,client的每个任务自己维护一组注意力参数
α
\alpha
α,有选择性的对这些A进行利用,组成自己的A。于是可以将局部模型
θ
c
\theta_c
θc表示为

A
i
(
j
)
A_i^{(j)}
Ai(j)表示第i个client第j个任务的A,
α
i
,
j
(
t
)
\alpha_{i,j}^{(t)}
αi,j(t)表示它在当前client的第t个任务之下的系数。训练的目标函数为:

第一项就是模型在任务上的损失,第二项是
l
1
l_1
l1正则化相,使得模型A和mask参数稀疏化,第三项则是限制持续学习过程中模型变化的量,用于保持先前任务中学习的知识。算法框架如下:

实验
实验部分只介绍以下两个
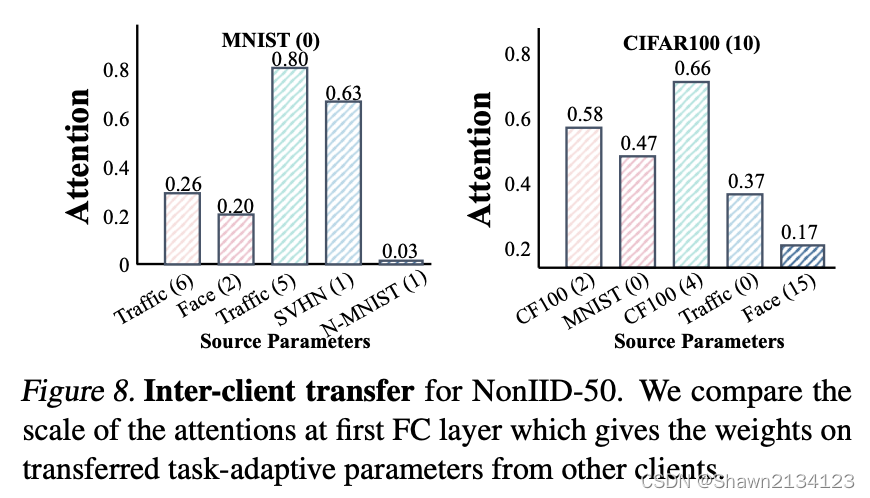
上图所示的实验是attention和任务相关性的关系实验,任务相似度越高,其adaptive model的attention越大,对当前模型的影响越大。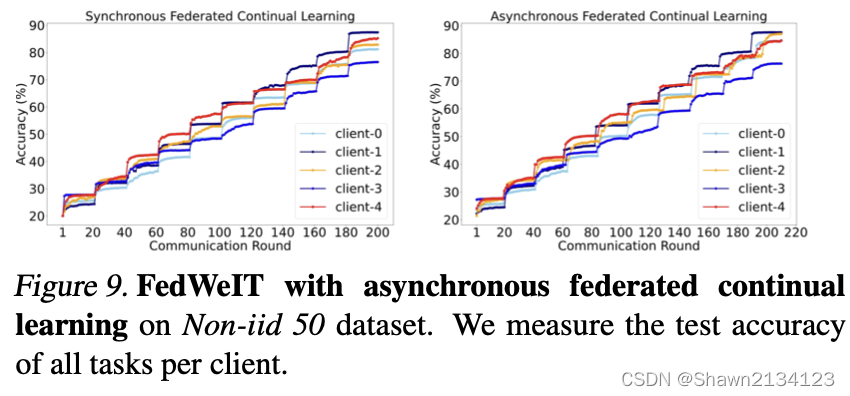
然后作者在异步场景下也做了实验,此模型在各client异步共享模型的情况下表现也要更好。
(转载请注明出处)

















 3859
3859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









