







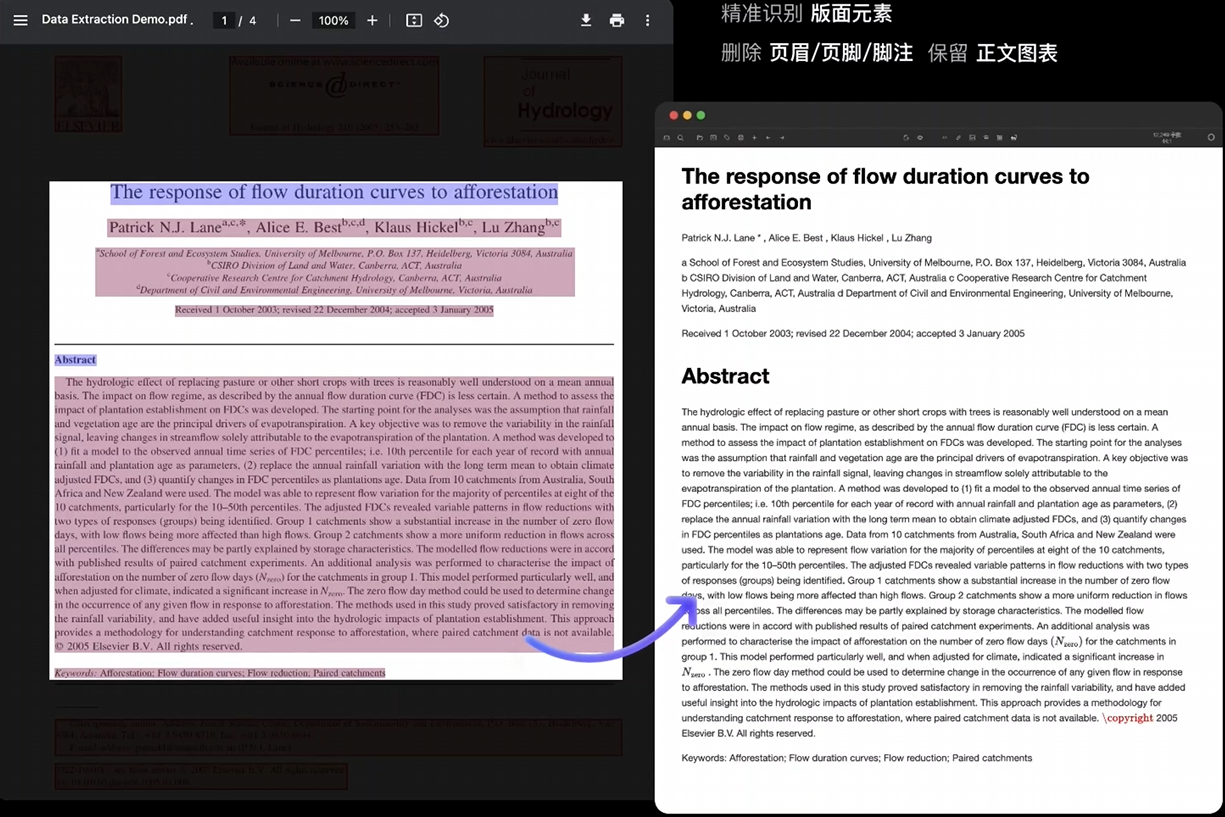
介绍
MinerU 是一个开源的高质量数据提取工具,主要用于将 PDF、Word、PPT 等多种格式的文档转换为机器可读的格式,如 Markdown 和 JSON。它由上海人工智能实验室开发,诞生于 InternLM 大模型的预训练过程,专注于解决科学文献中的符号转换问题,同时支持复杂文档的精准解析,包括文字、表格、图片和 LaTeX 公式的提取。
配置
| 类别 | Linux(2019 之后) | Windows 10/11 | macOS 11+ |
|---|---|---|---|
| 操作系统 | Linux 2019 之后 | Windows 10/11 | macOS 11 及以上 |
| CPU | x86_64 / arm64 | x86_64(不支持 ARM Windows) | x86_64 / arm64 |
| 内存要求 | 16GB 或更多,推荐 32GB+ | 16GB 或更多,推荐 32GB+ | 16GB 或更多,推荐 32GB+ |
| 存储要求 | 20GB 或更多,优先使用 SSD | 20GB 或更多,优先使用 SSD | 20GB 或更多,优先使用 SSD |
| Python 版本 | 3.10-3.12 | 3.10-3.12 | 3.10-3.12 |
| NVIDIA 驱动版本 | 最新(专有驱动) | 最新 | 无 |
| CUDA 环境 | 11.8 / 12.4 / 12.6 / 12.8 | 11.8 / 12.4 / 12.6 / 12.8 | 无 |
| CANN 环境(NPU 支持) | 8.0+(昇腾 910B) | 无 | 无 |
| GPU/MPS 硬件支持列表 | GPU VRAM 6GB 或更多:支持所有 Volta(2017)之后生产的 GPU,VRAM 6GB 或更多 | GPU VRAM 6GB 或更多:支持所有 Volta(2017)之后生产的 GPU,VRAM 6GB 或更多 | Apple Silicon |
安装
创建python环境
conda create -n mineru 'python>=3.10' -y
conda activate mineru
pip install -U "magic-pdf[full]"
下载模型权重
pip install huggingface_hub
wget https://github.com/opendatalab/MinerU/raw/master/scripts/download_models_hf.py -O download_models_hf.py
python download_models_hf.py
国内下载不了的同学关注wx公众号【茅五之缘】发送minerU免费获取
Python脚本会自动下载模型文件并在配置文件中配置模型目录。
配置文件可以在用户目录中找到,文件名为magic-pdf.json。
提示
Windows 的用户目录是“C:\Users\username”,Linux 的用户目录是“/home/username”,macOS 的用户目录是“/Users/username”。
使用
1. 命令行
magic-pdf --help
Usage: magic-pdf [OPTIONS]
Options:
-v, --version display the version and exit
-p, --path PATH local filepath or directory. support PDF, PPT,
PPTX, DOC, DOCX, PNG, JPG files [required]
-o, --output-dir PATH output local directory [required]
-m, --method [ocr|txt|auto] the method for parsing pdf. ocr: using ocr
technique to extract information from pdf. txt:
suitable for the text-based pdf only and
outperform ocr. auto: automatically choose the
best method for parsing pdf from ocr and txt.
without method specified, auto will be used by
default.
-l, --lang TEXT Input the languages in the pdf (if known) to
improve OCR accuracy. Optional. You should
input "Abbreviation" with language form url: ht
tps://paddlepaddle.github.io/PaddleOCR/en/ppocr
/blog/multi_languages.html#5-support-languages-
and-abbreviations
-d, --debug BOOLEAN Enables detailed debugging information during
the execution of the CLI commands.
-s, --start INTEGER The starting page for PDF parsing, beginning
from 0.
-e, --end INTEGER The ending page for PDF parsing, beginning from
0.
--help Show this message and exit.
magic-pdf [OPTIONS] 表示该工具通过命令行参数(选项)来运行,下面是每个选项的含义:
-v, --version
显示 magic-pdf 的版本号并退出。
示例:magic-pdf -v 会输出版本信息。-p, --path PATH
指定要解析的文件或文件夹路径(必填)。支持的格式包括 PDF、PPT、PPTX、DOC、DOCX、PNG、JPG 文件。
示例:-p /path/to/file.pdf 指定一个 PDF 文件。-o, --output-dir PATH
指定输出目录(必填),解析后的结果会保存到这个目录。
示例:-o /path/to/output 表示输出到指定文件夹。-m, --method [ocr|txt|auto]
选择解析 PDF 的方法:- ocr:使用 OCR 技术提取 PDF 内容,适用于扫描件或图片类 PDF。
- txt:仅适用于基于文本的 PDF,性能优于 OCR,但无法处理图片类内容。
- auto:自动选择最佳方法(ocr 或 txt),默认值。
示例:-m ocr 表示强制使用 OCR 方法。
-l, --lang TEXT
指定 PDF 的语言(可选),以提高 OCR 准确性。语言需使用缩写形式,参考 PaddleOCR 文档中的语言列表(例如 en 表示英语,ch 表示中文)。
示例:-l ch 表示指定中文。-d, --debug BOOLEAN
启用调试模式,输出详细的运行日志(默认是关闭)。
示例:-d true 开启调试。-s, --start INTEGER
指定 PDF 解析的起始页,从第 0 页开始计数。
示例:-s 2 表示从第 3 页开始解析。-e, --end INTEGER
指定 PDF 解析的结束页,从第 0 页开始计数。
示例:-e 5 表示解析到第 6 页结束。--help
显示帮助信息(即上述内容)并退出。
示例
magic-pdf -p {some_pdf} -o {some_output_dir} -m auto
- -p {some_pdf}:指定输入的 PDF 文件路径,例如 document.pdf。
- -o {some_output_dir}:指定输出目录,例如 /output/folder。
- -m auto:使用自动模式解析 PDF,工具会根据 PDF 内容选择 ocr 或 txt 方法。
2.API
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod
# args
pdf_file_name = "abc.pdf" # replace with the real pdf path
name_without_suff = pdf_file_name.split(".")[0]
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# read bytes
reader1 = FileBasedDataReader("")
pdf_bytes = reader1.read(pdf_file_name) # read the pdf content
# proc
## Create Dataset Instance
ds = PymuDocDataset(pdf_bytes)
## inference
if ds.classify() == SupportedPdfParseMethod.OCR:
infer_result = ds.apply(doc_analyze, ocr=True)
## pipeline
pipe_result = infer_result.pipe_ocr_mode(image_writer)
else:
infer_result = ds.apply(doc_analyze, ocr=False)
## pipeline
pipe_result = infer_result.pipe_txt_mode(image_writer)
### draw model result on each page
infer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))
### get model inference result
model_inference_result = infer_result.get_infer_res()
### draw layout result on each page
pipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))
### draw spans result on each page
pipe_result.draw_span(os.path.join(local_md_dir, f"{name_without_suff}_spans.pdf"))
### get markdown content
md_content = pipe_result.get_markdown(image_dir)
### dump markdown
pipe_result.dump_md(md_writer, f"{name_without_suff}.md", image_dir)
### get content list content
content_list_content = pipe_result.get_content_list(image_dir)
### dump content list
pipe_result.dump_content_list(md_writer, f"{name_without_suff}_content_list.json", image_dir)
### get middle json
middle_json_content = pipe_result.get_middle_json()
### dump middle json
pipe_result.dump_middle_json(md_writer, f'{name_without_suff}_middle.json')
运行后
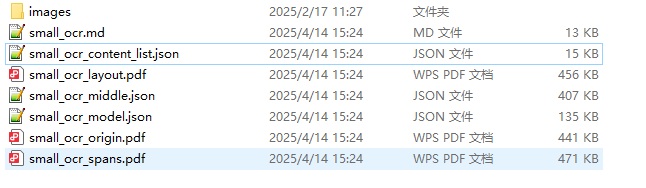
pdf识别的图片全部保存在images文件夹中
下面几个文件是识别后的结果,大家可以按需使用。


















 2565
2565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









