






(未完待续,逐步翻译、校对中)
文章目录
内容介绍
- 介绍流行的大语言模型(LLMs)
- 介绍LLM在下游任务上的调参方法
- 介绍LLM的prompt
- 介绍LLM在task-oriented dialogue system(TOD)中的应用
- 介绍LLM在open-domain dialogue system(ODD)中的应用
1. 流行的大语言模型(LLMs)
2. LLM在下游任务上的调参方法
3. LLM的prompt
Prompt engineering在助力PLMs(Pre-training Language Models)理解给定任务这一领域已备受瞩目。Prompt engineering划分为两种方法:提示调优(Prompt Tuning)和无调优提示(Tuning-free Prompting),此内容将在本节予以探讨。
3.1 提示调优(Prompt Tuning)
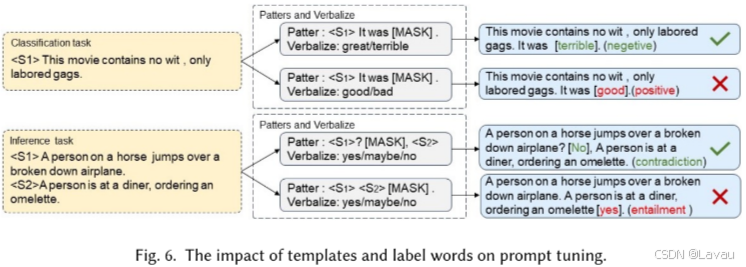
提示调优(Prompt Tuning)包含对预训练模型的参数进行修改,或者对额外的与提示相关的参数加以调整,以强化预训练模型对下游任务的适应能力。在这一方面,一种显著的方法是“模式 - 言语化对”(Pattern-Verbalizer-Pair,PVP)结构,其最初由[63]提出。后续的提示调优方法在很大程度上均基于 PVP 框架。如图 6 所示,高 等人[64]已经证实,模板和标签的选择能够导致最终精度出现极大的差异。故而,当前的研究主要聚焦于如何选择或构建恰当的模式和言语化器。提示的设计可归类为离散提示(discrete prompt)和连续提示(continuous prompt)。
3.1.1 离散提示( Discrete Prompt)
先前的工作致力于对离散提示(亦称为硬提示,hard prompt)的探究,其通常对应于可读的语言短语。在训练期间,离散模板的词嵌入保持恒定,不会向大语言模型(LLMs)引入任何新参数。在以下章节中,我们将对为此目的所提出的若干方法进行详尽概述:
3.1.1.1 Pattern-Exploiting Training,PET
Pattern-Exploiting Training,PET [65]通过手动生成 PVP 内容 p = (P, v) 来构建提示集,其中 P 是一个以 x 为输入并输出一个恰好包含一个掩码标记的短语或句子 P(x) ∈ V* 的函数,v 是一个从每个标签到掩码语言模型词汇表 M 中单词的单射函数 L → V。PET 可表述为:

其中,
𝑠
𝑝
𝑠_𝑝
sp 为标签 𝑙 ∈ L 的得分,
𝑞
𝑝
𝑞_𝑝
qp 为使用 softmax 得到的标签上的概率分布。接着,
𝑞
𝑝
𝑞_𝑝
qp (𝑙 | 𝑥) 与真实(独热编码)之间的交叉熵被用作在 p 中对 𝑀 进行微调的损失函数。
3.1.1.2 LM-BFF
找到合适的提示既繁琐又容易出错,这既需要领域专业知识,又需要对自然语言处理(NLP)的理解。即便投入了大量精力,手动生成的提示也很可能并非最优。因此,LM-BFF [64] 会自动生成提示,其中包括通过粗略的强力搜索来确定最佳的工作标签词,以及利用 T5 模型自动生成模板 [18]。给定一个固定的模板 𝑇 (𝑥),基于初始 𝐿 按照其条件似然构建一个包含前 𝑘 个词汇词的精简集合
𝑉
𝑐
𝑉_𝑐
Vc ⊂ 𝑉 ,可以表述为:
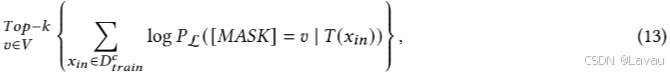
其中
𝑃
L
𝑃_L
PL 表示 L 的输出概率分布。
3.1.1.3 Prompt Tuning with Rules,PTR
规则提示微调(Prompt Tuning with Rules,PTR)[66] 能够应用逻辑规则将少量人工创建的子提示自动组合为最终的特定任务提示。以relation classification(关系分类)为例,给定一个句子 𝑥 = {…
𝑒
𝑠
𝑒_𝑠
es…
𝑒
𝑜
𝑒_𝑜
eo…} ,其中
𝑒
𝑠
𝑒_𝑠
es 和
𝑒
𝑜
𝑒_𝑜
eo 分别为subject entity(主体实体)和object entity(客体实体),
𝑒
𝑠
𝑒_𝑠
es 和
𝑒
𝑜
𝑒_𝑜
eo 的子提示模板和标签词集可以形式化为:
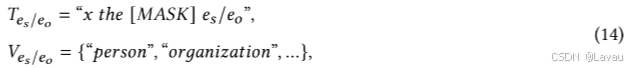 而
𝑒
𝑠
𝑒_𝑠
es 与
𝑒
𝑜
𝑒_𝑜
eo 之间关系的子提示可以形式化为:
而
𝑒
𝑠
𝑒_𝑠
es 与
𝑒
𝑜
𝑒_𝑜
eo 之间关系的子提示可以形式化为:
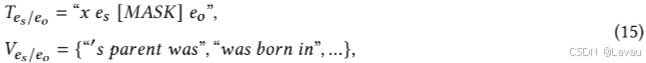
通过对这些子提示进行聚合,完整的提示如下:

PTR 的最终学习目标在于实现最大化 :
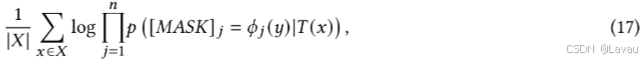
其中,Font metrics not found for font: . 的作用是将类别 𝑦 映射至第 𝑗 个被掩码位置
[
𝑀
𝐴
𝑆
𝐾
]
𝑗
[𝑀𝐴𝑆𝐾]_𝑗
[MASK]j 的标签词集合
𝑉
[
𝑀
𝐴
𝑆
𝐾
]
𝑗
𝑉[𝑀𝐴𝑆𝐾]_𝑗
V[MASK]j 。
3.1.1.4 Knowledgeable Prompt-tuning,KPT
知识丰富的提示微调(Knowledgeable prompt-tuning,KPT)[67] 利用外部知识库(Knowledge Bases,KBs)为每个标签生成一组标签词。所扩展的标签词并非单纯互为同义词,而是涵盖了不同的粒度和视角,因而相比类名更加全面且无偏。接着,提出了改进方法来应对生成的标签词中的噪声。这保留了高质量的词,可用于对预训练语言模型(Pre-trained Language Models,PLMs)进行微调,并展现了上下文学习(In-context Learning,ICL)的有效性。
3.1.2 连续提示(Continuous Prompt)
并非创建可读的语言短语,连续提示(Continuous Prompt)将提示转换为连续向量。连续提示拥有自身的参数,这些参数能够依据来自下游任务的训练数据进行调整。
3.1.2.1 P-tuning
P-tuning [68] 是借助连续提示来达成提示微调的早期尝试。有别于离散提示中的可读模板,P-tuning 运用连续提示嵌入 𝑝𝑖 来构建提示模板:
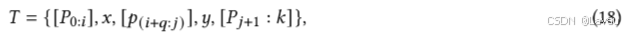
然后借助一个额外的嵌入函数 𝑓 : [𝑝𝑖] → ℎ𝑖 以将该模板映射为:
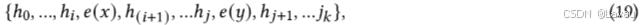
借助函数 𝑓,可通过更新嵌入集合
𝑃
𝑖
i
=
1
k
{𝑃_𝑖}^k_{i=1}
Pii=1k 来对任务损失函数进行优化。
3.1.2.2 Prefix Tuning
前缀微调(Prefix Tuning)[69]会冻结预训练语言模型(PLM)的参数,仅对前缀参数进行优化。由此,我们仅需为每个任务存储前缀,这使得前缀微调具有模块化和节省空间的特性。给定一个可训练的前缀矩阵𝑀𝜙以及一个由𝜃参数化的固定预训练语言模型,训练目标与完全微调的相同:
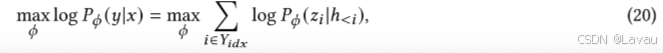
其中,ℎ<𝑖 为时间步 𝑖 处所有神经网络层的拼接。若 𝑖 ∈
𝑃
𝑖
𝑑
𝑥
𝑃_{𝑖𝑑𝑥}
Pidx ,则
h
𝑖
ℎ_𝑖
hi = Font metrics not found for font: . [𝑖, :] ,否则,
h
𝑖
ℎ_𝑖
hi = Font metrics not found for font: . (
𝑧
𝑖
𝑧_𝑖
zi, ℎ<𝑖) 。
Lester等人提出了提示调优(prompt tuning)[70],其可被视作前缀调优的一种简化。它极大地减少了参数的数量,并且首次表明仅使用提示调优也颇具竞争力。
3.1.2.3 P-tuning V2
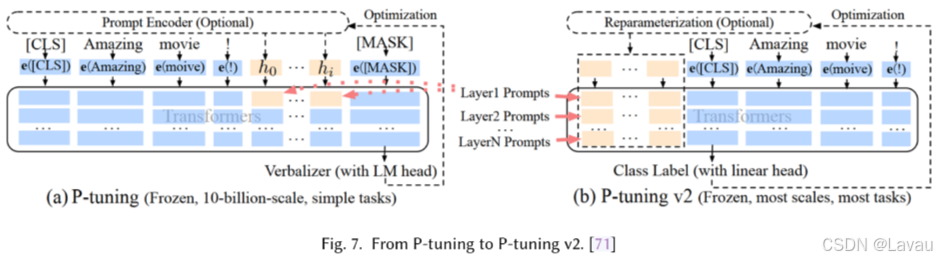
P-tuning v2 [71] 是 prefix-tuning [69] 与mixture of soft prompt [72] 的一种实现方式。如图 7 所示,与 P-tuning 相较而言,它不仅拥有更多可调节的任务特定参数(从 0.01% 到 0.1%-3%),能够在保持参数高效的同时允许每个任务具有更大的容量,而且还向更深的层添加提示,对模型预测产生更直接的影响。P-tuning v2 在所有规模下始终与微调相当,但与微调相比仅需要 0.1%的任务特定参数,这证明提示微调能够有效地协助预训练语言模型(PLMs)适应下游任务。
3.2 无调优提示(Tuning-free Prompting)
4. LLM在task-oriented dialogue system(TOD)中的应用
TOD 系统通过交互式对话协助用户达成特定领域相关的目标,诸如酒店预订或餐厅查询。鉴于其显著的效用,近年来该技术已引起研究人员日益增多的关注。总体而言,TOD 可分为基于管道的 TOD (pipeline-based TOD)和端到端的 TOD(end-to-end TOD)。在本节中,我们将对基于 LLM 的 TOD (LLM-based TOD)进行全面介绍。
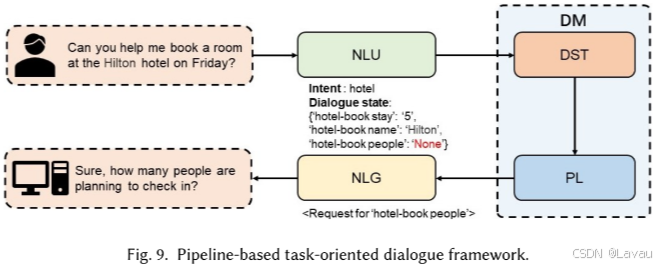
如图 9 所示,基于管道的 TOD 系统包含四个相互连接的模块:(1)NLU,用于提取用户意图和填充槽位;(2)对话状态跟踪(Dialogue State Tracking,DST),这是基于管道的 TOD 中的关键模块,用于依据 NLU 模块的输出和对话的历史输入来跟踪当前回合的对话状态;(3)策略学习(Policy Learning,PL),根据 DST 模块生成的对话状态确定后续动作;(4)自然语言生成(NLG),是基于管道的 TOD 系统中的最后一个模块,将 PL 模块生成的对话动作转化为可理解的自然语言。对话管理器(Dialogue Manager,DM)是基于管道的 TOD 系统的中央控制器,由 DST 模块和 PL 模块构成。
4.1 Pipeline-based Methods
在基于管道的 TOD 系统中,由于每个模块都是独立训练的,任何模块在适应子任务时的失败都可能致使整个系统表现极差。与此同时,鉴于基于管道的 TOD 系统是依次解决所有子任务的,模块之间的误差会不断累积,从而引发错误传播问题。不过,因为基于管道的 TOD 系统中的每个模块都是单独运作的,能保证输入和输出的一致性,所以在该系统中对单个模块进行替换就变得较为便捷。随着 PLMs 的发展,通过不同方式微调的大规模语言模块能够轻易获取并无缝集成到 TOD 系统中,这使得用户能够轻松地让系统适应目标领域中的子任务。
4.1.1 Natural Language Understanding,NLU
NLU 模块从用户提供的自然语言输入中识别并提取诸如用户意图和槽值之类的信息。一般而言,NLU 模块的输出如下:𝑈 𝑛 = (𝐼𝑛, 𝑍𝑛),其中 𝐼𝑛 为检测到的用户意图,𝑍𝑛 为槽值对。例如,在餐厅推荐任务中,用户意图为“find-restaurant”,且领域为“restaurant”。槽填充可被视作一个序列分类任务(sequence classification task)。例如,用户输入一条消息:“I am looking for a place to eat in the east that is expensive.”,NLU 模块读取此输入并生成以下槽值对:{restaurant-area: east, restaurant-pricerange: expensive}。
Intent detection。基于深度学习的方法[85, 86]被广泛用于解决意图检测任务。尤为突出的是,众多基于神经网络的方法展现出了颇具前景的性能。然而,随着大语言模型(LLMs)的发展,众多研究人员将 LLMs 应用于解决 TOD 任务,且诸多方法达成了出色的性能表现。Comi 等人提出了一种基于预训练 BERT 模型的基于管道的意图检测方法[87](Daniele Comi et al. Zero-shot-bert-adapters: a zero-shot pipeline for unknown intent detection. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 650–663, 2023.)。他们首先运用基于微调后的 BERT 模型的零样本方法提取出一组潜在意图,作为话语意图分类问题的候选类别。Parikh 等人[88](Soham Parikh et al. Exploring zero and few-shot techniques for intent classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 744–751, Toronto, Canada, July 2023. Association for Computational Linguistics.)利用带有提示的 GPT-3 和 Flan-T5-XXL 模型来执行意图分类任务。他们还使用 PEFT 方法对 LLMs 进行微调,并在意图分类任务中展示出了杰出的性能。为解决仅通过 LLMs 的上下文提示增强无法提升性能这一问题,Lin 等人[89](Yen-Ting Lin et al. Selective in-context data augmentation for intent detection using pointwise V-information. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 1463–1476, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics.)引入了一种基于点式 V 信息的新颖方法,并成功改进了基于 LLMs 的意图检测任务的性能。
填槽任务为每个单词子序列贴上不同的标签。因此,填槽任务可被视作序列分类任务。Coope 等人提出了 Span-ConveRT [90](Samuel Coope et al. Span-ConveRT: Few-shot span extraction for dialog with pretrained conversational representations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 107–121, Online, July 2020. Association for Computational Linguistics.),这是一种用于对话填槽任务的模型,它通过整合大型预训练对话模型中编码的会话知识,在少样本场景中展现出了卓越的性能。Siddique 等人 [91] (AB Siddique, Fuad Jamour, and Vagelis Hristidis. Linguistically-enriched and context-awarezero-shot slot filling. In Proceedings of the Web Conference 2021, pages 3279–3290, 2021.)提出了一种零样本填槽模型 LEONA,该模型利用预训练的大语言模型(LLMs)来提供基于单词使用上下文的上下文化单词表示,能够捕捉单词基于其使用语境的复杂句法和语义特征,并使用这些单词表示为每个单词生成特定槽位的预测。
Joint intent detection and slot filling。一些研究将意图检测和填槽整合进一个联合的意图检测与填槽模块,此举促进了意图检测任务与填槽任务之间的双向信息共享。Chen 等人[92](Bert for joint intent classification and slot filling)基于 NLU 数据集对大语言模型(LLM)进行微调,他们的实验结果表明,基于微调后的大语言模型的联合 NLU 模块的性能优于分离的 NLU 模块以及基于未调优的大语言模型的 NLU 模块。Nguyen 等人[93](Hoang Nguyen et al. CoF-CoT: Enhancing large language models with coarse-to-fine chain-of-thought prompting for multi-domain NLU tasks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12109–12119, Singapore, December 2023. Association for Computational Linguistics.)提出了 CoF-CoT 方法,该方法将 NLU 任务分解为多个推理步骤。大语言模型能够通过学习获取和利用关键概念来增强其解决 NLU 任务的能力,从而在不同粒度上提升对 NLU 任务的处理能力。
4.1.2 Dialogue State Tracking,DST
如图 9 所示,DST 和 PL 构成了对话管理器(DM)模块,这是基于管道的 TOD 系统的中央控制器。作为 DM 模块的第一个模块,DST 涉及通过预测当前回合 𝑡 的槽值对来跟踪当前的对话状态。在 TOD 任务中,对话状态 B𝑡 记录了直到回合 𝑡 为止的整个对话历史。DST 模块以槽值对的形式记录用户的目标,例如,在酒店预订任务中,回合 𝑡 的对话状态为
B
𝑡
=
(
h
𝑜
𝑡
𝑒
𝑙
−
𝑏
𝑜
𝑜
𝑘
𝑠
𝑡
𝑎
𝑦
,
5
)
,
(
h
𝑜
𝑡
𝑒
𝑙
−
𝑏
𝑜
𝑜
𝑘
𝑑
𝑎
𝑦
,
𝐹
𝑟
𝑖
𝑑
𝑎
𝑦
)
,
(
h
𝑜
𝑡
𝑒
𝑙
−
𝑏
𝑜
𝑜
𝑘
𝑛
𝑎
𝑚
𝑒
,
𝐻
𝑖
𝑙
𝑡
𝑖
𝑜
𝑛
)
B_𝑡 = (ℎ𝑜𝑡𝑒𝑙 − 𝑏𝑜𝑜𝑘𝑠𝑡𝑎𝑦, 5), (ℎ𝑜𝑡𝑒𝑙 − 𝑏𝑜𝑜𝑘𝑑𝑎𝑦, 𝐹𝑟𝑖𝑑𝑎𝑦), (ℎ𝑜𝑡𝑒𝑙 − 𝑏𝑜𝑜𝑘𝑛𝑎𝑚𝑒, 𝐻𝑖𝑙𝑡𝑖𝑜𝑛)
Bt=(hotel−bookstay,5),(hotel−bookday,Friday),(hotel−bookname,Hiltion)。
DST方法可以分为静态语义DST模型和动态语义DST模型。静态语义DST模型从预先定义的槽值对预测对话状态,而动态语义DST模型则从未固定的槽值对预测对话状态。提出了许多静态语义DST模型 [94-96],然而,大多数基于LLM的DST方法基于动态语义DST模型,它跟踪来自未固定槽值对的对话状态。例如,SAVN和MinTL [97,98] 专注于创建LLM可以有效应用的方法或框架。这些方法实现了具有竞争力的结果,并允许用户将预先训练的序列到序列模型插入到DST任务中。胡等人[99]提出了基于ICL的零样本和少数样本DST框架IC-DST。IC-DST从已标记对话中检索几个最相似的回合作为提示,并将其作为输入喂入LLMs,以生成当前回合的对话状态变化。冯等人提出了基于LLaMa模型的DST框架LDST[100]。LDST首先创建一个指令微调数据集,并使用该数据集微调LLaMa模型。随后,LDST通过构建并输入输出提示来指导LLaMa生成准确的响应。
4.1.3 Policy Learning,PL
作为 DM 模块的第二部分,PL 模块承担着根据当前回合 t 中来自 DST 模块的对话状态 B𝑡 生成恰当的下一步系统动作的责任。因此,PL 模块的任务可被公式化为学习一个映射函数:
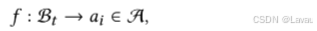
其中,A 是动作集
A
=
𝑎
1
,
.
.
.
,
𝑎
𝑛
A = {𝑎_1,..., 𝑎_𝑛}
A=a1,...,an 。
在 TOD 系统中,PL 模块可从两个层面加以探讨:对话行为(DA)层面和单词层面的对话策略。DA 层面对话策略的目标是生成诸如“inform”:(“people”,“area”)之类的对话行为,而后在自然语言生成(NLG)模块中转换为可读的输出。强化学习方法[101 - 103]在 DA 层面的 PL 任务中被广泛应用。单词层面的对话 PL 模块将 PL 与自然语言生成(NLG)模块相结合,因为它通过选择一连串的单词作为可读的句子来执行一系列动作。如此一来,单词层面的对话 PL 任务可被视作一个序列到序列的生成任务。鉴于大语言模型(LLMs)在解决序列到序列任务时表现出色,众多基于 LLM 的单词层面的对话 PL 方法被提出。Chen 等人[104]将 BERT 模型用作解码器。Li 等人[105]将 BERT 模型用作上下文感知检索模块。众多研究者[106 - 108]对 GPT - 2 模型进行微调,并将微调后的模型应用于解决单词层面的对话 PL 任务。Ramachandran 等人[109]对 BART 进行微调,He 等人[110]对 UniLM 进行微调。Yu 等人[111]提出了一种基于提示的方法,通过提示大语言模型充当策略先验来解决 PL 任务。
4.1.4 Natural Language Generation,NLG
NLG(即数据到文本生成、文本到文本生成)是指为特定目的生成自然语言文本的过程。在基于管道的TOD系统中,NLG是最后一个模块,负责将PL模块生成的对话动作转换为可读的自然语言。例如,给定对话活动“Inform: (‘people’)”,NLG模块将其转换为可读的句子“有多少人打算办理入住手续?”传统的NLG模块基于管道结构,可以分为文本规划模块、句子规划模块和语言规划模块[112]。随着深度学习方法的发展,研究人员在最近的研究工作中引入了基于神经网络的端到端NLG方法[113-115]来解决NLG任务。由于管道式TOD系统的NLG任务是序列到序列任务,可以有效地由LLMs解决,因此许多最近的研究工作提出了使用LLMs解决NLG任务的方法。例如,彭等人提出了SC-GPT [116]模型,该模型在大量标注的NLG语料库上预训练,并在具有有限域标签的数据集上微调以适应新的域。陈等人[117] 对 PLMs 的其他参数进行微调,并保持预训练的词嵌入不变,以增强模型的泛化能力。 巴赫蒂等人[118] 将基于 BERT 的分类器集成到端到端的 NLG 系统中,以从候选响应中识别出最佳答案。 钱等人[119] 利用前缀微调方法来提高 GPT-2 在处理 NLG 任务方面的性能。
4.2 End-to-End
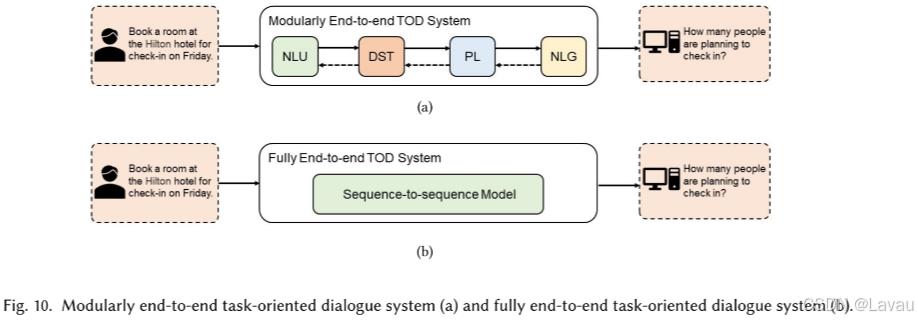
如图 10 所示,端到端的 TOD 系统可划分为模块化端到端 TOD 系统(modularly end-to-end TOD systems)和完全端到端 TOD 系统(fully end-to-end TOD systems)。尽管模块化端到端 TOD 系统通过独立的模块生成响应,这与基于管道的 TOD 系统相似,然而模块化端到端 TOD 系统会同时训练所有模块并优化所有模块的参数。端到端的 TOD 系统基于相应的知识库 KB 以及对话历史
H
=
(
𝑢
1
,
𝑠
1
)
,
(
𝑢
2
,
𝑠
2
)
,
.
.
.
,
(
𝑢
𝑛
−
1
,
𝑠
𝑛
−
1
)
H = (𝑢_1, 𝑠_1), (𝑢_2, 𝑠_2),..., (𝑢_{𝑛−1}, 𝑠_{𝑛−1})
H=(u1,s1),(u2,s2),...,(un−1,sn−1)生成对话系统响应 S ,其中 𝑢 为用户输入, 𝑠 为系统回答:

LLMs在 LLMs 在 ODD 任务中取得了显著成就。然而,由于缺乏大量用于 TOD 任务的训练数据集,与训练完全基于 LLM 的端到端 TOD 模型相关的研究仍然相对较少。因此,大多数现有的基于 LLM 的端到端 TOD 方法都是基于模块化的端到端 TOD 系统。
简单任务导向对话(SimpleTOD)[107](Ehsan Hosseini-Asl et al. A simple language model for task-oriented dialogue. Advances in Neural Information Processing Systems, 33:20179–20191, 2020)是一种基于单个因果语言模型的端到端 TOD 方法,该模型在所有子任务上接受训练。SimpleTOD 在训练 LLM 时所采用的方法,是利用此类模型解决 TOD 任务的成功范例。给定
X
t
=
[
H
t
,
B
t
,
D
t
,
A
t
,
S
t
]
X_t = [H_t, B_t, D_t, A_t, S_t]
Xt=[Ht,Bt,Dt,At,St],其中
H
t
H_t
Ht、
B
t
B_t
Bt、
D
t
D_t
Dt、
A
t
A_t
At 和
S
t
S_t
St 依次是在时刻 t 时对话历史 H、信念状态 B、数据库查询结果 D、对话动作 A 和系统回答 S 的值。在数据集
D
=
x
1
,
.
.
.
,
x
∣
D
∣
D = {x^1,..., x^{|D|}}
D=x1,...,x∣D∣ 上的联合概率 p(x) 和负对数似然 L(D) 可以表述为:
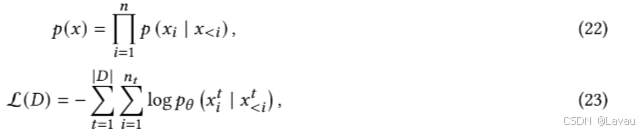
其中,
𝑛
𝑡
𝑛_𝑡
nt 为
𝑥
𝑡
𝑥^𝑡
xt 的长度,𝜃 为神经网络中的参数,该网络经过训练以最小化 L(𝐷) 。
彭等人提出了 Soloist [120] (Soloist: Building task bots at scale with transfer learning and machine teaching,ACL 2021),这是一种利用迁移学习和机器教学来构建端到端 TOD 系统的方法。Soloist 的训练过程与 SimpleTOD 颇为相似。然而,Soloist 对每个对话轮次的数据格式进行了优化,不再需要对话动作 A 。训练数据中的每个对话轮次均可表示为 𝑥 = [H, B, D, S] 。Soloist 的完整预训练目标被划分为三个子任务:信念预测、基于基础的响应生成和基于基础的响应生成。给定信念状态序列的长度
𝑇
B
𝑇_B
TB 以及轮次 𝑡 之前的标记 𝑡 B<𝑡 ,预测信念状态的目标定义为:
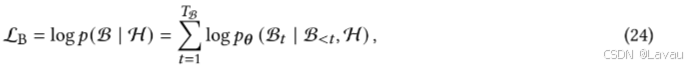
其中,𝑝(𝑥)为联合概率,𝜃为待学习的参数。
同样,给定去词汇化响应
S
=
[
S
1
,
⋅
⋅
⋅
,
S
𝑇
S
]
S = [S_1, · · ·, S_{𝑇_S}]
S=[S1,⋅⋅⋅,STS] 的长度
𝑇
S
𝑇_S
TS ,相应的训练目标可表述为:
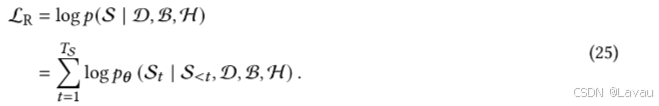
令 𝑥 为正样本,𝑥′ 为负样本,Soloist 采用应用于特征的二元分类器来预测序列中的项目是否对应(𝑦 = 1)或不对应(𝑦 = 0)。对比目标为交叉熵,定义为:
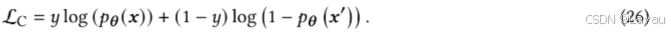
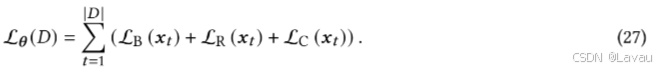
苏等人提出了一种用于任务导向对话的即插即用模型(PPTOD)[122] (Yixuan Su et al. Multi-task pre-training for plug-and-play task-oriented dialogue system. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4661–4676, Dublin, Ireland, May 2022. Association for Computational Linguistics.),这是一种模块化的端到端 TOD 模型。PPTOD 借助四个与 TOD 相关的任务进行预训练,并使用提示来提升语言模型的性能。值得一提的是,PPTOD 的学习框架使其能够在部分标注的数据上进行训练,这显著降低了手动创建数据集的成本。
半监督预训练对话模型(SPACE)由阿里巴巴达摩院的对话人工智能团队提出,包含一系列预训练语言模型(PLMs)[110, 123, 124]。GALAXY(SPACE-1)[110]是一个模块化的端到端任务导向对话(TOD)模型,它通过半监督学习,从有限的有标记对话和大量的无标记对话语料库的组合中明确获取对话策略。先前的工作主要侧重于增强自然语言理解(NLU)和自然语言生成(NLG)模块的性能,而 GALAXY 通过在预训练期间引入新的对话动作预测任务来优化对话策略(PL)模块的性能。这些方法提高了 GALAXY 在解决 TOD 任务方面的性能,并使 GALAXY 相较于其他模型具有更出色的少样本能力。
SPACE-2 [123] (SPACE-2: Tree-structured semi-supervised contrastive pre-training for task-oriented dialog understanding,COLING,2022)为一个在有限的有标注对话及大规模未标注对话语料库上进行预训练的树形对话模型。在传统方法中,正样本仅被定义为具有相同标注的实例,而其余所有实例皆被归为负样本。这种分类方式忽略了不同示例在一定程度上可能存在共同语义相似性的可能。故而,SPACE-2 框架依据各自的数据结构为各类数据集构建树结构,此结构被称为语义树结构(STS)。接着,SPACE-2 度量不同有标注对话之间的相似度,并汇总多个得分的输出。在此方法中,所有有标注数据均被视作具有软分数的正例,而非先前方法中常用的二元分数(0 或 1)。
SPACE-3 [124] (Unified dialog model pre-training for task-oriented dialog understanding and generation,SIGIR,2022)是最为先进的预训练模块化端到端 TOD 模型之一。SPACE-3 框架凝聚了 SPACE-1 和 SPACE-2 的成果,引入 STS 以统一不同数据集间不一致的标注模式,并为每个组件设计了专门的预训练目标。SPACE-3 采用 𝑝 𝑢 = 𝑝 1 𝑢 , 𝑝 2 𝑢 , . . . , 𝑝 𝐴 𝑢 𝑝^𝑢 = {𝑝^𝑢_1, 𝑝^𝑢_2,..., 𝑝^𝑢_𝐴} pu=p1u,p2u,...,pAu 和 𝑝 𝑜 = 𝑝 1 𝑜 , 𝑝 2 𝑜 , . . . , 𝑝 𝐵 𝑜 𝑝^𝑜 ={𝑝^𝑜_1, 𝑝^𝑜_2,..., 𝑝^𝑜_𝐵} po=p1o,p2o,...,pBo 来代表对话理解提示序列和策略提示序列,其中 𝐴 和 𝐵 为提示序列的长度。随后, 𝑝 𝑢 𝑝^𝑢 pu 和 𝑝 𝑜 𝑝^𝑜 po 被用于提取语义,并助力在 TOD 系统中传递任务流。

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









