







使用Tensorflow和MNIST识别自己手写的数字
最近在学习神经网络相关的东西,发现有很多资料是Tensorflow教程上的内容,但是教程很多只是一个验证官方程序的过程。如何将官方程序变成自己可以利用的程序,网上似乎资料比较少,所以我就来介绍一下如何使用Tensorflow和MNIST搭建自己的手写识别算法,识别自己写的数字(比如下面我写的这个苍劲有力的3~~)。本文也参考了国外大神博客的内容。纯新手,之前在博客上收益良多,也希望能帮助和我一样刚刚起步的童鞋,大家多多指教。

内容如下:
- Tensorflow和MNIST简介
- CNN算法
- 训练程序
- 写数字,并用Opencv进行预处理
- 将图片输入网络进行识别
Tensorflow和MNIST简介
TensorFlow™ 是一个采用数据流图,用于数值计算的开源软件库。它是一个不严格的“神经网络”库,可以利用它提供的模块搭建大多数类型的神经网络。它可以基于CPU或GPU运行,可以自动使用GPU,无需编写分配程序。主要支持Python编写,但是官方说也有C++使用界面。
MNIST是一个巨大的手写数字数据集,被广泛应用于机器学习识别领域。MNIST有60000张训练集数据和10000张测试集数据,每一个训练元素都是28*28像素的手写数字图片。作为一个常见的数据集,MNIST经常被用来测试神经网络,也是比较基本的应用。
CNN算法
识别算法主要使用的是卷积神经网络算法(CNN)。
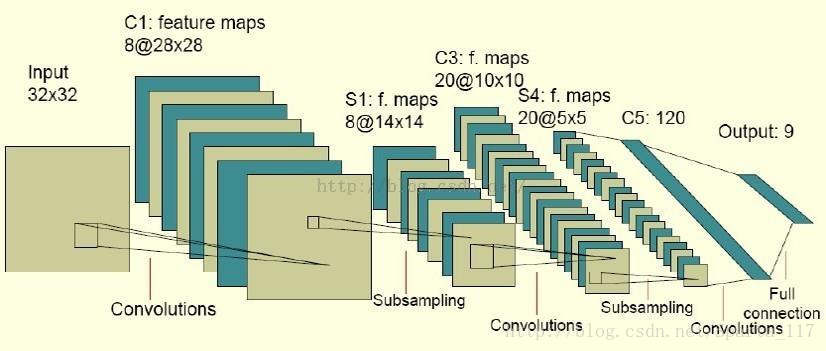
主要结构为:输入-卷积层-池化层-卷积层-池化层-全连接层-输出
卷积
卷积其实可以看做是提取特征的过程。如果不使用卷积的话,整个网络的输入量就是整张图片,处理就很困难。
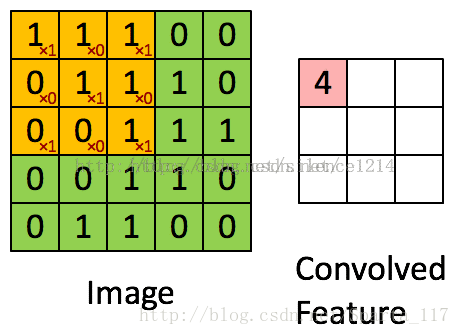
(这里使用了参考了别人博客中的内容,来源记不清了TAT)
假设图中绿色5*5矩阵为原图片,黄色的3*3矩阵就是我们的过滤器,即卷积核。将黄色矩阵和绿色矩阵被覆盖的部分进行卷积计算,即每个元素相乘求和,便可得到这一部分的特征值,即图中的卷积特征。
然后,向右滑动黄色的矩阵,便可继续求下一部分的卷积特征值。而滑动的距离就是步长。
池化
池化是用来把卷积结果进行压缩,进一步减少全连接时的连接数。
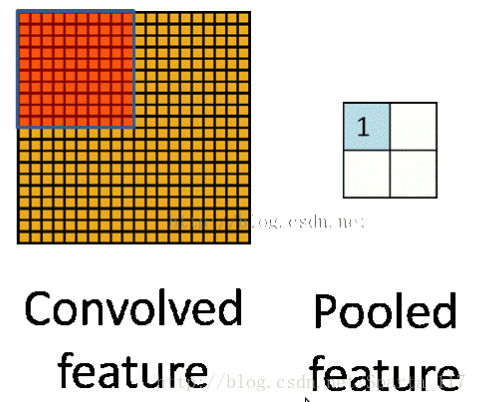
池化有两种:
一种是最大池化,在选中区域中找最大的值作为抽样后的值;
一种是平均值池化,把选中的区域中的平均值作为抽样后的值。
实现过程
1.训练程序
这里我就先把程序贴出来,主体和tensorflow教程上大致相同。值得注意的是其中的saver部分,将训练的权重和偏置保存下来,在评价程序中可以再次使用。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
import tensorflow as tf
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
sess.run(tf.global_variables_initializer())
y = tf.matmul(x,W) + b
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
for _ in range(1000):
batch = mnist.train.next_batch(100)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1562
1562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









