








一、 论文介绍
论文链接:http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
代码链接:https://gitcode.com/MCG-NKU/SCNet/
文章摘要:
CNN的最新进展主要致力于设计更复杂的架构来增强其表示学习能力。在本文中,我们考虑在不调整模型架构的情况下改进CNN的基本卷积特征转换过程。为此,我们提出了一种新的自校准卷积,通过内部通信显式扩展每个卷积层的视场,从而丰富输出特征。特别是,与使用小核(例如3 × 3)融合空间和通道信息的标准卷积不同,我们的自校准卷积通过一种新的自校准操作,自适应地在每个空间位置周围构建远程空间和通道间依赖关系。因此,它可以通过显式地结合更丰富的信息来帮助CNN生成更具判别性的表示。我们的自校准卷积设计简单而通用,可以很容易地应用于增加标准卷积层,而无需引入额外的参数和复杂性。大量的实验表明,当将我们的自校准卷积应用于不同的主干时,基线模型可以在各种视觉任务中得到显着改进,包括图像识别,目标检测,实例分割和关键点检测,而无需改变网络架构。我们希望这项工作可以为未来的研究提供一种有前途的方法来设计新的卷积特征变换,以改进卷积网络。
总结:作者设计了一个即插即用的自校准卷积模块来替代普通的卷积块,称为SC模块(Self-Calibrated Convolutions), 感受野更大,可以关注到更多的上下文信息;使用方便,可以像普通卷积模块一样使用,不需要引入多余参数,适用于多种任务。
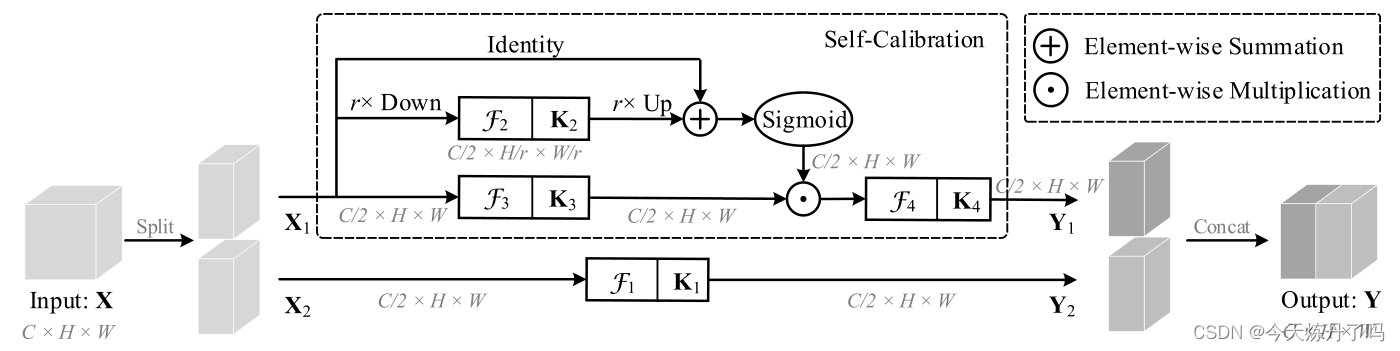
二、 加入到YOLOv8中
2.1 复制代码
复制代码粘到ultralytics->nn->modules->conv.py文件中,在顶部导入torch.nn.functional包,(torch.nn.functional as F),将代码粘贴于下方,并在__all__中声明,如下图所示:
import torch.nn.functional as F
__all__ = (
"Conv",
"Conv2",
"LightConv",
"DWConv",
"DWConvTranspose2d",
"ConvTranspose",
"Focus",
"GhostConv",
"ChannelAttention",
"SpatialAttention",
"CBAM",
"Concat",
"RepConv",
"SCConv",
)
class SCConv(nn.Module):
def __init__(self, inplanes, planes, stride, padding, dilation, groups, pooling_r, norm_layer):
super(SCConv, self).__init__()
self.k2 = nn.Sequential(
nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
eval(norm_layer)(planes),
)
self.k3 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
eval(norm_layer)(planes),
)
self.k4 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias=False),
eval(norm_layer)(planes),
)
def forward(self, x):
identity = x
out = torch.sigmoid(torch.add(identity, F.interpolate(self.k2(x), identity.size()[2:]))) # sigmoid(identity + k2)
out = torch.mul(self.k3(x), out) # k3 * sigmoid(identity + k2)
out = self.k4(out) # k4
return out

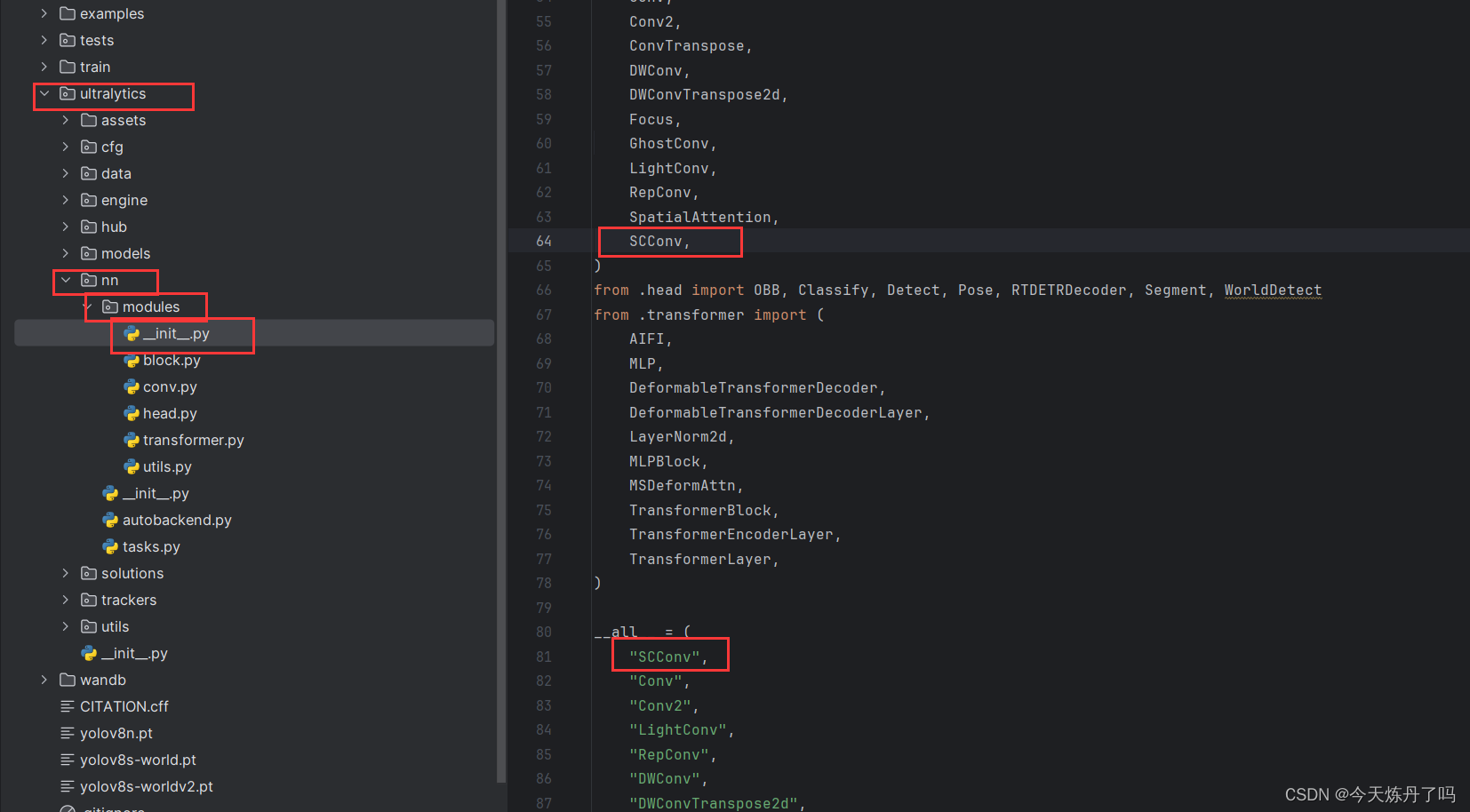
2.2 更改modules.__init__.py文件
打开ultralytics->nn->modules->__init__.py,在第64行与81行加入SCConv进行声明。
2.3 更改task.py文件
打开ultralytics->nn路径下的tasks.py文件,首先在第51行加入SCConv导入模块,然后在第928行(或其他合适的位置)加入下方代码:
elif m is SCConv:
c2 = args[0]
c1 = ch[f]
args = [c1, c2, *args[1:]]

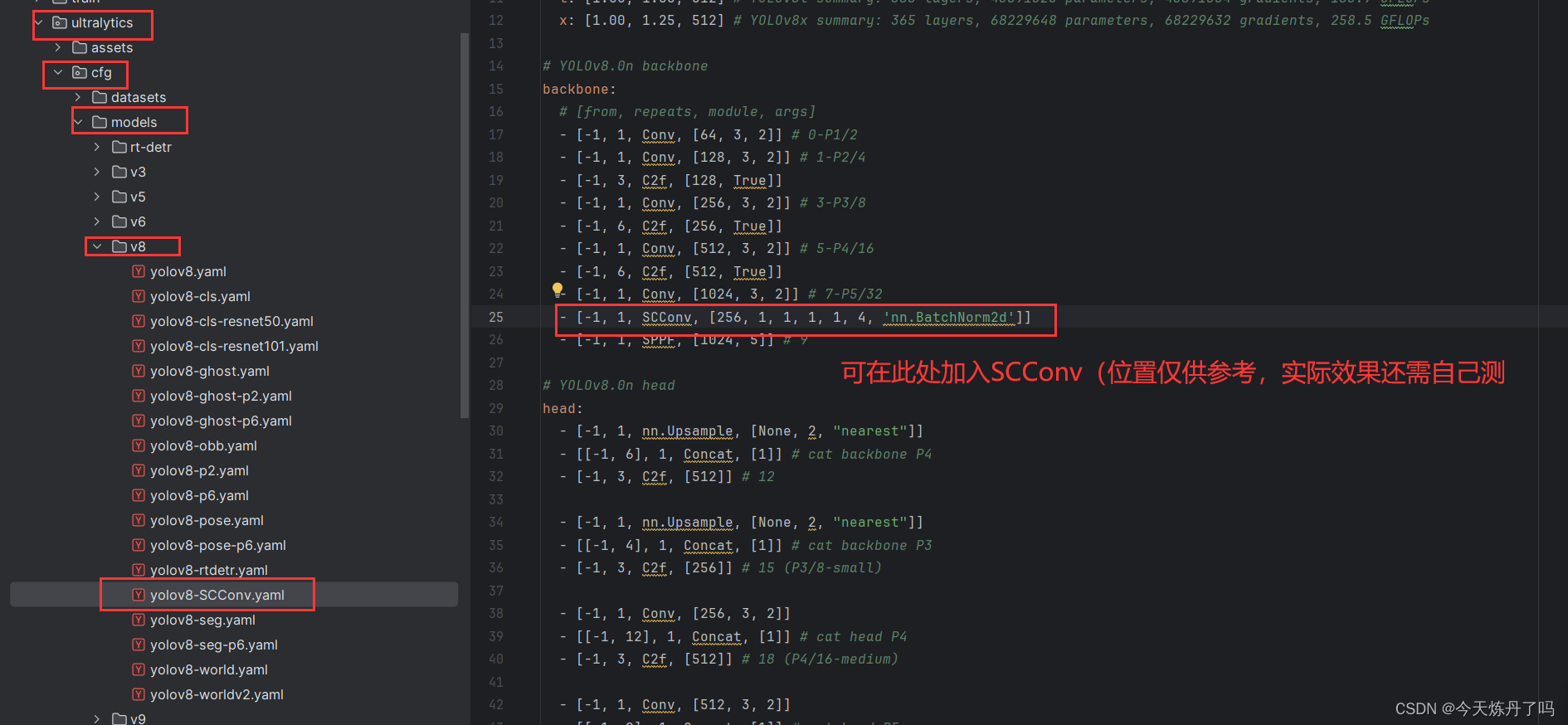
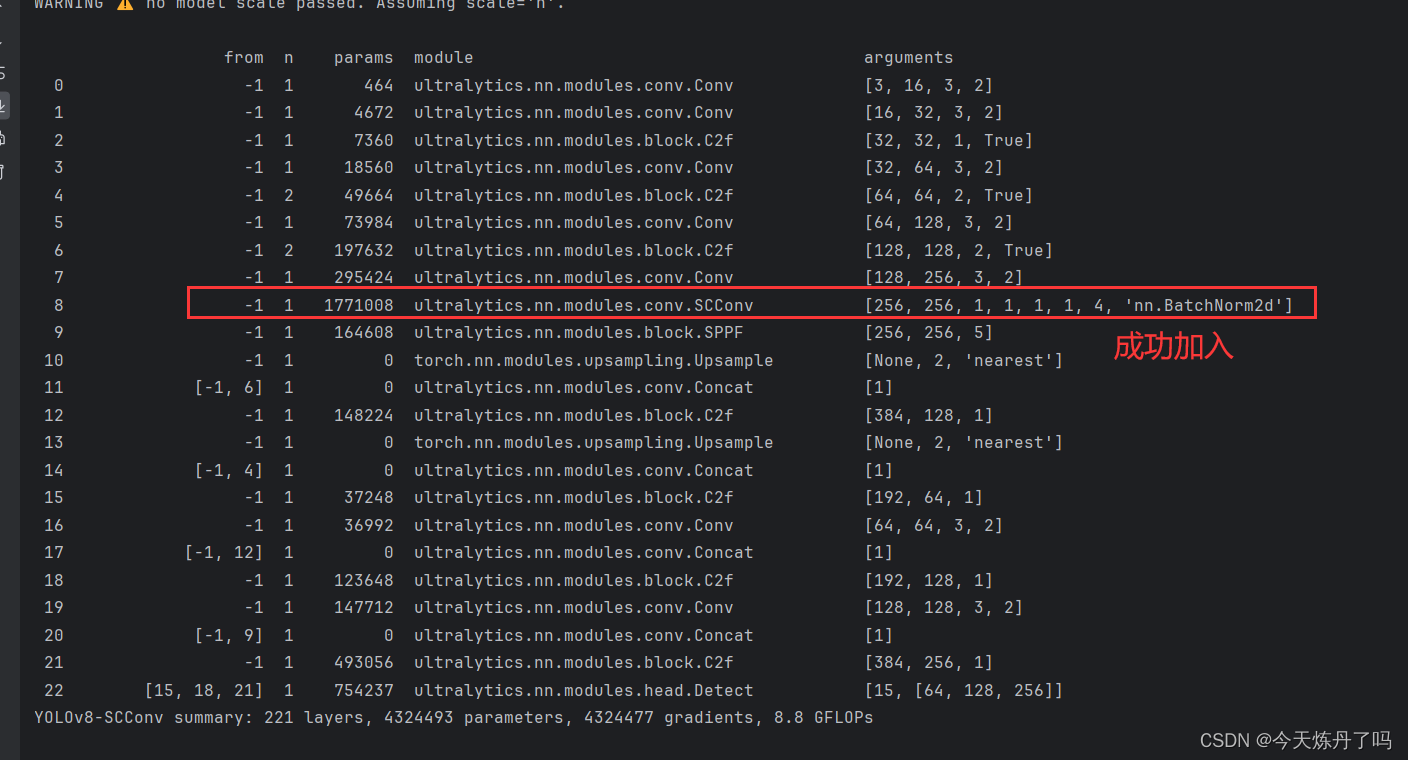
2.4 更改yaml文件
创建yaml文件,使用SCConv替换yaml文件中原有的Conv模块。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, SCConv, [256, 1, 1, 1, 1, 4, 'nn.BatchNorm2d']] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[21, 24, 27], 1, Detect, [nc]] # Detect(P3, P4, P5)
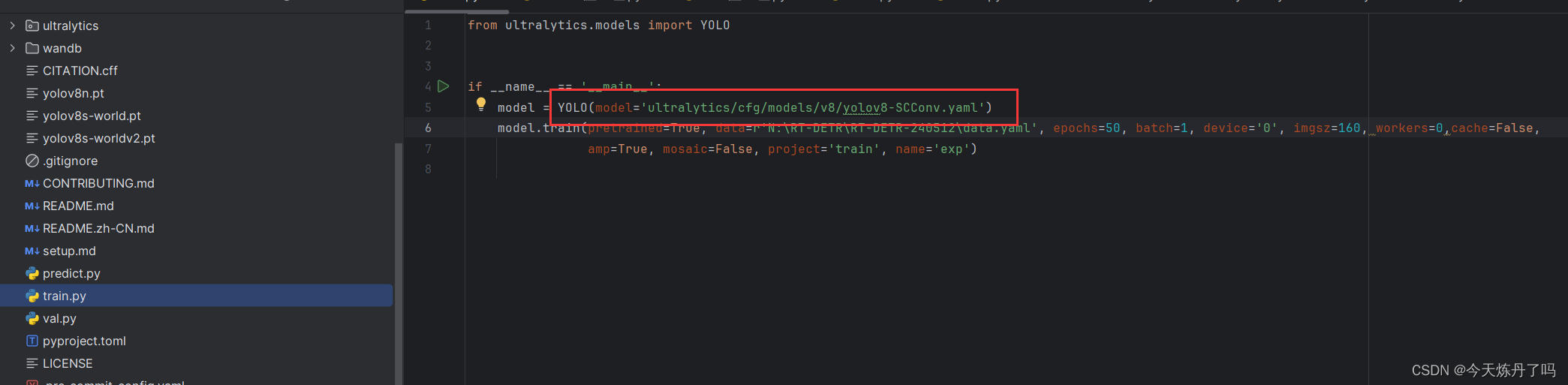
2.5 修改train.py文件
在train.py脚本中填入创建好的yaml路径,运行即可训练。
















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









