






论文地址:DiAD: A Diffusion-based Framework for Multi-class Anomaly Detection
代码地址:https://github.com/lewandofskee/DiAD
以下很多内容出自这个大佬,我只是想按我自己的理解整合一下。自用整理保存,转载商用请联系原博主!
 https://blog.csdn.net/qq_41204464/article/details/139233283
https://blog.csdn.net/qq_41204464/article/details/139233283目录
1. 像素空间自编码器(Pixel-space Autoencoder):
2. 潜在空间语义引导网络(Latent-space Semantic-Guided Network):
2.3 空间感知特征融合块SSF(Spatial-aware Feature Fusion Block):
4. 特征空间预训练特征提取器(Feature-space Pre-trained Feature Extractor):
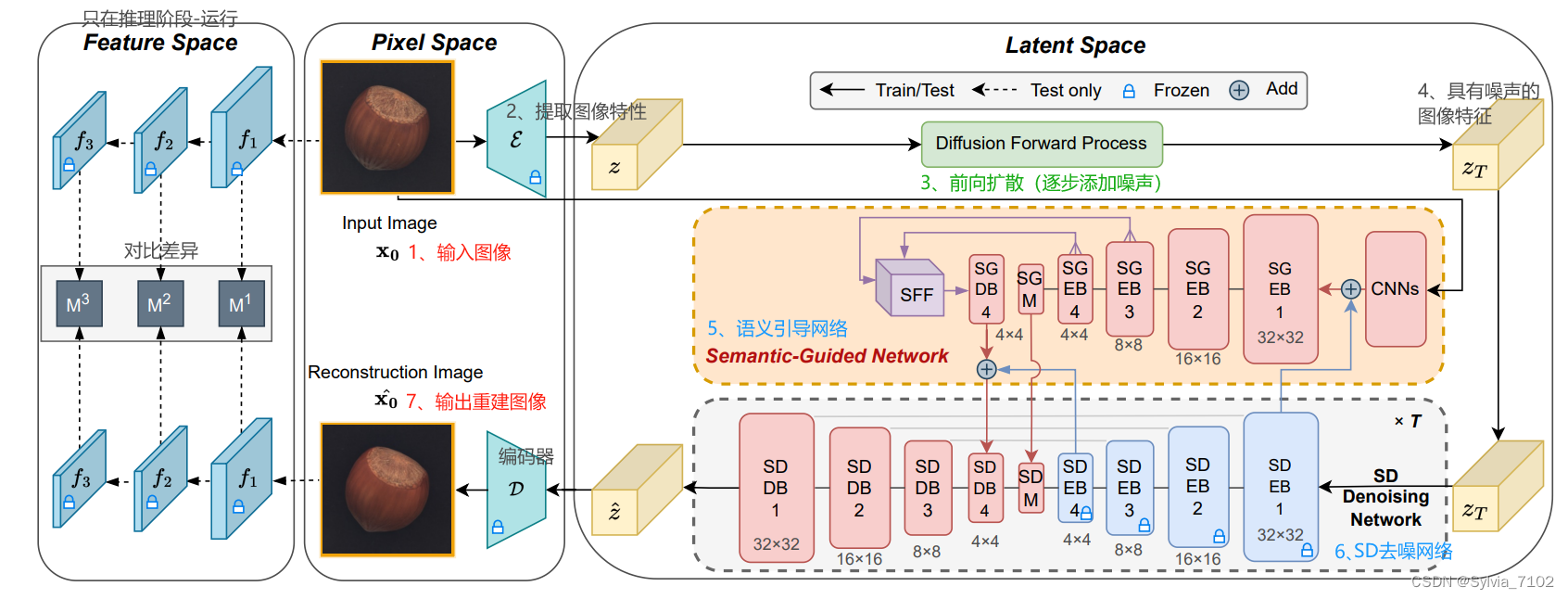
提出了一种基于扩散模型的多类别异常检测框架DiAD(Diffusion-based Anomaly Detection)。其核心方法旨在解决在复杂多类别环境中,异常检测时如何保持图像类别和像素级结构完整性的挑战。
DiAD框架通过结合像素空间自编码器、潜在空间语义引导网络、空间感知特征融合块和特征空间预训练特征提取器,构建了一个能够有效处理多类别异常检测问题的系统。通过保持图像的语义信息和像素级结构完整性,DiAD在多类别设置下展现出了优异的异常检测性能。
在MVTec-AD和VisA数据集上的实验结果表明,DiAD框架在异常检测和定位方面取得了显著效果,超过了现有最先进的方法。
(图出自开头提到的大佬)
一、网络结构
1. 像素空间自编码器(Pixel-space Autoencoder):
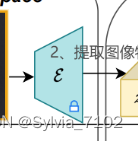
自编码器通常用于数据压缩和重构,通过编码器将输入数据压缩成低维表示(即潜在空间表示),再通过解码器将低维表示恢复成原始数据。在DiAD中,像素空间自编码器被用于初步的图像重构。
2. 潜在空间语义引导网络(Latent-space Semantic-Guided Network):
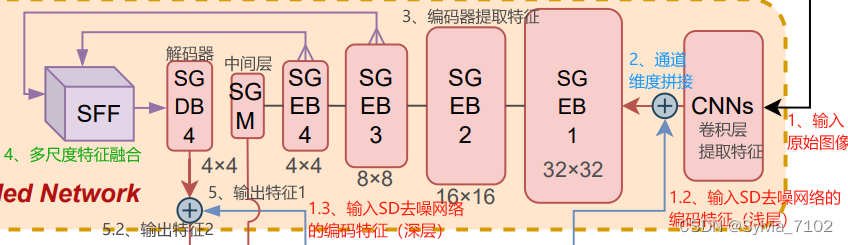
这是一个与稳定扩散的去噪网络相连接的网络,其目标是在重构异常区域时,保持原始图像的语义信息。
这意味着网络在修复或重构异常区域时,会尝试使修复后的区域与原始图像的语义上下文保持一致。
SG网络在不同尺度下处理噪声,并通过SFF模块融合特征,确保重建过程中保留语义信息。SG网络的设计有助于在多类别设置中,避免因为异常检测而破坏图像的类别信息。
包括一系列编码块SGEB和解码块SGDB、中间模块SGM、以及一个空间感知特征融合SFF模块。
输入变换:
- 输入原始图像𝑥0被一组Conv-SiLU层,转换为具有与潜在表示𝑧𝑇相同维度的表示 𝑥。
- 然后,𝑥和潜在变量𝑧𝑇经过扩散前向过程后的特征的 和 被输入到SG编码块中。
流程思路:
- 通过编码器的连续下采样,结果最终被添加到中间块的输出中。
- 中间块在完成中间处理后,其结果被添加到SD解码器的输出中。
- 为了应对不同场景和类别的多类别任务,SG解码块的结果也被添加到SD解码器的输出中,并结合SFF块共同处理。
2.1 编码块SGEB:
SGEB 的具体实现可能包括以下几个步骤:(回头研究完代码再来补充)
- 图构建:首先,从输入图像中提取特征(例如,通过卷积神经网络),并将这些特征映射到图结构中的节点。节点可能对应于图像中的像素、超像素、对象区域等。
- 空间关系编码:然后,通过定义边的权重或类型来编码节点之间的空间关系。这些权重或类型可能基于节点之间的相对位置、距离、方向或其他空间属性。
- 图嵌入:使用图嵌入技术(如图卷积网络、图注意力网络等)来学习节点的低维表示,这些表示将包含原始特征以及通过空间关系编码的额外信息。
- 输出:最后,SGEB 的输出可能是节点的嵌入表示,这些表示可以被用于后续的异常检测任务。
2.2 解码块SGDB:
等有空研究一下代码
2.3 空间感知特征融合块SSF(Spatial-aware Feature Fusion Block):
2.3.1 SFF设计背景:
- 在多类别异常检测中,数据集包含各种类型的对象和纹理。
- 对于与纹理相关的情况,异常通常较小,因此需要保留原始纹理。
- 而在对象相关的情况下,缺陷往往覆盖较大区域,要求更强的重建能力。
- 因此,挑战在于如何同时保留原始样本的正常信息并重建大规模异常区域。
2.3.2 SFF的提出:
- 为了应对这些挑战,提出了空间感知特征融合块(SFF),其目标是将高尺度的语义信息 集成到低尺度中。
- 这样可以同时保留原始正常样本的信息并重建大规模异常区域。
2.3.3 SFF的结构:
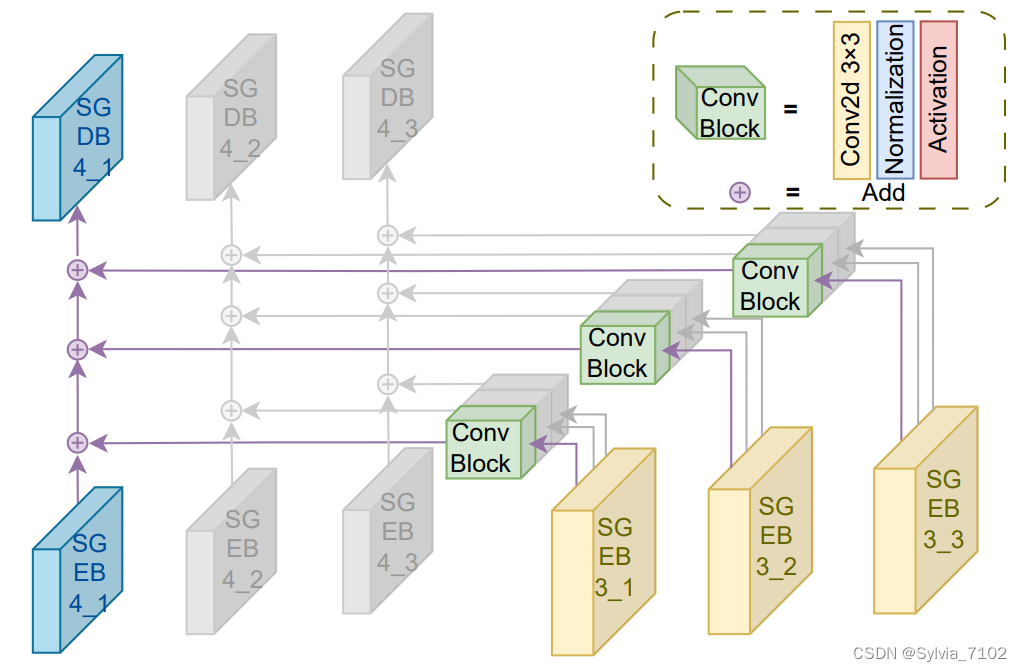
- SFF块将SGEB3中每一层的特征融合到SGEB4中的每一层中,并将融合的特征添加到原始特征中。
- SFF块通过将高尺度的语义信息集成到低尺度中,实现了对原始正常样本信息的保留和大规模异常区域的重建。

- 在处理需要广泛重构的区域时,引入此块以最大化重构的准确性。它可能利用空间位置信息来指导特征融合过程,从而确保在重构过程中考虑到像素之间的空间关系。
3. SD去噪网络
3.1 去噪网络组成
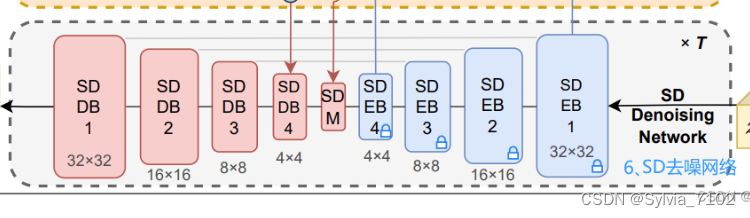
- 输入具有噪声的潜在变量𝑧𝑇、和SG网络输出语义特性信息。
- 在潜在空间中进行扩散和去噪操作。
- 过去噪块(SDEB和SDDB)逐步去除噪声,最终重建潜在表示𝑧^。
- 预训练SD去噪网络:包括四个编码块、一个中间块和四个解码块。
- SG语义引导网络:复制SD网络参数以初始化,并在结构上与其类似。
3.2 工作原理

去噪网络的输出被定义为:

3.3 特点
- 语义一致性:通过引入SG网络,在重建过程中有效保持输入图像的语义信息,解决了LDM在多类别异常检测中的语义信息丢失问题。
- 多类别适应性:通过结合SFF块和SG解码块,应对不同场景和类别的多类别任务,提高了模型的灵活性和鲁棒性。
- 高效重建:通过在潜在空间中进行扩散和去噪操作,增强了模型在处理复杂结构和大规模缺陷时的重建能力。
4. 特征空间预训练特征提取器(Feature-space Pre-trained Feature Extractor):
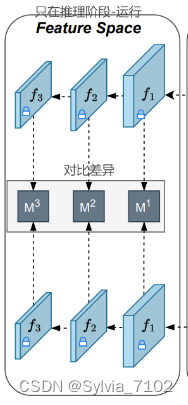
- 预训练特征提取器 :处理输入图像𝑥0和重建图像 𝑥0^。
- 特征提取:从不同尺度提取特征图 𝑓1,𝑓2,𝑓3。
- 异常评分:通过计算重建图像和输入图像在不同尺度特征上的差异,生成异常评分图S。
- 输入图像和重构后的图像被送到这个预训练的特征提取器中,该提取器能在不同尺度上提取特征。基于这些特征,系统生成异常图(anomaly maps),这些图显示了图像中可能存在的异常区域。
5. 异常检测与定位:
- 通过比较输入图像和重构后图像的特征,系统能够识别出异常区域,并给出这些区域的异常得分或置信度。这允许系统不仅检测出异常图像,还能定位到异常发生的具体位置。
DiAD框架主要通过多尺度特征提取和余弦相似度计算,进行异常定位和检测。
5.1 推理阶段:
- 在推理阶段,通过扩散和去噪过程在潜在空间中获得重建图像 𝑥^0。
- 为了进行异常定位和检测,使用相同的ImageNet预训练特征提取器,
- 来提取输入图像𝑥0和重建图像𝑥^0 的特征,并在不同尺度的特征图上计算异常图𝑀𝑛。



5.2 方法优点:
- 多尺度特征融合:通过在不同尺度上提取特征并计算异常图,模型能够更全面地检测和定位异常。
- 余弦相似度度量:使用余弦相似度作为度量标准,通过计算输入图像和重建图像特征向量之间的夹角,精确衡量它们的相似性。
- 权重融合:综合不同特征层的异常图,根据每层特征的重要性赋予不同的权重,最终计算出综合异常得分。
二、模型细节设计
1. 数据处理
- 图像尺寸:所有MVTec-AD和VisA数据集的图像都调整为256 x 256的大小。
- 去噪网络:使用第4层SGDB(Semantic-Guided Decoder Block)与SDDB(Stable Diffusion Decoder Block)连接。
- 特征提取网络:采用ResNet50作为特征提取网络,选择第 𝑛层特征用于计算异常定位,其中 𝑛∈{2,3,4}。
2. 模型训练
-
自编码器微调:在训练去噪网络之前,使用KL方法对自编码器进行微调。
-
训练细节:
-
训练1000个epoch。
-
使用单个NVIDIA Tesla V100 32GB GPU。
-
批量大小为12。
-
优化器:Adam,学习率设置为 1𝑒−5。
3. 平滑和异常得分计算
-
平滑方法:使用高斯滤波器(标准差 𝜎=5)对异常定位得分进行平滑。
-
异常检测:图像的异常得分为经过8轮8 x 8大小全局平均池化操作后的最大值。
4. 推理过程
- 去噪时间步:初始去噪时间步设置为1000。
- 采样策略:使用DDIM采样器,默认10步。


















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









