







 本文详细介绍了影响高质量图像生成的关键参数,如提示词准确性、CFG值的平衡、采样策略、放大处理以及模型配置等,强调了随机种子在保持风格一致性中的作用。
本文详细介绍了影响高质量图像生成的关键参数,如提示词准确性、CFG值的平衡、采样策略、放大处理以及模型配置等,强调了随机种子在保持风格一致性中的作用。
本文是学习整理用作自用,数据效果图部分源自B站up主小白,感谢技术分享,视频做的非常好,大家可以关注一下。

好的图像涉及哪些参数?
核心参数:
准确的提示词 + 合理的CFG值 + 采样器和采样步数 = 好图像

人物
起手式:
正:
best quality, masterpiece, (photorealistic:1.4), 8k,
反:
(worst quality:2),(low quality:2),(normal quality:2),nsfw,ugly,lowres,watermark,badhand,bad anatomy,text,error,missing fingers,extra digit,username,missing arms,long neck,humpbacked,bad feet,
写实人物:
特殊起手式:photorealistic,raw photo
采样器:DPM++SDE KarraS 或DPM++2M SDE KarraS
采样步数:20
CFG值:7
放大器算法:R-ESRGAN 4X+
动漫人物:
采样器:Uler a 或 DPM++SDE KarraS
采样步数:20
CFG值:7
放大器算法:R-ESRGAN 4x+ Anime6B
风景
采样器:UniPC或Restart
采样步数:5~10
CFG值:3
采样器迭代步数 与 对应CFG
CFG:
对比当前图片与监察提示词的相关性,默认为1此时不做检查。过高,每步解算均对照,导致画面信息崩溃。过低,生成图像与图像不相干随机性高。同时,提高CFG值会提高图像饱和度和对比度,而且CFG值太高时,图像会变得模糊细节丢失。我们可以通过增加采样步数、更换采样方法、采用动态CFG插件等来进行补偿。
提示词越准确,越容易通过CFG生成合适图像。一般情况下CFG值设置为7。

高清放大
在初步生成的小尺寸图基础上,继续以图生图的方式再二次解算,提升画面质量和细节度,尤其可以解决手崩脸崩的问题。
二次生成,不像直接生成高分辨率图像耗费显存算力,但由于二次生成所以时间也相对较慢。

放大算法:
不同的解算器。
放大倍率:
默认为512x512,如果设为2,即生成1024x1024。
高清修复采样次数:
由于是再次重绘,所以需要设置采样步数。默认为0,此时与初绘采样步数相同。
重绘幅度:
在图像中加入二次创新的力度。

CLIP
跳过层,跳过一些层,减少文本嵌入维度以降低计算难度,提高出图效率。跳过层越多,提示词与图像相关率越低。一般默认值为1或2。
尺寸分辨率
早期1.5时代都是给SD 512x512的图片用作训练,所以我们出图最好采用512整数倍。如需更高清图像,再高清放大。
1.5和2.1都是早期版本,到了XL训练的图片到了1024x1024,此时图片质量大幅提高,但我们的算力需求也更高了,大模型都来到了6G,需要显存12G起。

生成批次
生成几批,每批数量是一批出多少张。每批次出图效果一般一样。
随机种子seed
我们都知道在计算机中,随机都是伪随机。那么如果获得了我们满意的图片风格,在其他重要参数不改变的情况下,我们就可以通过保存随机种子,以此重现图片。如果值为-1表示永久随机。
绿色按钮回收种子值。
总结结论
1.当使用完全相同的提示和参数,只更改种子编号时会得到完全不同的输出图像
2.保持相同的种子编号,只通过添加单个单词修饰更改提示词,可以更改输出图像,而不会明显改变它们的整体外观和风格

什么是采样器?
SD生成图像的过程,是生成一张随机的噪点图,通过不同的采样方法,逐步去除图像中的噪点,这个过程我们称为采样,而不同的采样方法,我们把它称为采样器。
采样的过程一般十几次或二十几次,每一步都在原本杂乱的基础上,生成进一步的清晰图像,经过若干次的去噪修正,我们最终得到想要的图片。
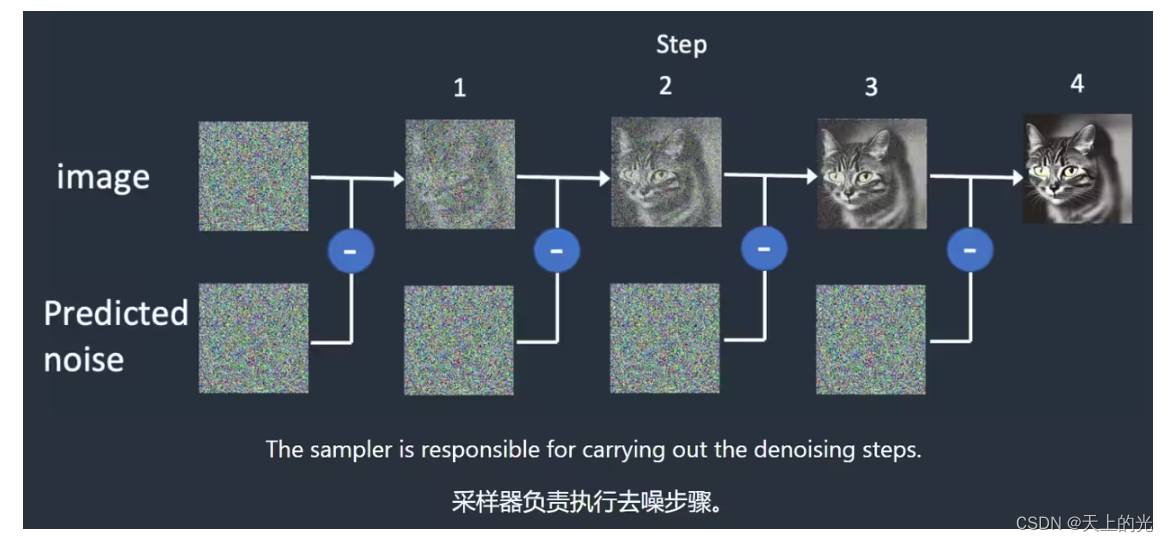
提示词是怎样被分析的?
我们输入的提示文本后首先进行分词(token),接下来为了使提示词变成计算机能够处理的形式,我们进行嵌入(Embedding) 操作,这是我们的文字语言,就转换为了一串连续的向量。这串向量,我们需要对其进行语义上的分析,探寻其彼此的关联性,这个过程采用了Transformer的技术,称为文字压缩嵌套(Text Transformer)。最后,我们将这组数据作为输入,放入采样器进行噪声预测,不同语义的提示词将负责自己那部分工作,最后逐步地生成图像。
而不同的采样器,可以理解成北京到上海的旅程。虽然大家出行方式不同,但总归都能到达目的地。对于采样结果,不同的采样器之间有一个重要参数——采样步数。

什么是采样步数?
采样步数,就是采样过程的次数。总体上讲,采样步数越多,生成的图像就越细腻,而与此同时,我们运算的次数以及耗费的时间就要长一些。这时候,我们的敏感性就发挥了,可见这个步数太高不好,太低也不好,那么就要寻求一个适中的值,大部分采样器的采样步数居于15~30步之间。
有哪些采样器?
按照时间划分,采样器大概可以分为这三个阶段:
早期采样器:
一般年代久远,有一些祖先采样器,还有同SD一同推出的一些采样器。
DPM采样器:
一般是2022年左右发布的,以DPM为基础的改良版采样器。
带a的是祖先采样器变体,一般表示随机变量的引入,即在每一步去噪完成后重新引入随机新噪声,以此使图像多变。
DPM++系列,是对DPM的升级版本。
DPM2比DPM更加准确,但速度慢了一倍。
带SDE的,表示在DPM过程中添加了SDE这种随机算法,每一步扩散都引入随机噪声,采样结果很随机,出图不收敛,富有多种变化。
带3M的采样器,是1.6版本后推出的升级版本,通常在30步之后才会有不错的效果。
带Karras的,随着采样步数的增加,可以减少误差,使图像细腻,一般效果都不错。
带Exponential的,是在原有的过程中,增加了柔和的效果。
更新采样器:
目前最新的采样器。
UniPC 和 Restart:
2023年推出的采样器,以尽可能少的采样步数,获取相对最高的图像质量。在低CFG(提示词相关性)的条件下,5~10步就能得到不错的图像, 20 ~30步便可十分不错。
LCM:清华大学推出的采样器,在极低CFG和采样步数下往往有奇效,需要搭配对于的Lora使用。速度非常快,可以高效率出图。

按照效果划分?

按照用途划分?

采样器参数设置?



















 3588
3588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









