






转载公众号 | 知识图谱科技

摘要:
从传统 RAG 到GraphRAG 的转变通过整合知识图谱增强了大型语言模型,使其能够对复杂查询提供更加细致和准确的响应。GraphRAG 的有效性也取决于底层知识图谱的质量和广度以及RAG工程层面的处理。
主要观点:
- GraphRAG 通过利用知识图谱为丰富的上下文改进 LLM 的响应。
- 它解决了传统 RAG 的局限,提升了对复杂查询的理解。
- 复杂的检索和索引方法提高了 RAG 系统的准确性和速度。
- 未来的整合可能会带来动态更新、提高计算效率和更广泛的知识传递。
- GraphRAG 的影响涵盖自然语言处理、人工智能伦理和人工智能创新等领域。
- 知识图谱在为 LLM 提供结构化、与上下文相关的数据方面起着至关重要的作用。
- GraphRAG 的有效性取决于底层知识图谱的质量和广度以及RAG工程层面的处理。
Introduction简介
我们知道,大型语言模型(LLMs)在固定的数据集上运行,其知识停止在最后一次训练更新时。
ChatGPT的常规用户可能会认识到这个众所周知的限制:“训练数据截至2021年9月”。这种限制可能导致不准确或过时的回复,因为这些模型会“产生幻觉”信息。
在不重新训练或微调的情况下更新它们以获得新信息或增强上下文理解可能是具有挑战性的,涉及资源和人力。
Retrieval-Augmented Generation (RAG)检索增强
检索增强(或简称为 RAG)被引入为一种技术,以通过合并来自外部可靠知识库的信息来改善大型语言模型(LLMs)。
RAG背后的原则很简单;当要求LLM回答问题时,它并不仅依赖于已知的内容。相反,它首先查找来自特定知识源的相关信息。
这种方法确保生成的输出引用了大量上下文丰富数据,通过当前和相关信息的增强。
RAG 主要通过两阶段过程来发挥作用:检索和内容生成。
Retrieval Phase检索阶段
在检索阶段,算法会定位并收集与用户提示或查询相关的信息片段。
举个例子,如果您正在寻找福建炒面的食谱,您的提示可能是“福建炒面的配料是什么?”
系统识别具有与查询语义相关内容的文档,并使用一种相似度度量(通常是余弦相似度(嵌入的余弦相似度究竟是关于相似度的吗?https://arxiv.org/html/2403.05440v1))计算相关性,计算它们向量之间的相似度。
在汇总外部知识之后,系统将其附加到用户的提示内容中,并将其作为丰富的输入发送到语言模型。
Content Generation Phase内容生成阶段
在随后的生成阶段,LLM将这个增强的提示与自己的训练数据表示结合起来,以生成针对用户查询定制的回复。这种回复提供了个性化和可验证信息的混合,适用于诸如聊天机器人之类的应用程序。
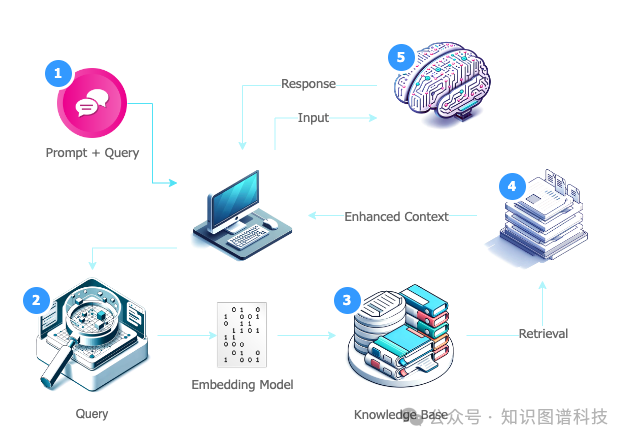
Why RAG Matters-为什么RAG如此重要
在当今的技术风景中,LLM驱动着许多自然语言应用,能够理解或生成类似人类的文本。尽管非常强大,但这些模型有时可能表现不佳。
有时,它们在生成不正确的响应上可能过于自信,以至于人们可能很容易被它们极具说服力的论点所说服。

RAG试图通过指导LLM从可信来源获取信息来减轻这些问题,从而保持模型输出的相关性和准确性。
RAG的限制
生活中的一切事物一样,传统的 RAG 方法存在复杂性和挑战。
虽然在增强 LLM 能力方面具有开创性,但 RAG 也存在一定的限制,可能会影响它们的有效性和适用性。
其中一个主要挑战涉及检索信息的准确性和数据源的多源异构性。
对于 RAG 要发挥作用,它经常依赖于多个外部来源,这些来源的格式、标准和可靠性水平可能各不相同。(如 PDF、Flat files、Markdown、CSV、Web 内容等)
RAG 的实施也面临着模糊查询或需要深刻理解背景的问题。
这些问题,作为技术设计固有的问题,主要源自检索过程,有时会忽略对精确响应至关重要的细微差别。

RAG的提升
RAG 系统的检索准确性和效率的提升是自然语言处理和机器学习领域的一个持续研究方向。有几种策略可以采取来实现这些改进,但我想强调两个值得关注的改进,这两个改进可以利用当今的技术来实现。
实施更复杂的检索算法,从而更好地理解查询的语义,可以提高获取文档的相关性。
高效地对知识库进行索引,加快检索过程,同时不牺牲结果的质量。
这就引出了我们的下一个话题...
Graph RAG: RAG x Knowledge Graphs(知识图谱)
GraphRAG建立在RAG的概念基础之上,同时利用了知识图谱(KGs)。
这种创新方法,是NebulaGraph、Neo4J、微软等提出的概念,通过整合图数据库改变了LLMs解释和响应查询的方式。
GraphRAG通过将KGs中的结构化数据整合到LLM的处理中运行,为模型的响应提供了更加细致和充分的依据。KGs是真实世界实体及其之间关系的结构化表示,由节点和边组成,节点代表诸如人、地点、物体或概念等实体,边代表这些实体之间的关系或连接。
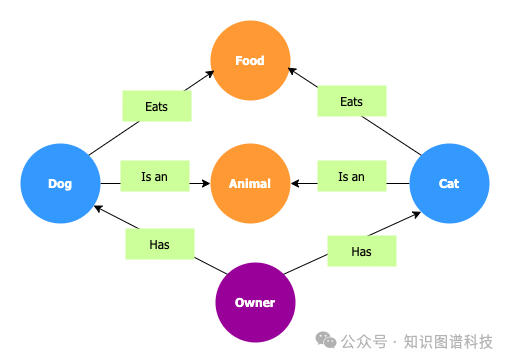
这种结构极大地提高了LLMs生成明智回应的能力,使模型能够访问精确和上下文相关的数据。
GraphRAG的创新在于将图数据库与LLMs集成,丰富模型的上下文,然后生成响应。
一些热门的图数据库产品是Ontotext、NebulaGraph和Neo4J。
什么使GraphRAG具有重要意义
随着LLMs在精密度和能力方面不断增长,Graph RAG有潜力对人工智能领域产生重大影响。
以下是我对这种整合发展的设想:
1. 未来的LLMs预计将展示对复杂查询和推理能力的改进理解。
Graph RAG可以利用这些进展提供更精确和有上下文的答案。
从知识图谱中获取的结构化知识,结合更复杂的LLMs,可能会导致人工智能在理解抽象概念、推理并产生细致的回应方面取得突破。
2. 随着LLMs看似不可遏制的进展,它们与知识图谱的整合可能会变得更加动态和无缝。
这可能涉及基于全球事件或发现的知识图谱的实时更新。
LLMs可以通过整合从用户互动或其他数据源收集到的新信息,在自动增强和更新知识图谱方面发挥作用。
使用强化学习从人类反馈(RLHF)和强化学习从AI反馈(RLAIF)等技术可以进一步帮助将模型与人类偏好保持一致,并遵循HHH(不是摔跤手,而是有帮助、诚实、无害)原则。
3. 随着NVIDIA努力实现人工智能计算的民主化,未来LLMs和Graph RAG实现的进展将侧重于提高计算效率和可扩展性。
这一转变将使Graph RAG能够在更广泛的应用程序中使用,包括那些需要实时响应或在资源有限的环境中运行的应用程序。
4. 未来预计LLMs在多个领域拥有更广泛和更深入的知识。Graph RAG可以促进跨不同领域的知识传递,从而能够生成利用不同领域信息的见解或解决方案。
例如,应用认知科学的发现可能会导致开发更自然的人机交互模型,或将网络安全与心理学相结合可能提高安全措施的有效性。
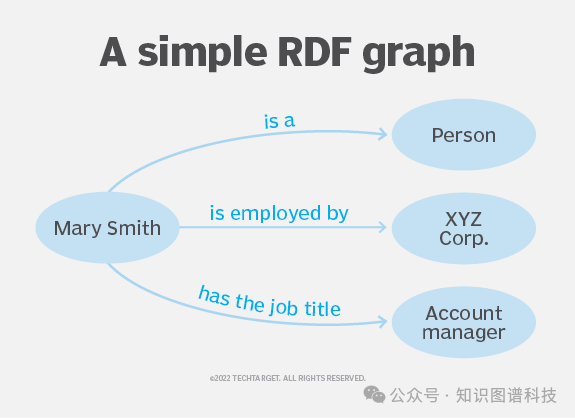
5. 随着Graph RAG技术的发展,采用像资源描述框架(RDF)这样的标准用于知识图谱可以提高各种系统之间的互操作性。
这可能意味着不同的实施方案相互作用和协作,从而推动更广泛的采用和创新的推动。
Graph RAG Demo
对于这次演示,我们将使用 Govtech 的开发者门户站点上的产品信息作为我们的知识库。
Setup设置
使用 Neo4j Desktop 启动 Neo4j 本地实例
使用 LangChain 在本地连接到 Neo4j 数据库。好消息是 LangChain 具有一个可供使用的模板,方便快速设置。
2. 提取
使用提示工程和LLM来提取信息、节点及其连接。以下是一个提示的示例:
# Instructions for Creating Knowledge Graphs
## Overview
You are engineered for organising data into knowledge graphs.
- **Nodes**: Represent entities and ideas.
- The objective is to ensure the knowledge graph is straightforward and intelligible for broad use.
## Node Labeling
- **Uniformity**: Stick to simple labels for nodes. For instance, label any entity that is an organisation as "company", rather than using terms like "Facebook" or "Amazon".
- **Identifiers for Nodes**: Opt for textual or comprehensible identifiers over numerical ones.
- **Permissible Node Labels**: If there are specific allowed node labels, list them here.
- **Permissible Relationship Types**: If there are specific allowed relationship types, list them here.
## Managing Numerical Data and Dates
- Integrate numerical information directly as attributes of nodes.
- **Integrated Dates/Numbers**: Refrain from creating distinct nodes for dates or numbers, attaching them instead as attributes.
- **Format for Properties**: Use a key-value pairing format.
- **Avoiding Quotation Marks**: Do not use escaped quotes within property values.
- **Key Naming**: Adopt camelCase for naming keys, such as `dateTime`.
## Uniformity
- **Entity Uniformity**: Ensure consistent identification for entities across various mentions or references.
## Adherence to Guidelines
Strict adherence to these instructions is mandatory. Non-adherence will result in termination.3. 图谱构建
使用 CSVLoader 和文档分割来处理我们的文档
将提取的信息映射到图节点和关系
通过我们的提取管道处理文档并将信息存储在 Neo4j 中
 整个过程将近一个小时,导致最终提取的节点标签列表。
整个过程将近一个小时,导致最终提取的节点标签列表。
不幸的是,并非所有节点标签都对我们的上下文有用或符合我们的需求。
{
"identity": 1040,
"labels": [
"Feedbackstatus"
],
"properties": {
"id": "Feedback-Success",
"message": "Sent. Thank you for the feedback!"
},
"elementId": "4:81cd2613-0f18-49c1-8134-761643e88b7a:1040"
},
{
"identity": 1582,
"labels": [
"Feedbackstatus"
],
"properties": {
"id": "Feedbacksuccess",
"status": "Sent. Thank you for the feedback!"
},
"elementId": "4:81cd2613-0f18-49c1-8134-761643e88b7a:1582"
},
{
"identity": 1405,
"labels": [
"Header"
],
"properties": {
"id": "Modalcardhead",
"class": "sgds-modal-card-head"
},
"elementId": "4:81cd2613-0f18-49c1-8134-761643e88b7a:1405"
},
{
"identity": 1112,
"labels": [
"Feedbackindicator"
],
"properties": {
"id": "Feedbacksuccess",
"title": "check",
"message": "Sent. Thank you for the feedback!"
},
"elementId": "4:81cd2613-0f18-49c1-8134-761643e88b7a:1112"
...4. 评估与改进
我们将指定LLM应提取哪些节点标签来完善我们的方法
permissible_nodes_to_extract = [
"Aisubfield",
"Application",
"Cloudservice",
"Concept",
"Digitalsolution",
"Division",
"Entity",
"Feature",
"Fundinginitiative",
"Initiative",
"Link",
"Location",
"Organization",
"Person",
"Platform",
"Policy",
"Program"
"Resource",
"Role",
"Schema",
"Service",
"Standard",
"Technology",
"Technologyplatform",
"Technologystack",
"Webframework",
"Webresource",
"Website"
]浏览我们新构建的知识图谱,使用 Neo4j 浏览器。
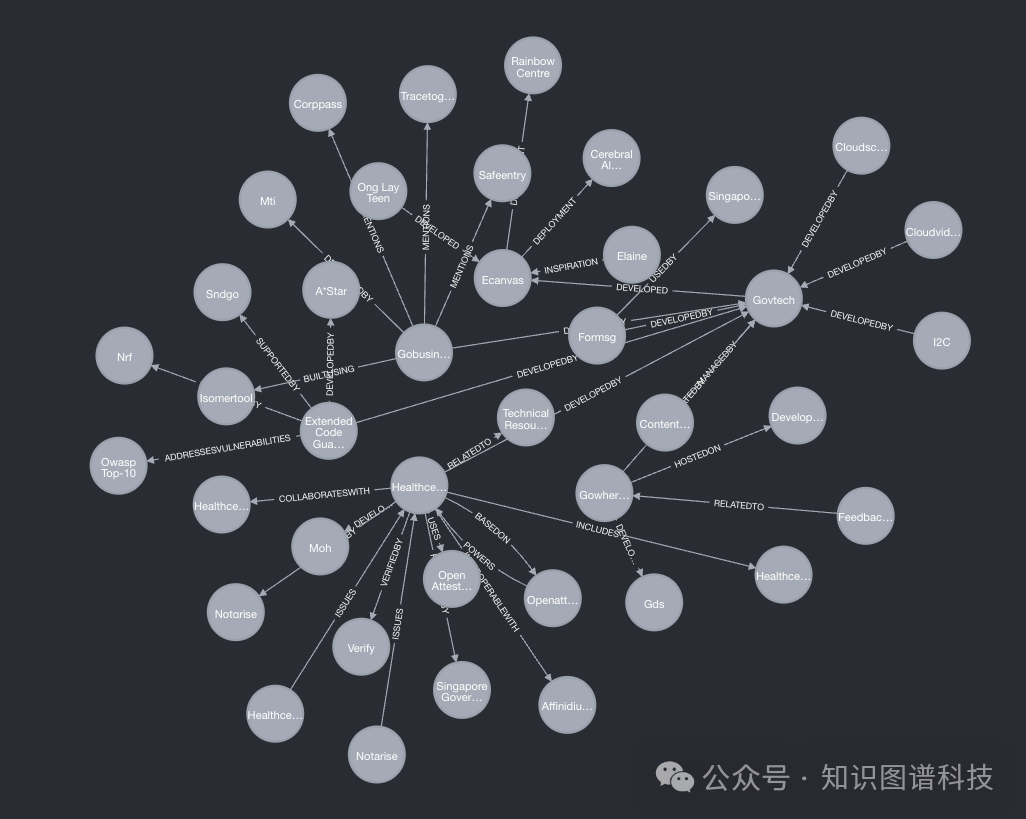
不断完善我们的提取和图构建方法
经过所有的努力,魔法终于开始了!考虑以下查询:
问:“告诉我更多关于AiSay的信息,包括开发这个产品的人员,以及它的好处和应用。还请告诉我AiSay如何独特。”
基础RAG:“AiSay是新加坡政府开发的AI驱动文档阅读器。它可以自动检测、扫描和理解各种类型的文档,包括手写笔记、印刷文章、多语言文本以及结构化/非结构化文档。与传统的OCR系统不同,AiSay可以为图像和PDF文件等文档提供结构化的响应。它利用OCR、文档问答技术和大型语言模型来推导上下文并回答查询。AiSay可以通过同步和异步调用选项进行扩展,从而可以处理大文件大小。它在云端无服务器上托管,使其在容量上具有可扩展性,能够处理大文件大小。AiSay正在积极开发中,支持RESTRICTED/SENSITIVE NORMAL级别的安全性和数据分类。未来将支持更多文档类型。AiSay的独特功能包括其提供多种文档类型的结构化响应能力,具有可扩展性,以及对安全性和数据分类的支持。”
GraphRAG:“AiSay是新加坡政府开发的AI驱动文档阅读器。它是一个文档解析器,可以提供结构化的响应,从各种文档中提取和集成信息到现有系统中。AiSay可以自动检测、扫描和理解各种文档,包括手写笔记、印刷文章、多语言文本以及结构化/非结构化文档。与传统的光学字符识别(OCR)系统不同,AiSay可以为图像(JPEG、PNG、TFIF)和PDF文件等文档提供结构化的响应。
AiSay的一些关键好处包括:
1. 减少手动错误,提高数据准确性,因为从文档上传中自动填充关键数据以进行表单提交。
2. 改善数字服务体验,因为一旦文档上传,AiSay就可以自动填充关键数据。
AiSay在为各种文档类型提供结构化响应的能力方面独一无二,支持各种格式和语言。它还为每个任务提供信心分数,以确定是否需要额外支持,从而在具有高置信度水平的任务中最大程度减少人工干预。此外,由于其在云端无服务器上托管,AiSay具有可扩展性,能够处理大文件大小和异步提取过程。”
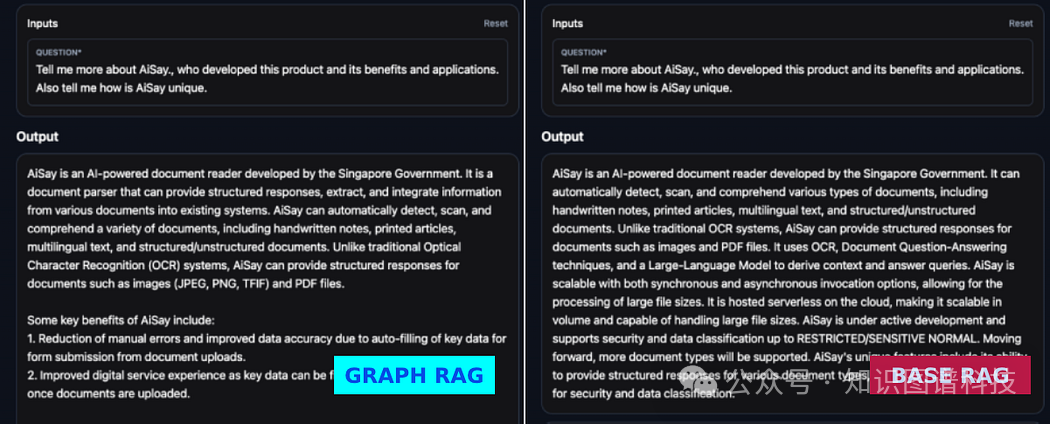
相对于传统的RAG方法,Graph RAG的优势在这种情况下是显而易见的。
这种回应不仅显示了准确性,而且充满了上下文和关系,提供了标准RAG方法所不具备的深度水平。
Graph RAG的秘密在于它分析用户的查询能力,定位图数据库中的相关数据,并将这种背景见解纳入指导LLM回应的过程中。
这种方法利用了一个相互连接的信息网络(传统方法可能会忽略),从而导致对查询更加微妙的理解。
让我们再举几个例子
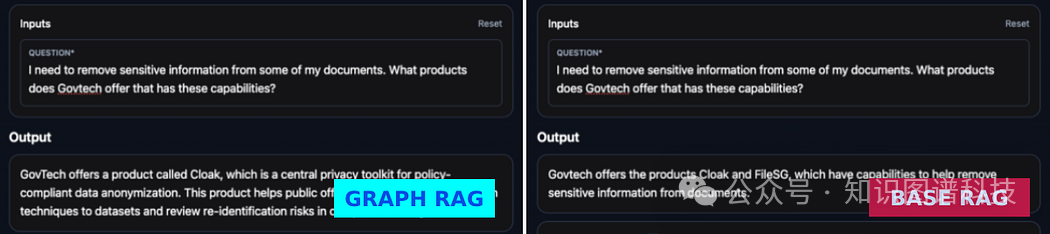
Q:“我需要从我的一些文档中删除敏感信息。Govtech提供哪些具有这些功能的产品?”
基础RAG:“Govtech提供Cloak和FileSG两款产品,这些产品具有帮助删除文档中敏感信息的功能。”
Graph RAG:“GovTech提供一款名为Cloak的产品,它是一个符合政策的数据去标识的中心隐私工具包。这个产品帮助公务员应用数据去标识技术到数据集,并在符合指南的情况下审查重新识别风险。”
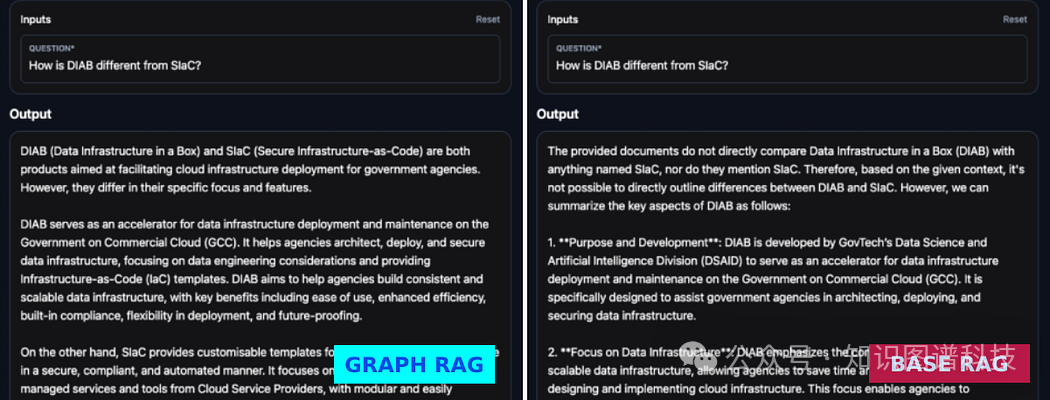
Q:“DIAB与SIaC有何不同?”
基础RAG:提供的文件没有直接将DIAB(Data Infrastructure in a Box)与任何名为SIaC的东西进行对比,也没有提到SIaC。因此,根据给定的上下文,不可能直接概述DIAB与SIaC之间的区别。不过,我们可以总结DIAB的关键方面如下:
1. **目的和开发**:DIAB由GovTech的数据科学与人工智能部门(DSAID)开发,旨在作为政府在商业云(GCC)上部署和维护数据基础设施的加速器。它专门为协助政府机构架构、部署和保护数据基础设施而设计。
2. **数据基础设施重点**:DIAB强调构建一致且可扩展的数据基础设施,使机构在设计和实施云基础设施时节省时间并减少开销。这种重点使机构能够更多地专注于构建应用程序层。
3. **基础设施即代码(IaC)的使用**:DIAB利用IaC模板和参考架构来辅助数据工程考虑,简化设置和管理数据基础设施的进程。
没有关于SIaC的信息,因此不可能进行比较。DIAB的特点突出了其作为政府机构在云中高效部署和管理数据基础设施的工具角色,利用IaC提高效率和可扩展性。
GraphRAG:“DIAB(数据基础设施)和SIaC(安全基础设施即代码)都是旨在为政府机构简化云基础设施部署的产品。但是,它们在特定重点和功能上存在差异。
DIAB作为在政府在商业云(GCC)上部署和维护数据基础设施的加速器。它帮助机构设计、部署和保护数据基础设施,关注数据工程考虑,并提供基础设施即代码(IaC)模板。DIAB旨在帮助机构构建一致且可扩展的数据基础设施,主要优点包括易用性、增强效率、内置合规性、部署灵活性和未来性保障.
另一方面,SIaC提供了用于以安全、符合规范并以自动方式部署云基础设施的可定制模板。它关注云服务提供商管理服务和工具的安全配置,提供模块化且易于适应的模板。SIaC的主要功能包括符合新加坡政府标准、针对不同用例的可模块化设计、可与SGTS组件集成以及云原生设计。
总之,虽然DIAB和SIaC均旨在简化政府机构的云基础设施部署,但DIAB具体针对数据基础设施部署,并侧重于数据工程方面的考虑和IaC模板,而SIaC专注于安全和符合规范的云基础设施部署,提供可定制的模板和模块化设计。”
结论
从传统的检索增强生成(RAG)转变为GraphRAG代表了我们与大型语言模型(LLMs)互动方式的重要一步
这种过渡解决了一个根本性挑战:如何提高LLMs提供上下文准确答案给复杂查询的能力
比较这两种方法时,GraphRAG在处理上下文复杂查询方面的优势变得明显,传统的RAG技术经常未能解决上下文复杂问题。
相比之下,GraphRAG利用了更复杂的知识网络,提供了捕捉查询微妙之处更深刻理解的响应。
然而,GraphRAG的效果并非能解决一切问题的银弹。
它仍然极大地依赖于底层知识图谱的质量、深度和广度,在知识图谱受限或偏向特定领域的情况下,GraphRAG的表现可能不会超过传统的RAG方法。
也就是说,这种过渡有望带来更好地反映人类思维和发现的人工智能系统
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









