







笔记整理:李冰慧,天津大学硕士,研究方向为大语言模型
论文链接:https://aclanthology.org/2024.acl-long.579/
发表会议:ACL2024
1. 动机
使用大型语言模型(LLMs)的多模态推理经常会出现幻觉,并且在LLMs中存在缺乏或过时的知识。一些方法试图通过使用文本知识图来缓解这些问题,但它们的单一知识模态限制了全面的跨模态理解。
本文提出了基于多模态知识图的多模态推理(MR-MKG)方法,该方法利用多模态知识图(MMKGs)跨模式学习丰富的语义知识,显著提高了LLMs的多模态推理能力。特别地,利用关系图注意网络对MMKGs进行编码,并设计了一个跨模态对齐模块来优化图像-文本对齐。构建了一个MMKGgrait数据集,通过预训练使llm具备多模态推理的初步专业知识。
2. 贡献
(1)本文是第一个通过利用MMKGs衍生的知识来扩展LLMs的多模态推理能力的文章。
(2)提出了MR-MKG方法,专门设计用于从MMKGs中提取有价值的知识,并将多模态信息无缝集成到LLMs中。此外,本文还开发了一个基于MMKG的数据集,用于初始增强多模态推理。
(3)本文在两个多模态推理任务上广泛地评估了MR-MKG。MR-MKG取得了最先进的性能,超过了最近的基线方法。
3. 方法
3.1 方法概述
本文的方法的主要目标是有效地利用视觉编码器的能力和来自MMKGs的多模态知识来增强LLMs的多模态推理能力。下图描述了一个可视化的工作流。
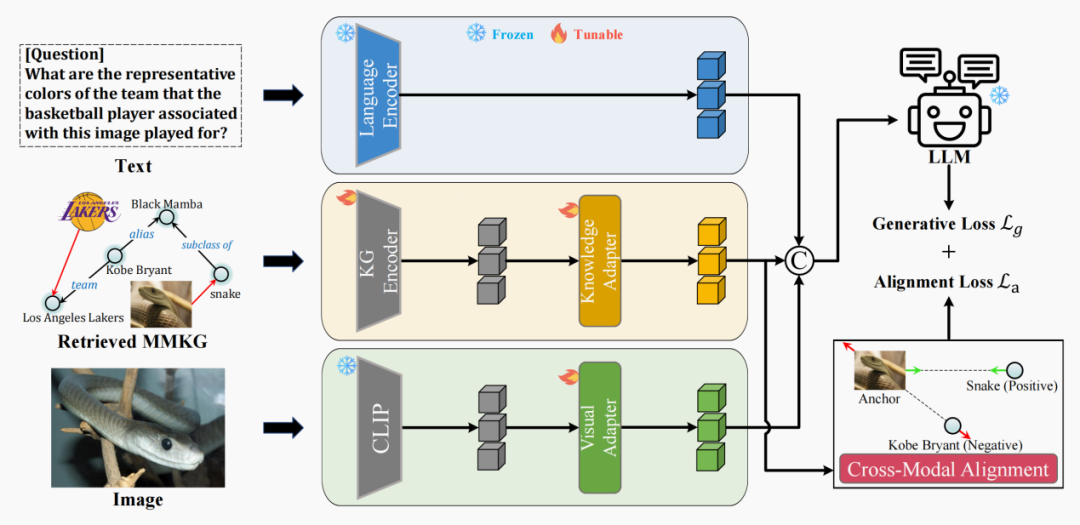
文本、多模态知识图和图像分别使用语言编码器、KG编码器和视觉编码器进行独立嵌入。视觉和知识适配器的设计目的是为了将视觉和KG编码器的嵌入空间与LLM的文本嵌入空间对齐。跨模态对齐模块专门设计用于利用MMKGs中的匹配任务来改进图像-文本对齐。
3.2 MR-MKG架构
MR-MKG由五个组件组成:语言编码器、视觉编码器、KG编码器、知识适配器和跨模态对齐模块。
·语言编码器。本文采用了LLaMA和T5等现成的LLMs中的嵌入层作为语言编码器,它在训练和推理阶段都保持固定。形式上,文本由语言编码器处理,形成文本嵌入。
·视觉编码器。对于输入图像,本文使用了一个预先训练过的视觉编码器,,它将图像转换到视觉特征中。为了保证视觉空间和语言空间的兼容性,使用线性层实现的视觉适配器将视觉特征转换为视觉语言嵌入,与LLMs的单词嵌入向量共享相同的维数。随后,利用单头注意网络,通过以下功能获得与文本嵌入相关联的最终视觉特征:

·KG编码器。给定文本或图像,MR-MKG首先通过从MMKGs中检索一个子图G来识别相关知识,该子图包含前n个最相关的三元组。本文使用关系图注意网络(RGAT),通过考虑G的复杂结构来嵌入知识节点。具体来说,首先使用CLIP来初始化节点和关系嵌入。接下来,使用RGAT网络对G进行编码,生成知识节点嵌入。流程如下:
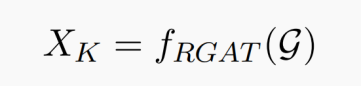
·知识适配器。为了使LLMs能够理解多模态知识节点嵌入,本文引入了一种知识适配器,它可以将知识节点嵌入转换为LLM可以理解的文本嵌入。这种知识适配器旨在弥合多模态知识和文本之间的内在差距,促进更无缝的对齐。
·交叉模态对齐。该模块包括从G中随机选择一组图像实体,并促使模型将它们与相应的文本实体精确匹配。本文使用三重态损失进行对齐。当一个图像实体的嵌入作为一个锚点时,它对应的文本实体的嵌入作为一个正样本。同时,其他文本实体嵌入作为负样本。对齐的目标是最小化正样本与锚定样本之间的距离,同时最大化负样本与锚定样本之间的距离。对准损失的定义如下:

4. 实验
4.1 评估数据集
·ScienceQA:该数据集是一个大规模的多模态科学问题回答数据集,每个多项选择题都伴随着一个文本或视觉上下文。这个数据集不是纯粹的多模态数据,只有48.7%的数据包含图像。
·MARS:是一个新的数据集,设计用于评估多模态知识图MarKG上的多模态类比推理。
4.2 多模态知识图
·MMKG:该数据集分别从 FreeBase、DBpedia和YAGO中提取。每个实体都与来自谷歌的大约36张相应的图像相关联。
·MarKG:是从EKAR和BATs中的种子实体和关系开发的多模态知识图谱数据集。它旨在支持MARS进行多模态类比推理,与MARS共享相同的实体和关系。
4.3 实验结果
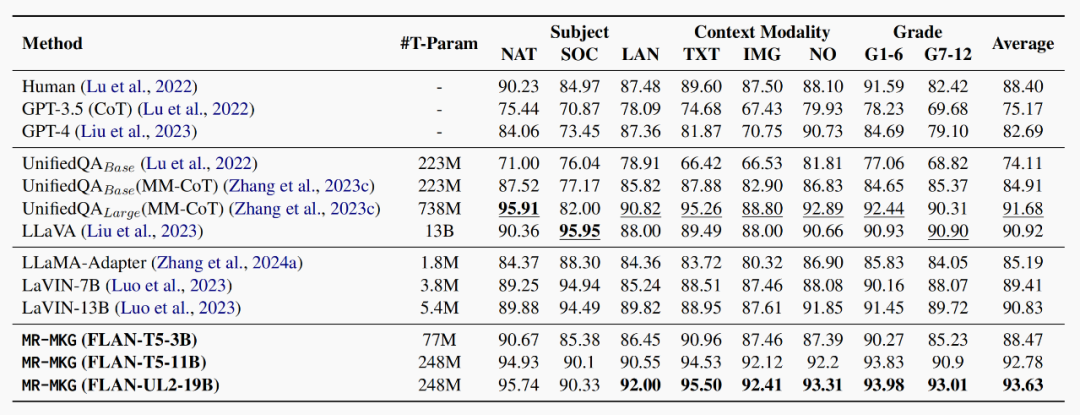
MR-MKG方法在平均精度方面优于所有基线方法。表的第二部分显示了zero-shot和few-shot方法,即使应用于GPT这样流行的LLM,仍然不能达到人类水平的性能。尽管LLaVA在SOC类别中表现最好,但MR-MKG在所有其他类别中都超过了LLaVA,平均准确率提高了+1.86%。
5. 总结
本文解决了通过使用多模态知识图来增强LLMs的多模态推理能力的挑战。我们提出的方法被称为MR-MKG,旨在通过利用MMKGs中包含的丰富知识(图像、文本和知识三联体),使LLMs具有先进的多模态推理技能。对多模态问题回答和多模态类比推理任务的综合实验证明了MR-MKG方法的有效性,在这些任务中实现了新的最先进的结果。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









