






一、背景
有时我们需要生成连笔字或其他期望的字体,所以这里记录一下常用网站。
二、生成连笔字或其他字体的网站
1、FontSpace
网站: https://www.fontspace.com
特点:提供大量用户上传的免费字体,部分为手写体/连笔字风格。
支持中文搜索,适合找一些个性手写字
最上方输入希望的字体,例如Cursive;
下方Type your own text...输入想要生成的字体内容即可,例如china,这里也可以是中文字体。

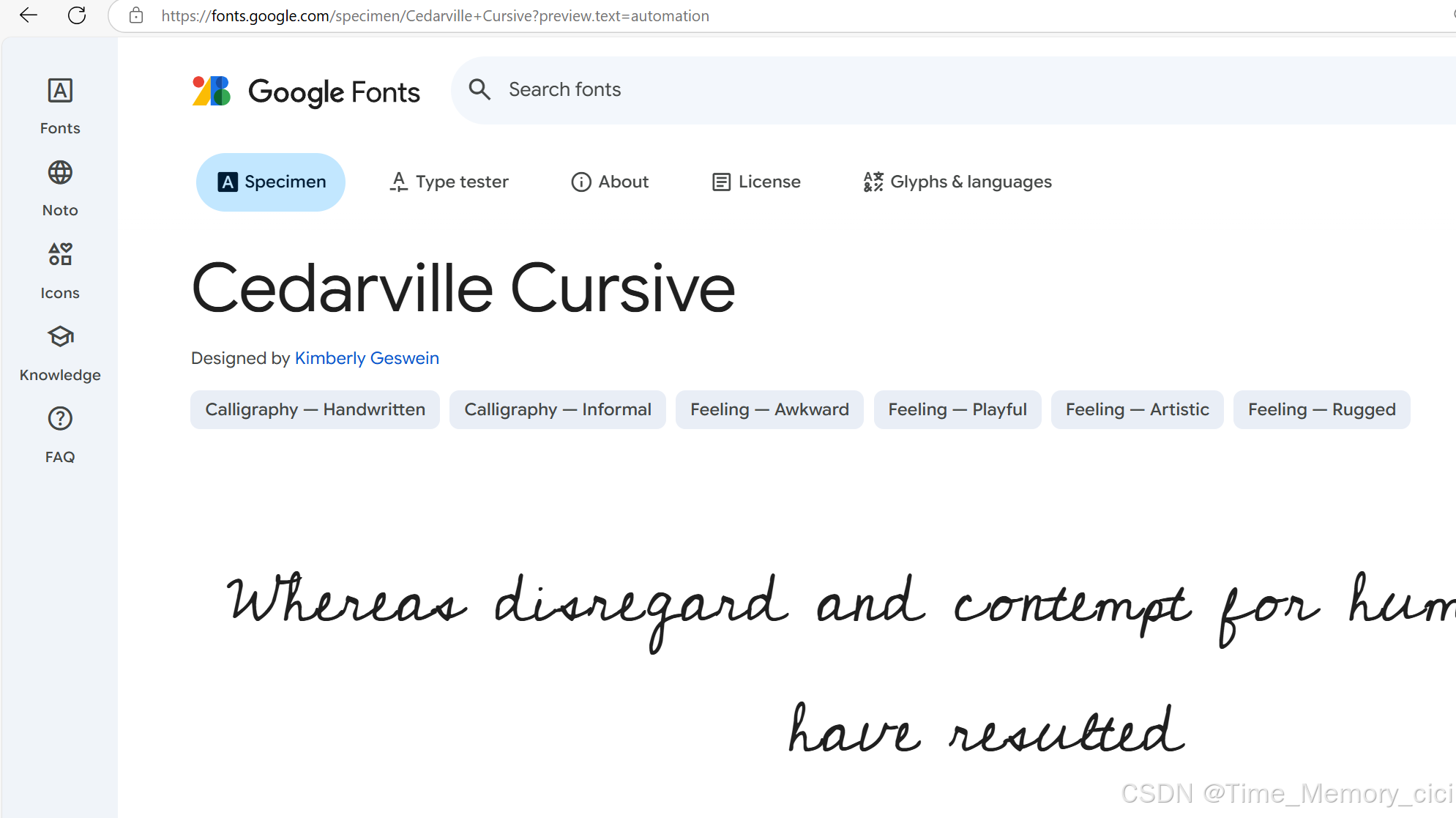
2、Google Fonts
网站: https://fonts.google.com
特点:免费、可商用、支持在线预览。搜索关键词如 “Handwriting” 或 “Cursive” 可找到许多连笔字体。
推荐字体:Dancing Script, Pacifico, Great Vibes
3、Calligraphr(手写生成器)
网站: https://www.calligraphr.com
特点:可上传自己手写模板,自动生成个性化连笔字体。
适合:打造专属个性签名字体
4、Dafont
网站: https://www.dafont.com
特点:英文手写体资源丰富,有“Script”、“Handwritten”分类。
提醒:请注意字体授权,有些仅限个人使用。


















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









