









 文章提出了一种图像自适应的YOLO(IA-YOLO)框架,针对恶劣天气如大雾中的目标检测。通过可微分图像处理(DIP)模块和小型卷积神经网络(CNN-PP),IA-YOLO能自适应地增强图像以提高检测性能。训练过程中,数据集通过渐进式加噪处理,以模拟不同级别的恶劣天气条件。实验表明IA-YOLO在雾和弱光环境下表现出色。
文章提出了一种图像自适应的YOLO(IA-YOLO)框架,针对恶劣天气如大雾中的目标检测。通过可微分图像处理(DIP)模块和小型卷积神经网络(CNN-PP),IA-YOLO能自适应地增强图像以提高检测性能。训练过程中,数据集通过渐进式加噪处理,以模拟不同级别的恶劣天气条件。实验表明IA-YOLO在雾和弱光环境下表现出色。
恶劣天气诸如:光线昏暗、大雾、沙尘、降雨雪等天气状况下,目标检测模型的开发是一个通用挑战,在我之前的实践经验中对于大雾天气下的目标检测模型开发有过实际的开发经历,这里主要是学习研究应用一篇论文中的方法,提出来图像自适应的YOLO检测模型,首先看下效果图:
这是去年发表的一篇来自于浙江大学研究团队的成果,文章在这里,如下:


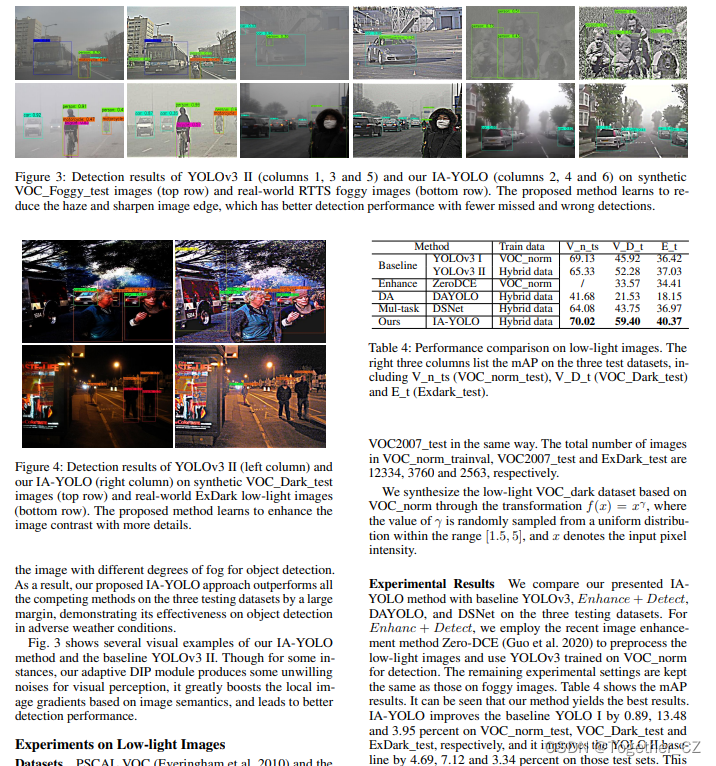

尽管基于深度学习的目标检测方法在传统数据集上取得了有希望的结果,但从恶劣天气条件下拍摄的低质量图像中定位目标仍然具有挑战性。现有的方法要么难以平衡图像增强和物体检测的任务,要么往往忽视有利于检测的潜在信息。为了缓解这个问题,我们提出了一种新的图像自适应YOLO(IA-YOLO)框架,其中每个图像都可以自适应地增强,以获得更好的检测性能。具体而言,提出了一种可微分图像处理(DIP)模块,以考虑YOLO探测器的不利天气条件,其参数由小型卷积神经网络(CNN-PP)预测。我们以端到端的方式联合学习CNN-P和YOLOv3,这确保了CNN-P可以学习适当的DIP,以弱监督的方式增强图像以进行检测。我们提出的IA-YOLO方法可以在正常和不利的天气条件下自适应地处理图像。实验结果非常令人鼓舞,证明了我们提出的IA-YOLO方法在雾和弱光情况下的有效性。
文章的核心思想在于提出了DIP模块,如下:
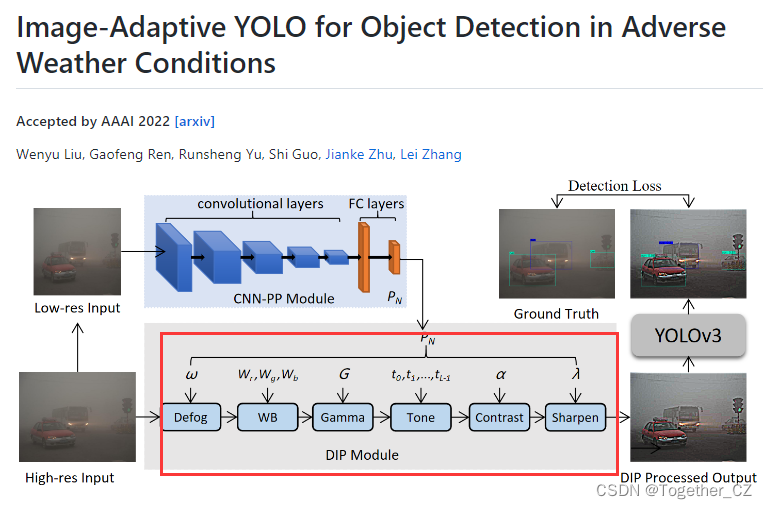
感兴趣的话可以自行移步阅读学习即可,这里就不再对文章进行赘述了。
这里同时也提供了训练方法教程,如下:
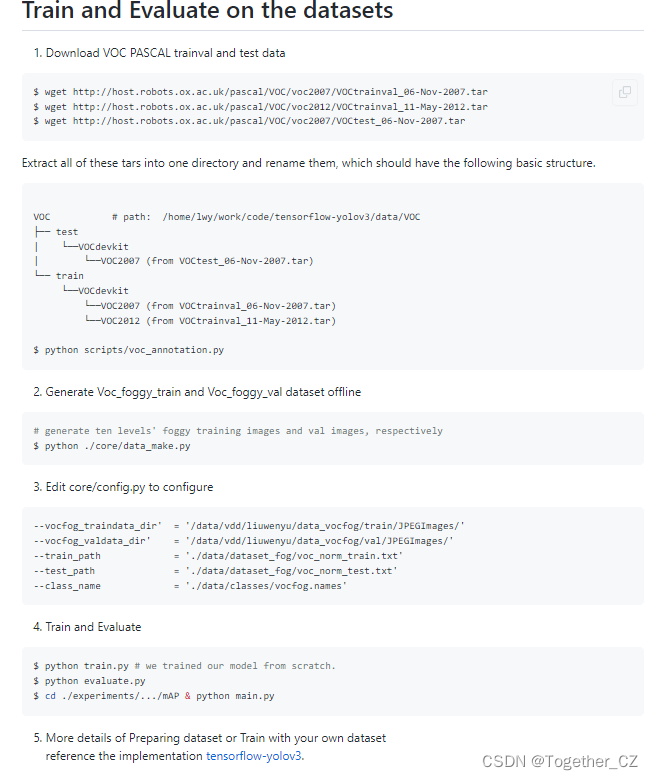
这里实际操作的时候第二步【Generate Voc_foggy_train and Voc_foggy_val dataset offline】是我觉得比较有趣的点,如下:

可以看到:代码有一个加噪的过程,而且这是一个渐进式的过程,不断地加噪,每个样本共分为10级的加噪处理,最终这批数据会工作用于模型的训练拟合。
当然了这里也是可以人为进行修改的,我就把加噪等级修改为3,因为VOC数据集太过于庞大, 磁盘已经没有多少空间可用了,这个根据自己实际情况操作即可。
安装教程操作即可,训练启动日志输出如下所示:
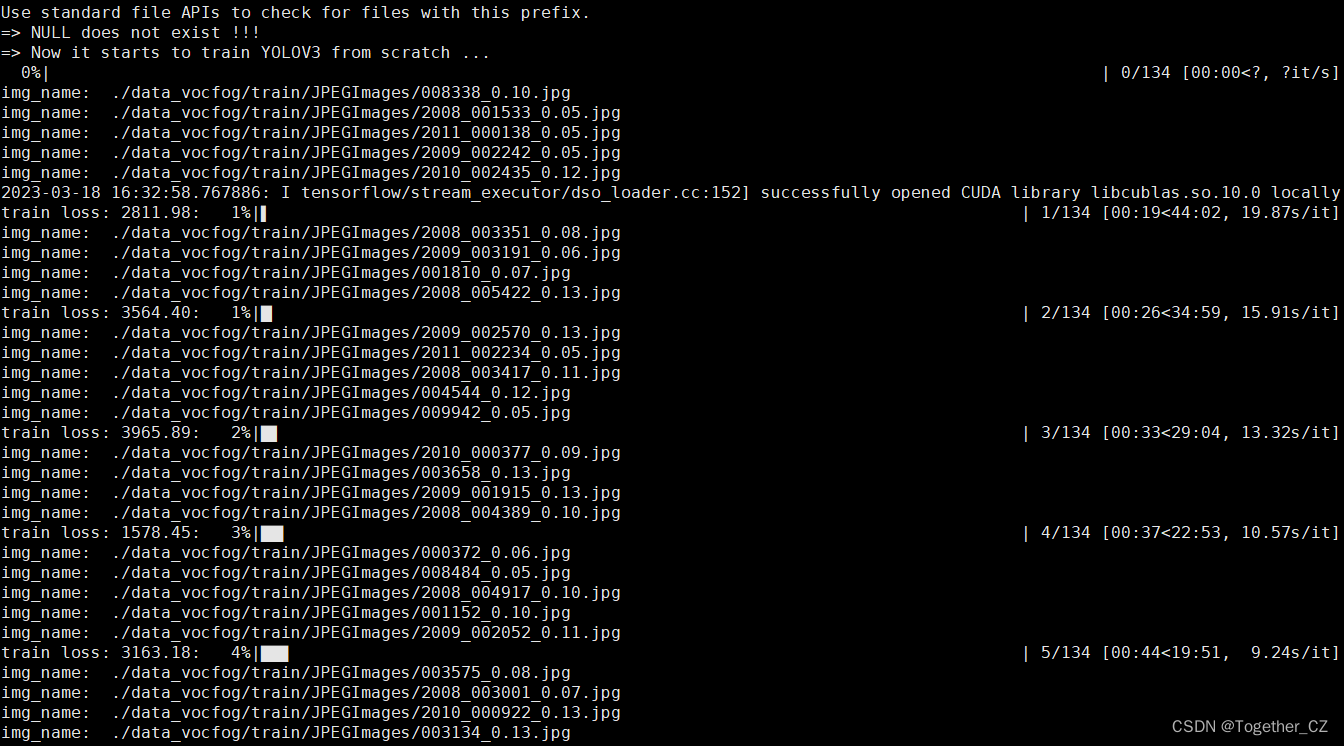
训练过程实际会自动存储如下:
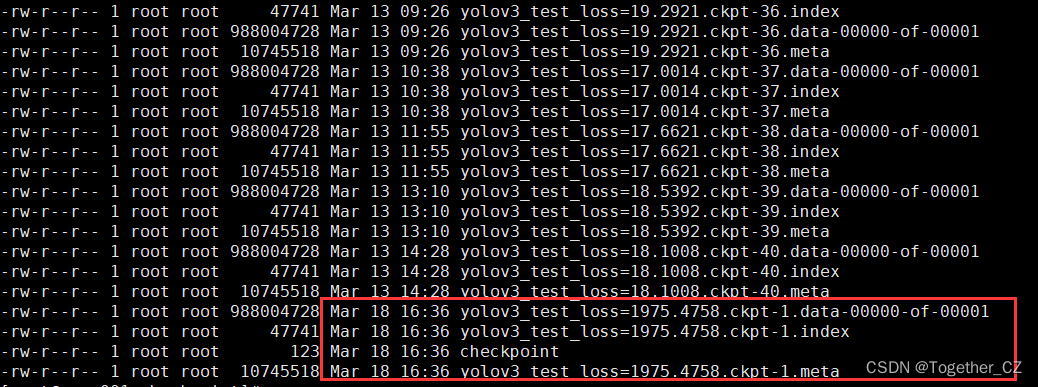
训练的时间还是挺长的,主要模型本身参数里较大。
后面有时间再详细看下内部原理吧。



















 7881
7881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











